📝 Paper Summary
Modularized RAG pipeline
RAG Evaluation and Benchmarking
The authors introduce Ragnarök, a standardized open-source framework and battle arena for evaluating Retrieval-Augmented Generation systems, alongside a curated MS MARCO V2.1 dataset and new non-factoid topic sets for the TREC 2024 RAG Track.
Core Problem
Existing RAG systems are often proprietary, hard to reproduce, or lack standardized evaluation frameworks, while current datasets (like Wikipedia-based ones) are too small or contain excessive factoid queries that LLMs can memorize.
Why it matters:
- Lack of standardization hinders large-scale implementation and fair comparison of academic RAG research
- Current benchmarks often rely on short-form answers or limited corpora, failing to test the complexity required for real-world applications like Bing Search or Gemini
- Proprietary nature of industrial systems prevents the community from analyzing or building upon state-of-the-art baselines
Concrete Example:
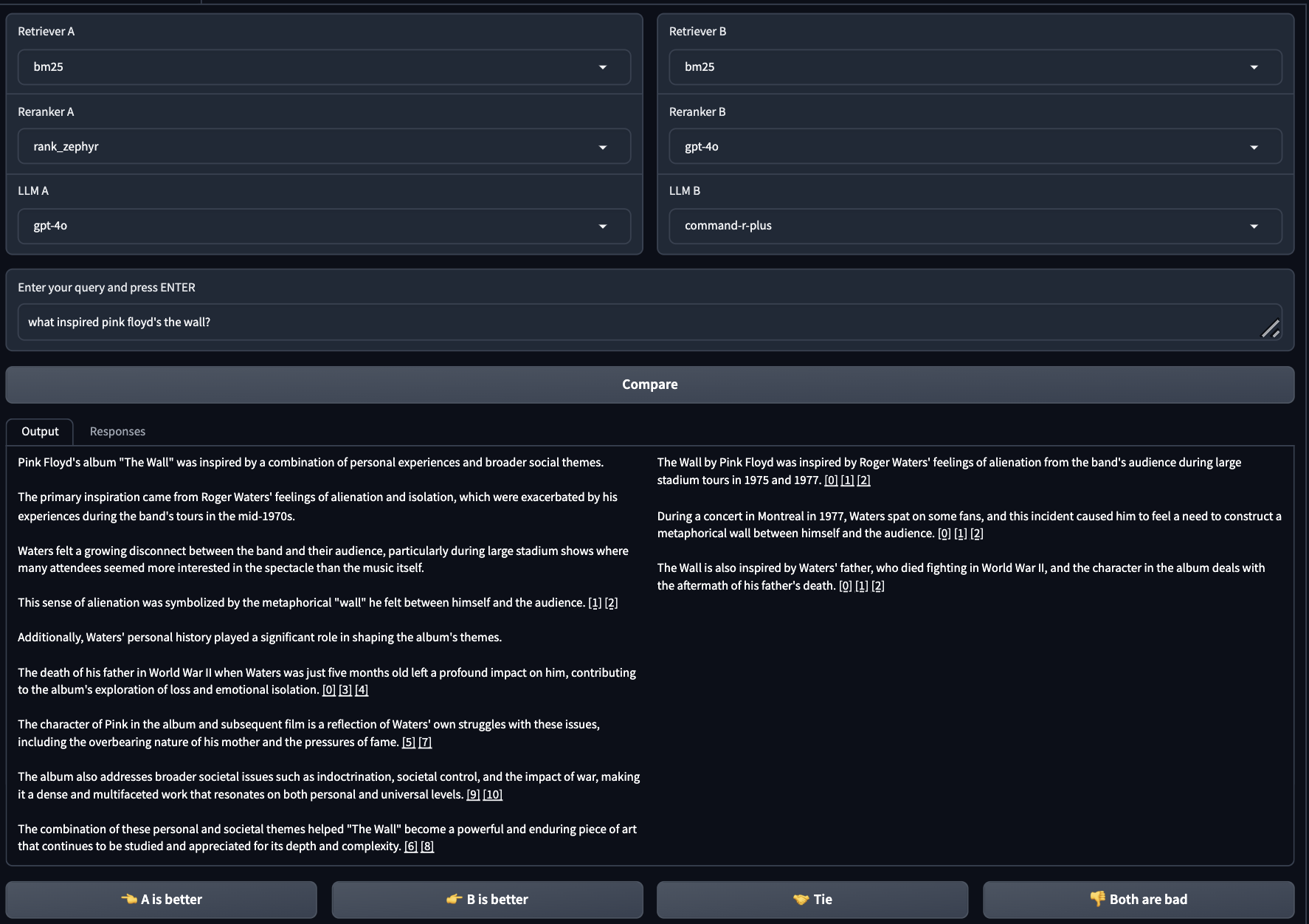
A user asks 'what inspired pink floyd's the wall?'. Without a standardized framework, comparing how a BM25+GPT-4o pipeline differs from a RankZephyr+Command R+ pipeline in citation quality and answer detail is difficult due to varying input/output formats and retrieval corpora.
Key Novelty
Ragnarök Framework & TREC 2024 RAG Track
- Establish a reusable, end-to-end RAG framework (Ragnarök) that standardizes Retrieval and Augmented Generation modules with sentence-level citations
- Release MS MARCO V2.1, a deduplicated and segmented version of the massive web corpus, designed specifically for RAG rather than just passage ranking
- Introduce a 'Chatbot Arena' style evaluation for RAG, where human annotators blind-test pairwise system outputs to determine win rates
Architecture
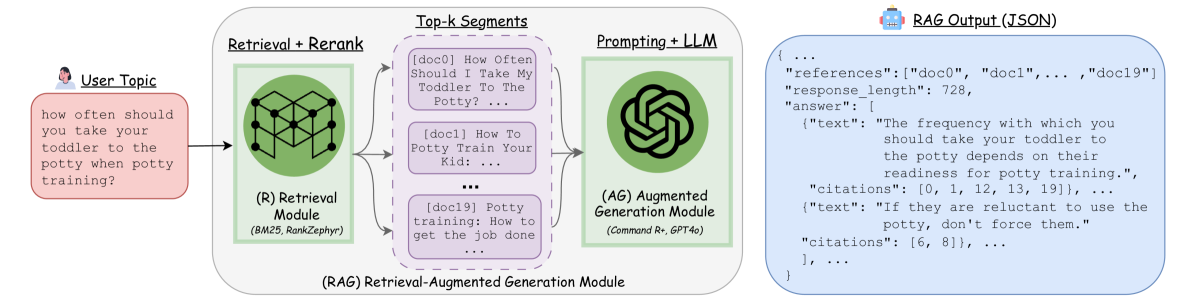
The high-level workflow of the Ragnarök framework.
Evaluation Highlights
- Reduced near-duplicates in the MS MARCO V2 document collection by 8.35% through Locality Sensitive Hashing (LSH)
- Created MS MARCO V2.1 Segment Collection containing over 113 million text segments using sliding window chunking
- Curated 120 'TREC-RAGgy' topics from past Deep Learning tracks, focusing on long-form answers where 65% of queries start with 'what' or 'how'
Breakthrough Assessment
9/10
Foundational work for the TREC 2024 RAG Track. While not a new model architecture per se, it establishes the standard infrastructure, datasets, and evaluation methodology for the field moving forward.