📝 Paper Summary
Modularized RAG pipeline
Evaluation methodology
DataMorgana generates highly diverse synthetic RAG benchmarks by combining customizable user personas and question categories to simulate realistic traffic patterns rather than relying on generic LLM generations.
Core Problem
Existing synthetic question generation methods produce monotonous benchmarks that lack the diversity of real user interactions, failing to reflect actual traffic patterns.
Why it matters:
- Indiscriminate LLM generation leads to benchmarks that do not cover the different ways end-users interact with RAG systems
- Lack of diversity in evaluation sets risks overfitting RAG solutions to specific question types while failing on others
- Real query logs are often unavailable for new or specialized domains, making high-quality synthetic data essential
Concrete Example:
Standard methods might repeatedly generate simple factoid questions from a document. In contrast, a real 'clinical researcher' user might ask for a comparison of trends, while a 'patient' might ask for basic symptom checking—a distinction missed by generic generators.
Key Novelty
Combinatorial Category-Driven Generation
- Defines mutually exclusive categories for both 'users' (e.g., expert, novice) and 'questions' (e.g., factoid, reasoning) via natural language descriptions
- systematically samples combinations of these categories to prompt the LLM, enforcing diversity through explicit constraints rather than random sampling
- Allows non-technical users to configure distribution probabilities for each category to match expected real-world traffic
Architecture
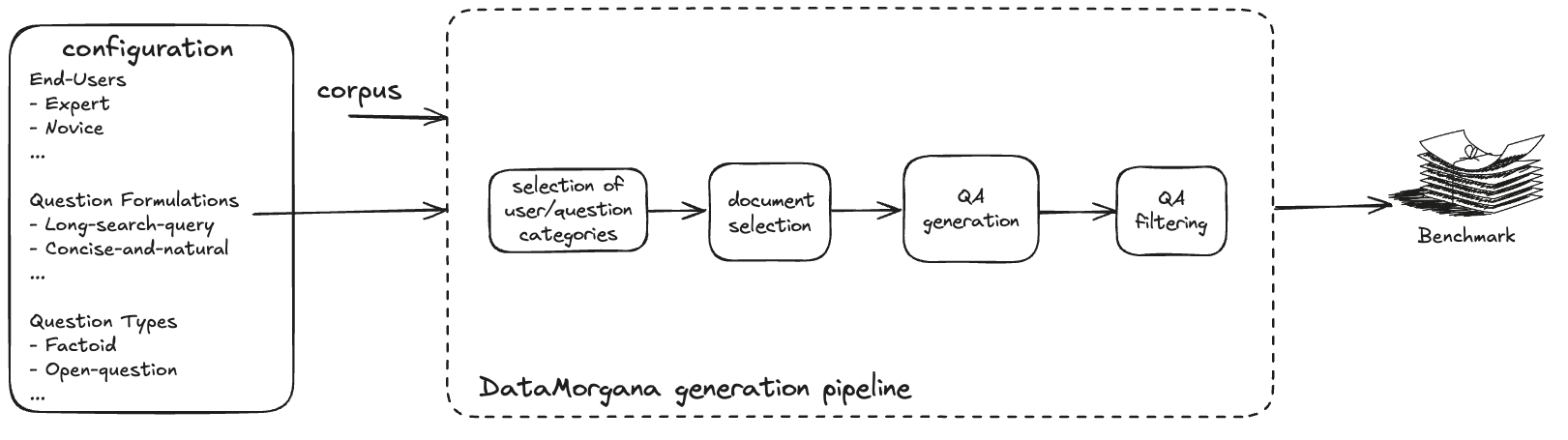
The generation workflow of DataMorgana
Evaluation Highlights
- Produces significantly higher lexical, syntactic, and semantic diversity compared to Vanilla, Know Your RAG, and DeepEval methods across multiple metrics
- Demonstrates effectiveness on both domain-specific (CORD-19) and general-knowledge (Wikipedia) corpora
- Achieves high fidelity in manual validation, with near-perfect relevance and text quality for generated questions
Breakthrough Assessment
7/10
Strong methodological contribution for evaluation. While not a new model architecture, it addresses a critical gap in RAG evaluation (benchmark diversity) with a flexible, user-centric approach.