📝 Paper Summary
RAG Evaluation
Hallucination Suppression
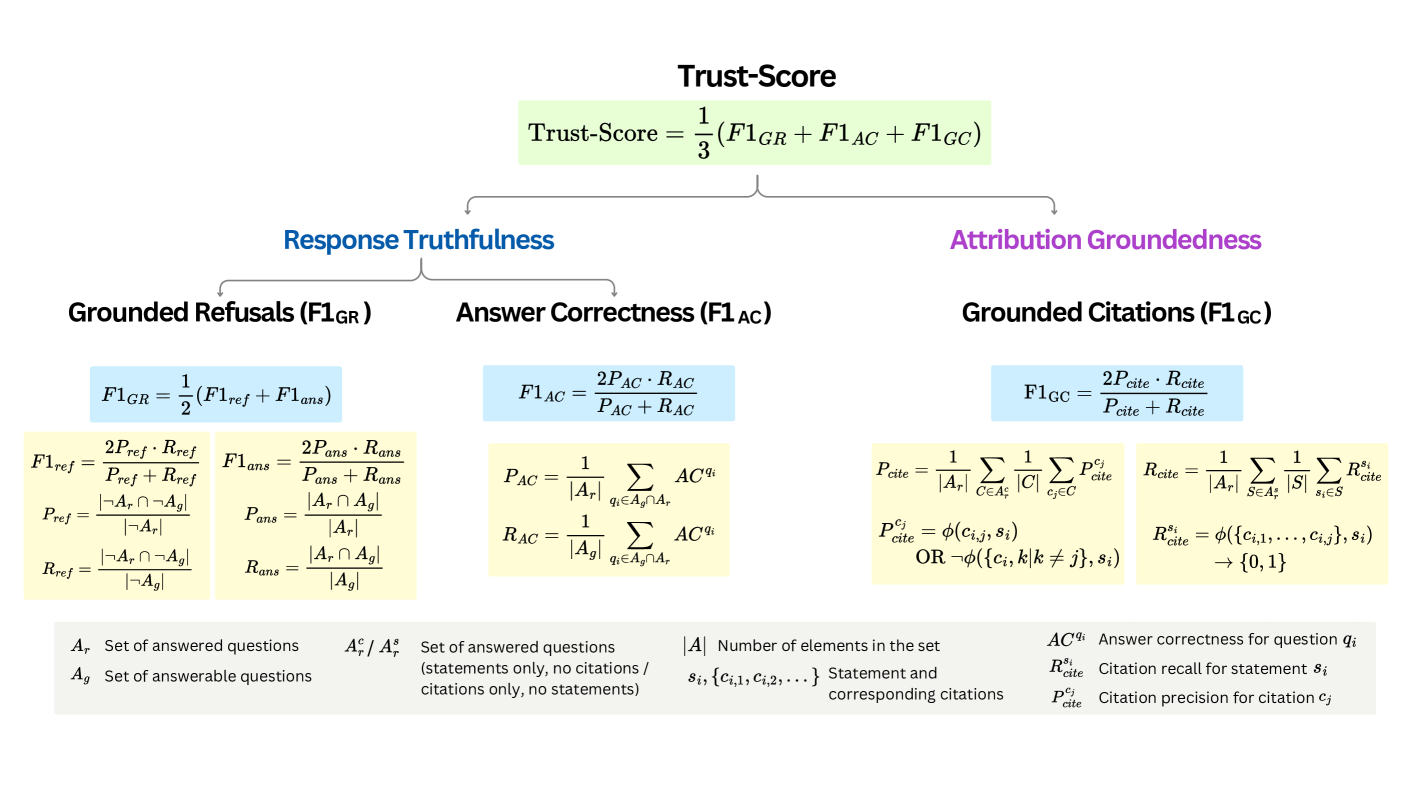
The paper introduces Trust-Score, a metric decoupling LLM performance from retrieval quality to measure true groundedness, and Trust-Align, a preference optimization method that significantly reduces hallucinations and improves refusal behavior.
Core Problem
Current RAG evaluations conflate retrieval quality with LLM generation quality and often reward models for answering correctly using parametric knowledge rather than retrieved documents.
Why it matters:
- Reliable RAG systems must base answers solely on retrieved documents to avoid hallucinations, yet current metrics fail to distinguish between document-grounded answers and lucky guesses based on pre-training data.
- Existing prompting methods (like in-context learning) make models overly sensitive, leading to either exaggerated refusals or excessive responsiveness, failing to balance the two.
Concrete Example:
A model might correctly answer a question about a specific event using its internal training data even if the retrieved documents are irrelevant. Standard metrics (like RAGAS) would score this highly, masking the fact that the model hallucinated the connection to the provided documents and failed the core RAG task of grounding.
Key Novelty
Trust-Score Metric and Trust-Align Framework
- Trust-Score: A composite metric that specifically isolates the LLM's ability to ground answers in documents by measuring correct refusals (when documents are irrelevant), answer correctness limited by document content, and citation accuracy.
- Trust-Align: An alignment framework using Direct Preference Optimization (DPO) on a custom dataset of 19K samples that explicitly pairs positive (grounded) responses against negative ones containing specific error types like over-responsiveness or bad citations.
Architecture
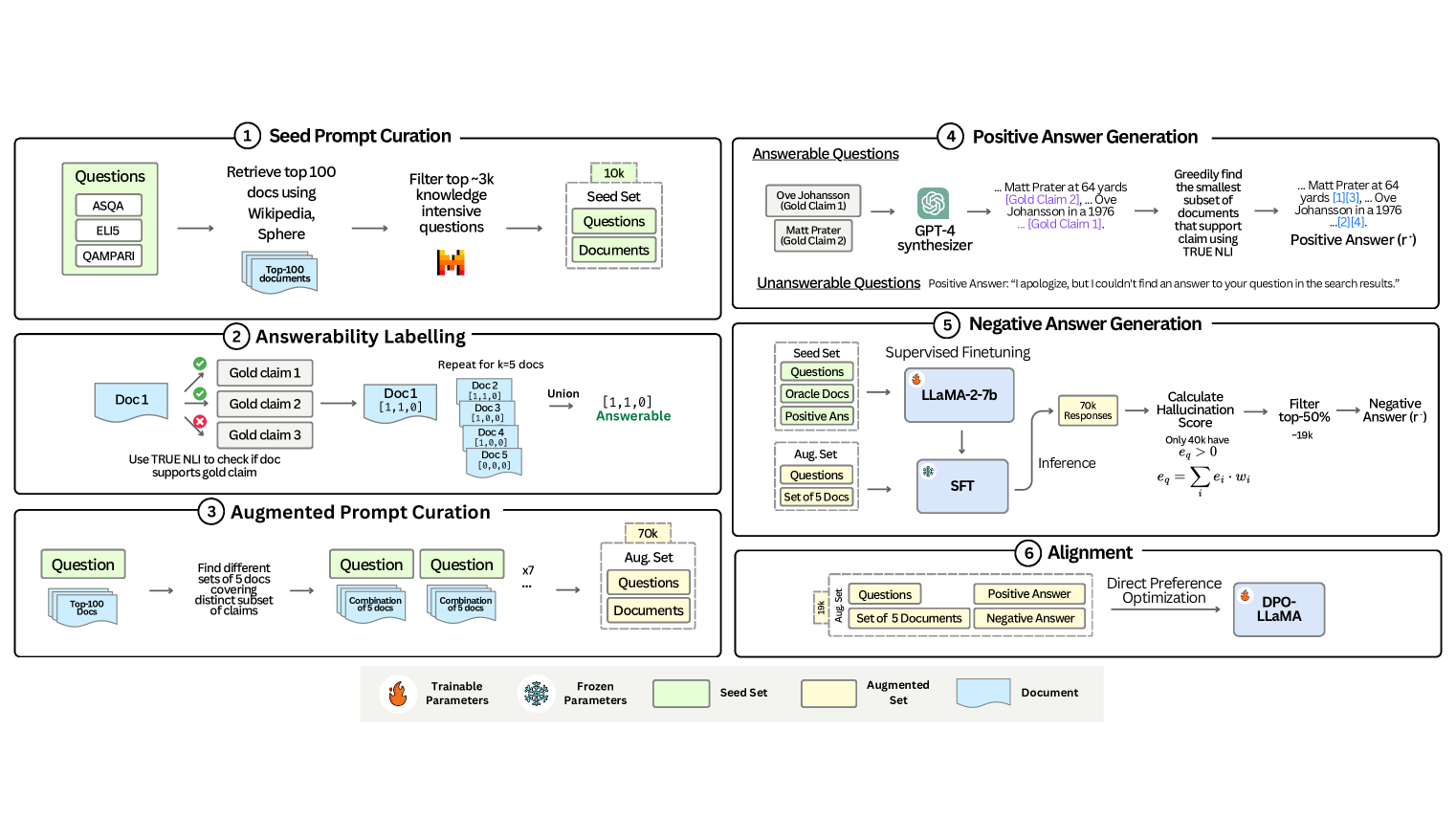
The Trust-Align pipeline involving dataset creation and DPO alignment.
Evaluation Highlights
- +12.56 Trust-Score improvement on ASQA for LLaMA-3-8b using Trust-Align compared to the FRONT baseline.
- +47.95% improvement in Correct Refusal rate on QAMPARI for LLaMA-3-8b using Trust-Align compared to FRONT.
- +38.35% improvement in Citation Groundedness on QAMPARI for LLaMA-3-8b using Trust-Align compared to FRONT.
Breakthrough Assessment
8/10
Significant contribution in decoupling LLM evaluation from retriever performance. The proposed alignment method shows massive gains in refusal and citation quality across multiple benchmarks.