📝 Paper Summary
Agentic RAG pipeline
Iterative Retrieval
Auto-RAG fine-tunes LLMs on autonomously synthesized reasoning data to let them dynamically plan when and what to retrieve in a multi-turn dialogue with a retriever.
Core Problem
Existing iterative retrieval methods rely on rigid few-shot prompts or manual rules, which are computationally expensive and fail to fully leverage LLMs' reasoning capabilities to determine optimal retrieval timing and content.
Why it matters:
- Complex queries often require multiple retrieval steps, but retrieving too much introduces noise while retrieving too little causes hallucinations
- Current methods waste inference compute by retrieving at fixed intervals or using static rules rather than reasoning about actual information needs
- Reliance on few-shot prompting limits the diversity of query formulation and increases the length of the input context, slowing down inference
Concrete Example:
In a multi-hop question like 'Who represents the district where the city of X is located?', a standard RAG might just search for 'City X'. Auto-RAG reasons: 'First, I need to find which district City X is in. Query: [district of City X]. *Retrieves District Y*. Now I need the representative of District Y. Query: [representative of District Y].'
Key Novelty
Autonomous Instruction Synthesis for Iterative Retrieval
- Treats retrieval as a multi-turn conversation where the LLM is trained to output 'thoughts' (plans) and 'actions' (queries) before generating the final answer
- Synthesizes training data by prompting a strong teacher model to generate reasoning chains (Planning → Extraction → Inference) based on gold-standard answers
- Filters synthesized data to ensure the reasoning actually leads to the correct answer, creating a high-quality instruction tuning dataset for smaller models
Architecture

The iterative interaction loop between Auto-RAG and the Retriever.
Evaluation Highlights
- Auto-RAG achieves 52.61% F1 on 2WikiMultihopQA, outperforming the strong retrieval baseline ITER-RETGEN (43.91%) by +8.7% using Llama-3-8B-Instruct.
- On the single-hop PopQA benchmark, Auto-RAG reaches 60.03% Accuracy, surpassing Self-RAG (55.53%) by +4.5% despite using the same base model size.
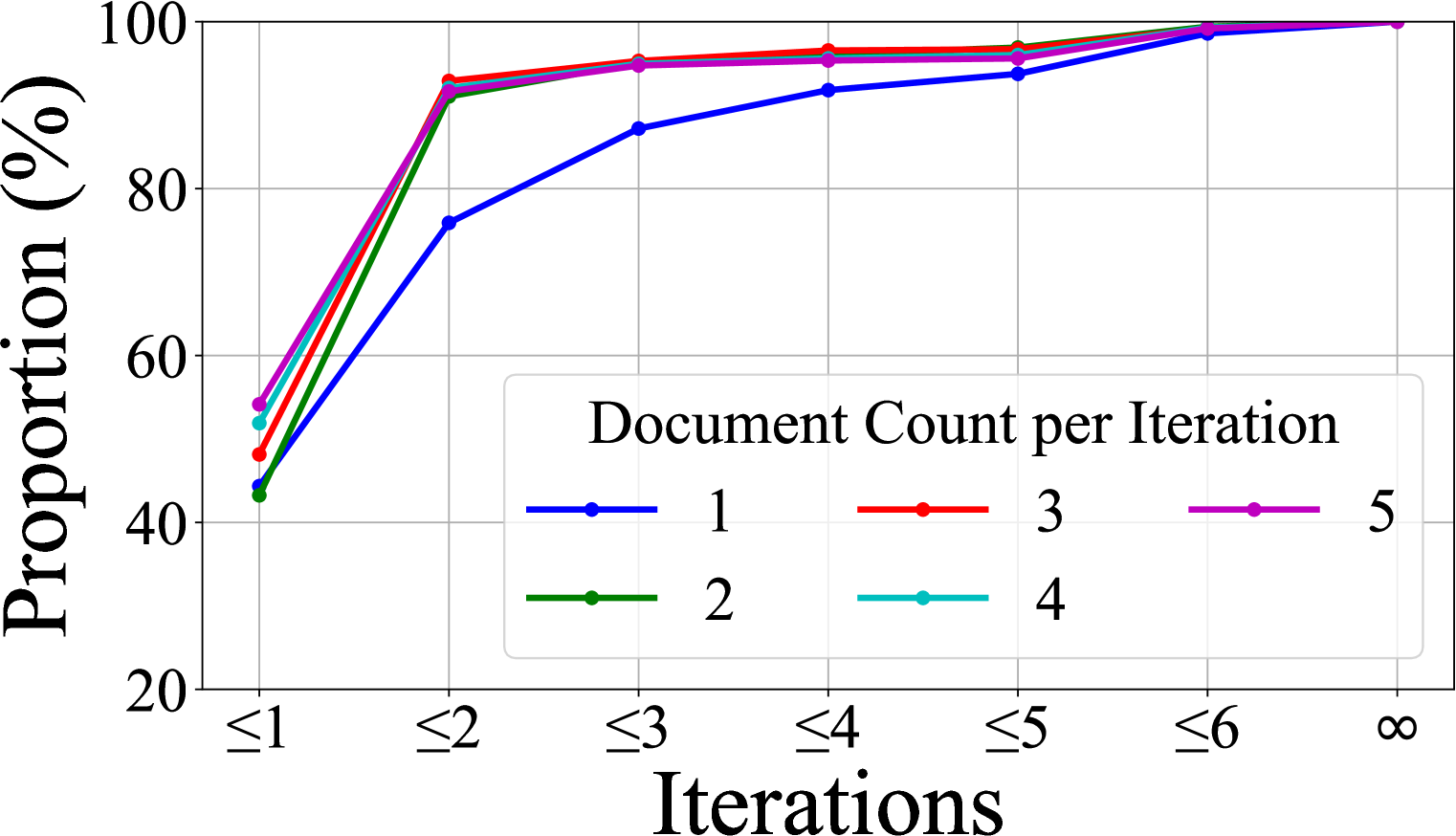
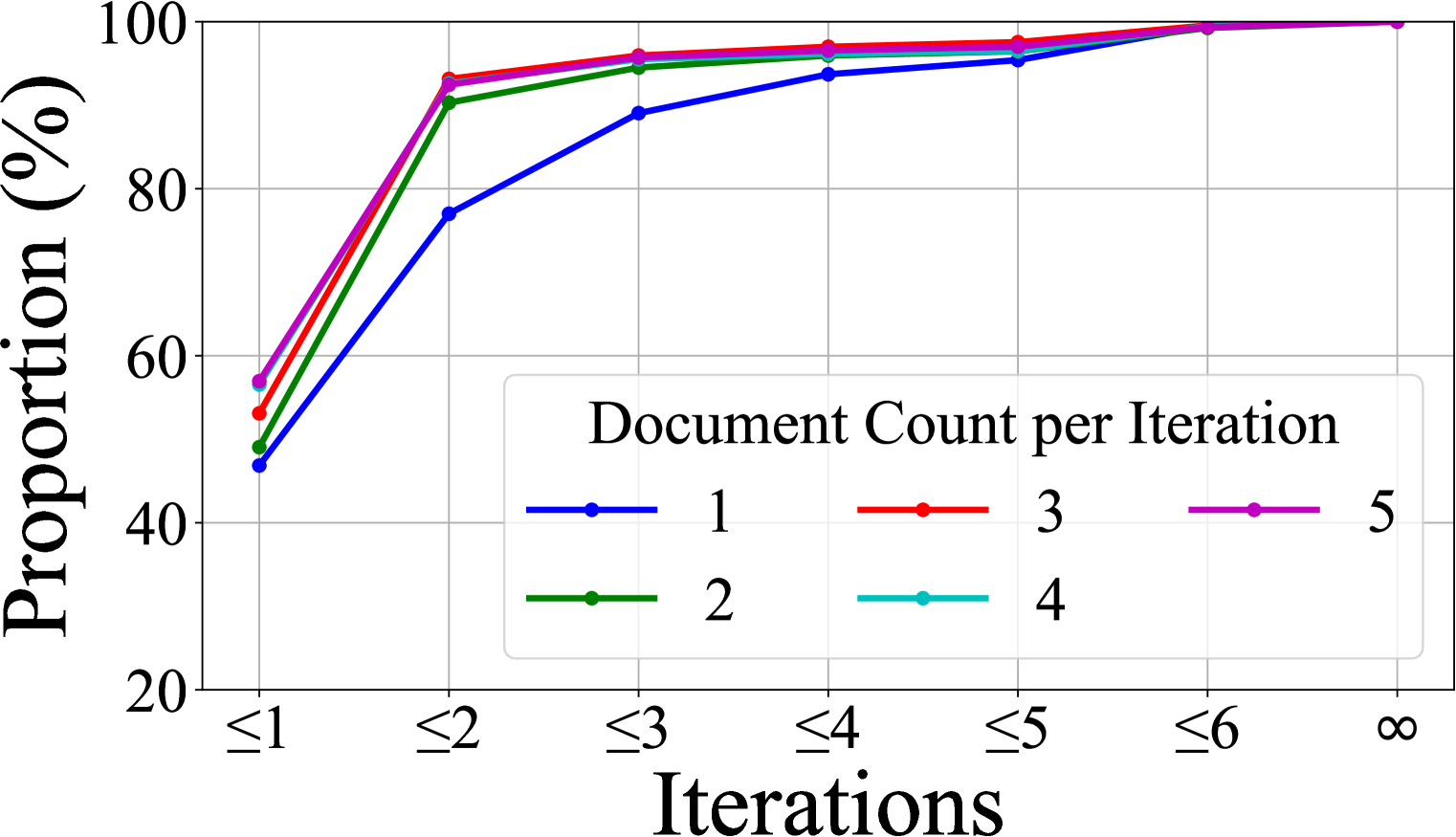
- Demonstrates efficient scaling: performance improves as the maximum number of allowed iterations increases from 1 to 3, but plateaus at 3-4, showing the model learns to stop autonomously.
Breakthrough Assessment
8/10
Strong methodological contribution in synthesizing training data for agentic retrieval without human annotation. Significant gains over established baselines like Self-RAG and FLARE.