📝 Paper Summary
Explainable Autonomous Driving
Multi-Modal Large Language Models (MLLMs)
RAG-Driver leverages a retrieval-augmented multi-modal large language model to provide driving actions, explanations, and justifications by grounding decisions in retrieved expert demonstrations without retraining.
Core Problem
End-to-end autonomous driving systems lack transparency, and existing MLLM-based explainers struggle with generalization to unseen environments due to data scarcity and catastrophic forgetting during fine-tuning.
Why it matters:
- Black-box driving decisions erode user trust; explanations are critical for transparency and acceptance in safety-critical autonomous systems
- Fine-tuning MLLMs for new driving domains is prohibitively expensive and often degrades performance on previous tasks (catastrophic forgetting)
- Annotating high-quality driving explanation data for every new environment is costly and unscalable
Concrete Example:
When a driving agent encounters a novel environment (e.g., London streets) after training only on US data (BDD-X), standard models may fail to explain why they stopped. RAG-Driver retrieves a similar 'stopping at a crosswalk' example from memory to generate a correct justification without parameter updates.
Key Novelty
Retrieval-Augmented In-Context Learning (RA-ICL) for Driving
- Retrieves relevant expert driving demonstrations (video + text + control signals) from a memory bank based on a hybrid similarity metric (visual + textual)
- Prefixes these retrieved demonstrations to the current query as in-context examples, enabling the MLLM to reason by analogy without updating weights
- Aligns numerical control signals with natural language explanations within the same generation pass, grounding the physics of driving in semantic understanding
Architecture
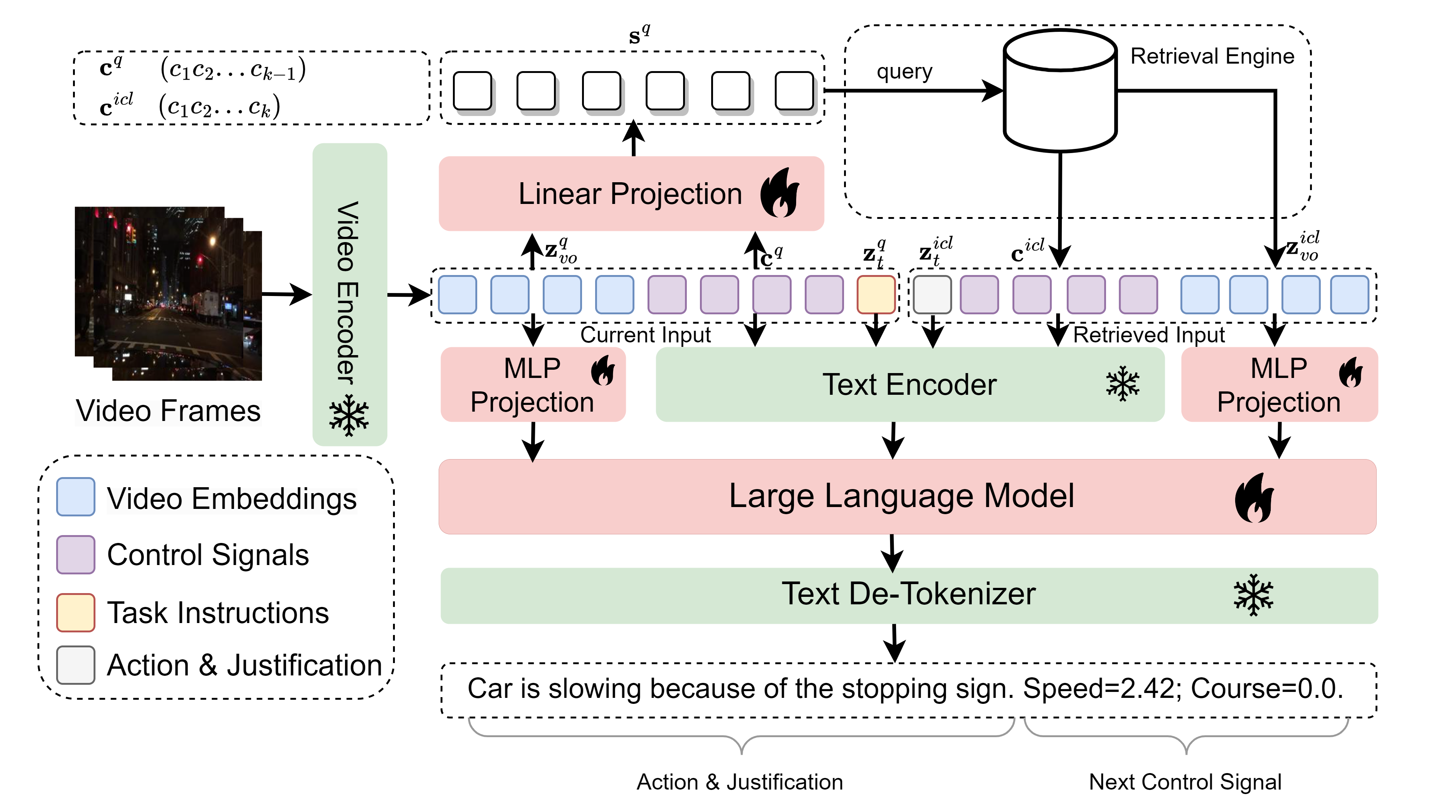
Overview of RAG-Driver framework illustrating the retrieval process and generation pipeline.
Evaluation Highlights
- Achieves state-of-the-art performance on the standard BDD-X benchmark for action explanation and justification
- Demonstrates zero-shot generalization to the unseen Spoken-London dataset, outperforming baselines without any fine-tuning
- Retrieval mechanism significantly boosts control signal prediction accuracy compared to non-retrieval baselines
Breakthrough Assessment
7/10
Strong application of RAG to the specific domain of explainable driving, addressing key generalization issues. While the architectural components are standard (LLaVA-style), the integration and zero-shot results are impactful.
