📝 Paper Summary
Modularized RAG pipeline
DMQR-RAG improves retrieval by using diverse rewriting strategies (extraction, expansion, keyword, general) and an adaptive selector that chooses the best strategy mix for each query.
Core Problem
Single-query rewriting lacks diversity, and existing multi-query methods often produce near-identical rewrites that fail to retrieve distinct relevant documents for complex queries.
Why it matters:
- User queries often contain noise or intent deviations that direct retrieval cannot handle effectively.
- Static knowledge in LLMs leads to hallucinations, requiring reliable external retrieval.
- Existing prompt-based rewriting methods are often limited to specific query types (e.g., multi-hop) and lack generalization for diverse real-world inputs.
Concrete Example:
For the query 'Where are the authors of the Transformer paper currently working?' (multi-hop) vs. 'What is the citation count for the Transformer paper?' (general), a fixed rewriting strategy might fail on one. DMQR-RAG adaptively selects different strategies for each.
Key Novelty
Information-based Diverse Multi-Query Rewriting (DMQR)
- Defines four distinct rewriting strategies based on information flow: General Denoising, Keyword Extraction, Pseudo-Answer Expansion (adding priors), and Core Content Extraction (reducing detail).
- Uses an adaptive selector (LLM-based) to dynamically choose which of these strategies to apply for a given query, minimizing noise while maximizing retrieval coverage.
Architecture
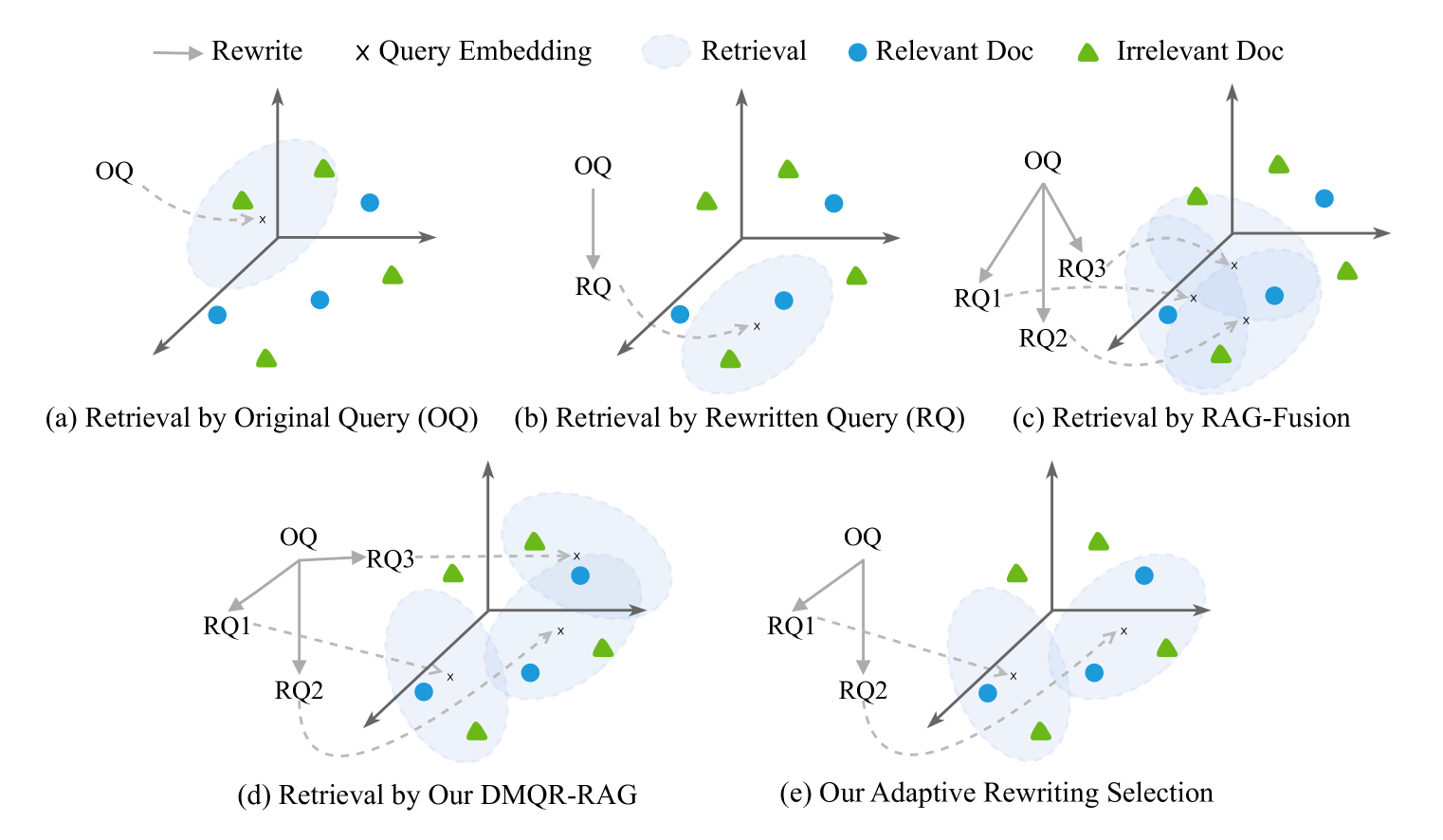
Comparison of Traditional RAG, Query Rewriting, and DMQR-RAG workflows.
Evaluation Highlights
- Achieves higher recall and retrieval performance compared to RAG-Fusion and single-query baselines.
- Adaptive selection reduces the number of queries needed while maintaining or improving performance.
- Validates effectiveness across both academic benchmarks and industry settings.
Breakthrough Assessment
6/10
Offers a sensible, structured approach to query rewriting with adaptive selection. While effective, it relies on prompting existing LLMs rather than a fundamental architectural shift.