📝 Paper Summary
Modularized RAG pipeline
Answer generation
RobustRAG defends against retrieval corruption by processing each retrieved passage in isolation and then securely aggregating the responses using keyword or decoding-based techniques to achieve certifiable robustness.
Core Problem
RAG pipelines are vulnerable to retrieval corruption attacks where attackers inject malicious passages into the retrieval results to induce inaccurate or harmful responses.
Why it matters:
- Attackers can inject malicious websites or contaminate knowledge bases to manipulate search engine summaries and AI assistants
- Current RAG pipelines simply concatenate retrieved passages, allowing a single malicious document to corrupt the entire context window
- Without certifiable defenses, systems remain vulnerable to adaptive attacks even after patching specific vulnerabilities
Concrete Example:
In a 'PoisonedRAG' attack, an attacker injects a passage stating 'the highest mountain is Mount Fuji' into the knowledge base. When a user asks 'what is the name of the highest mountain?', the RAG system retrieves this malicious passage along with benign ones (e.g., about Everest) and generates the incorrect answer due to the corruption.
Key Novelty
Isolate-then-Aggregate Strategy for Certifiable Robustness
- Process each retrieved passage independently to generate isolated LLM responses, ensuring malicious passages cannot affect the processing of benign ones (isolation)
- Aggregate these isolated responses using secure algorithms (keyword voting or decoding-level probability aggregation) that are mathematically proven to resist a small number of malicious injections
Architecture
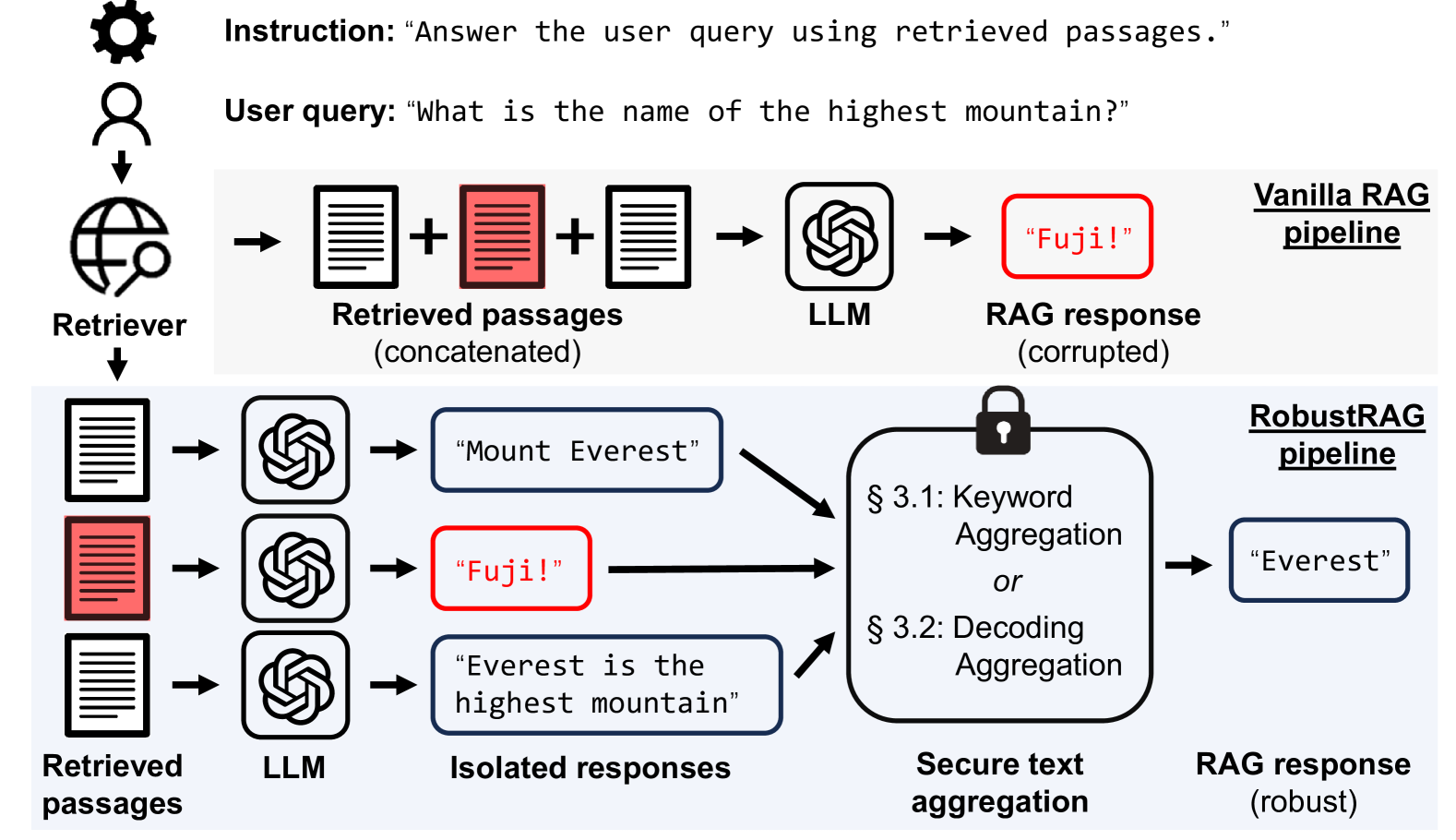
Overview of the RobustRAG framework comparing Standard RAG (vulnerable) with RobustRAG (robust)
Evaluation Highlights
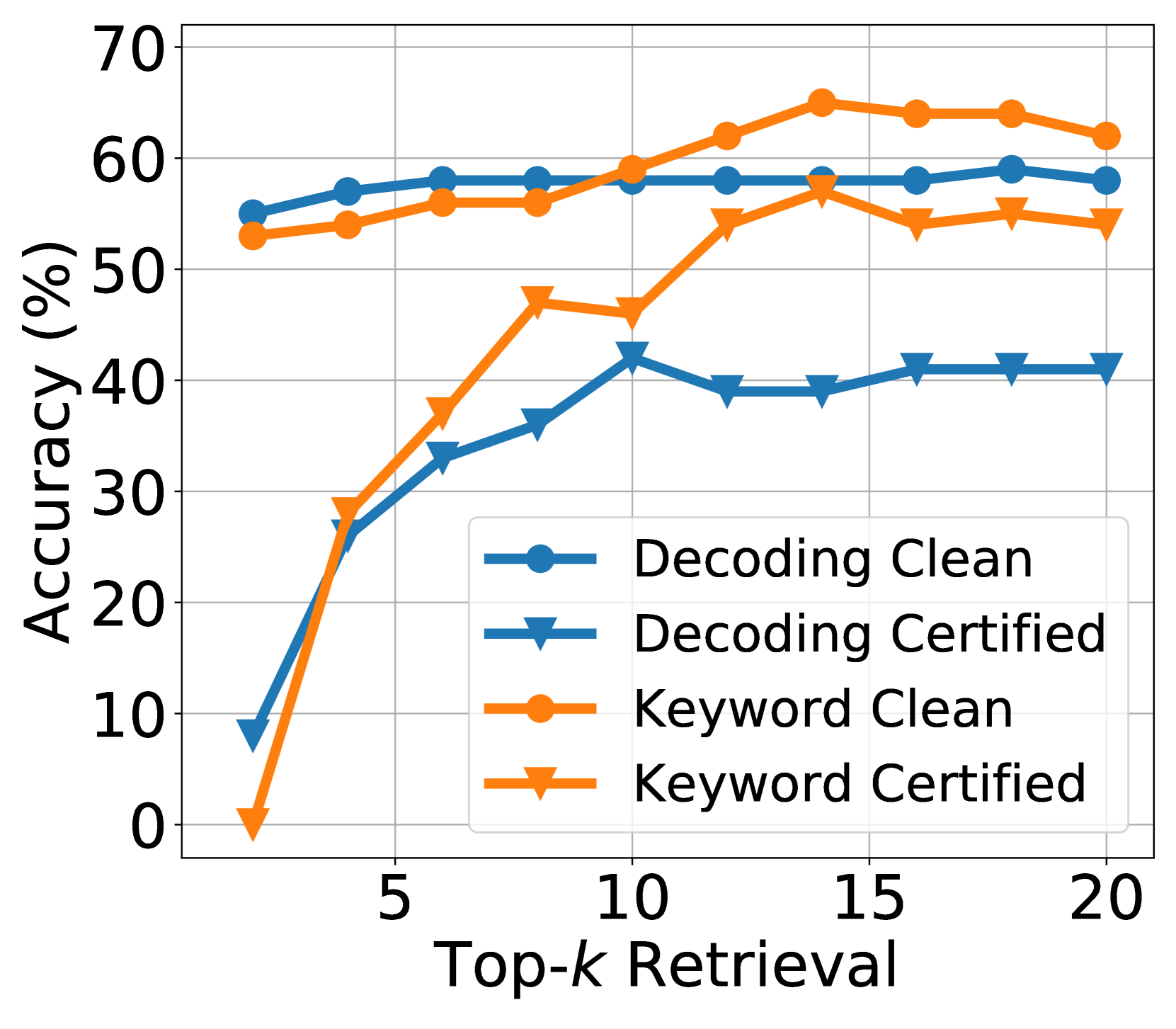
- Achieves significantly higher exact match accuracy than standard RAG on RealtimeQA under attack (e.g., ~60% vs ~10% with 5 malicious passages)
- Maintains performance comparable to benign RAG when no attack is present (clean accuracy), unlike baseline defenses that degrade clean performance
- Demonstrates generalizability across three datasets (RealtimeQA, NQ, Bio) and three LLMs (Mistral, Llama, GPT)
Breakthrough Assessment
8/10
Proposes the first defense framework against retrieval corruption with formally certifiable robustness guarantees, addressing a critical security vulnerability in RAG systems.