📝 Paper Summary
LLM Routing
Model Selection
Efficient Inference
ProxRouter improves nonparametric query routing by using exponentially tilted, proximity-weighted aggregation of training examples to better estimate model performance for outlier queries without needing retraining.
Core Problem
Existing nonparametric routers (clustering or nearest-neighbor based) struggle to generalize to outlier queries—those unseen or rare in training data—leading to poor accuracy and cost estimates.
Why it matters:
- Using frontier models for every query is prohibitively expensive, but cheaper models fail on hard queries; efficient routing is essential for cost-effective AI platforms.
- Training sets for routers are costly to maintain and cannot cover all emerging use cases (e.g., new programming languages), causing performance drops when user queries drift from training distributions.
Concrete Example:
A router trained on general reasoning tasks might see a new query type, like a code snippet in a rare language. A standard clustering router assigns it to a generic 'math' cluster, mispredicting difficulty. ProxRouter weighs closer neighbors higher, correctly routing it to a code-specialized model.
Key Novelty
Proximity-Weighted Aggregation with Bias-Variance Control
- Generalizes standard clustering (K-Means) and nearest-neighbor (kNN) routers into a unified probabilistic framework where estimates are weighted averages of reference points.
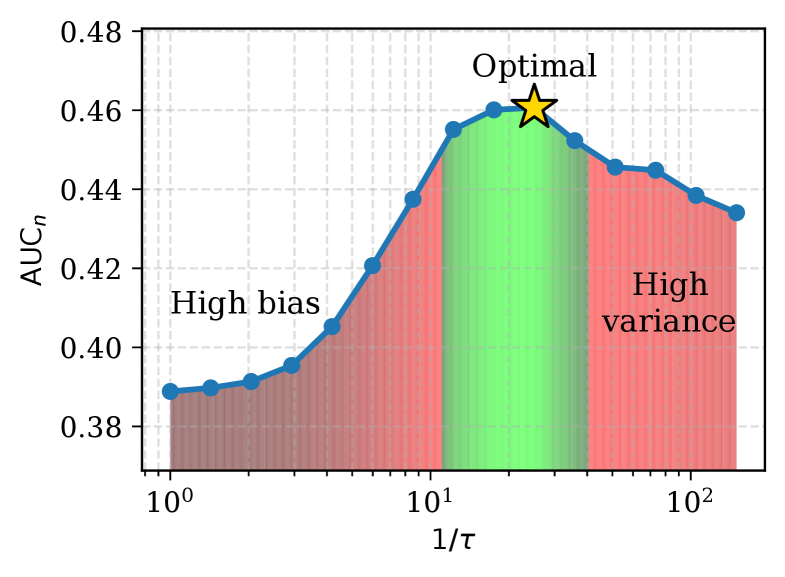
- Applies an 'exponential tilt' to these weights: reference points (clusters or neighbors) closer to the test query get exponentially higher influence, reducing bias for outliers while maintaining stability for inliers.
Architecture
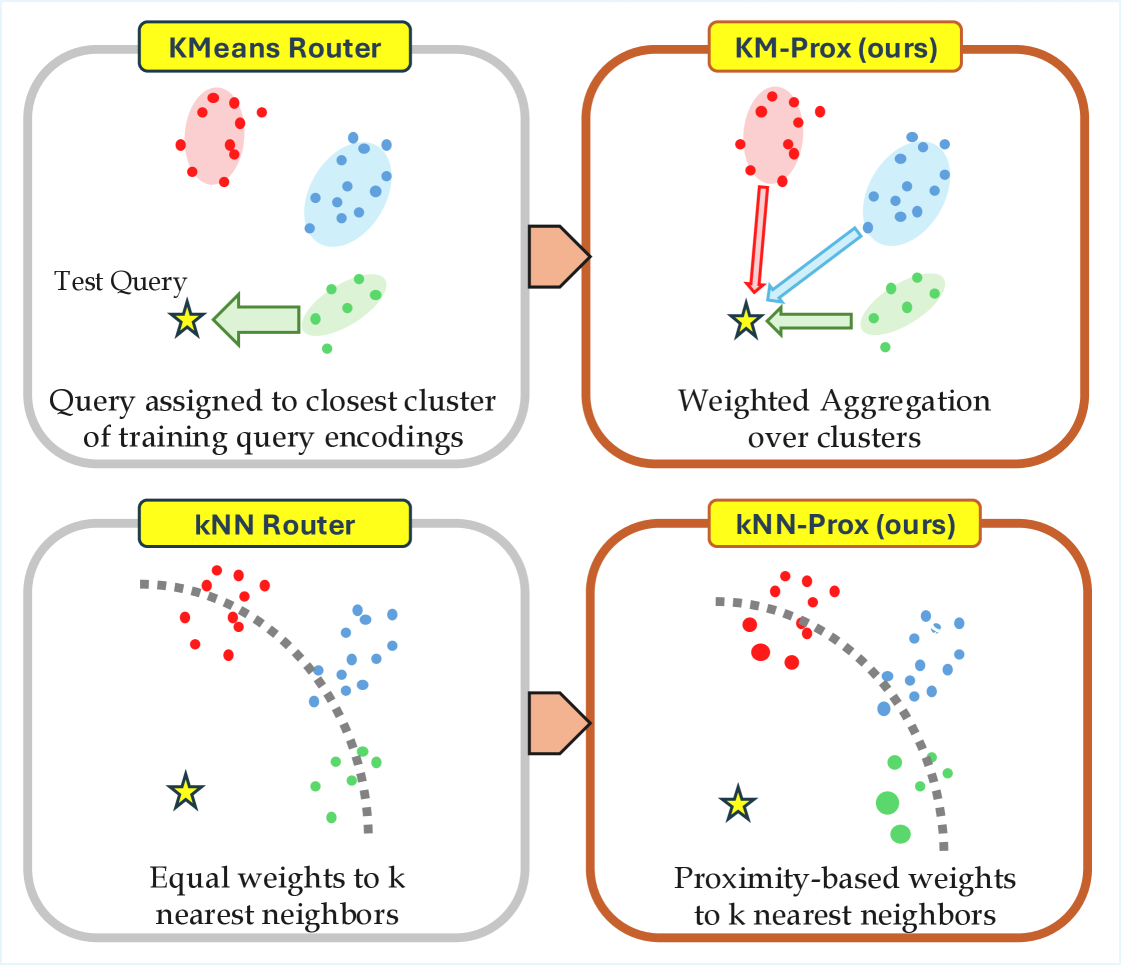
Conceptual illustration of Proximity-Weighted Aggregation vs. Hard Assignment
Evaluation Highlights
- +8.1% improvement in Area Under the Curve (AUC) for the nearest-neighbor setting (38.5% to 46.6%) on outlier math tasks (GSM8k, SVAMP).
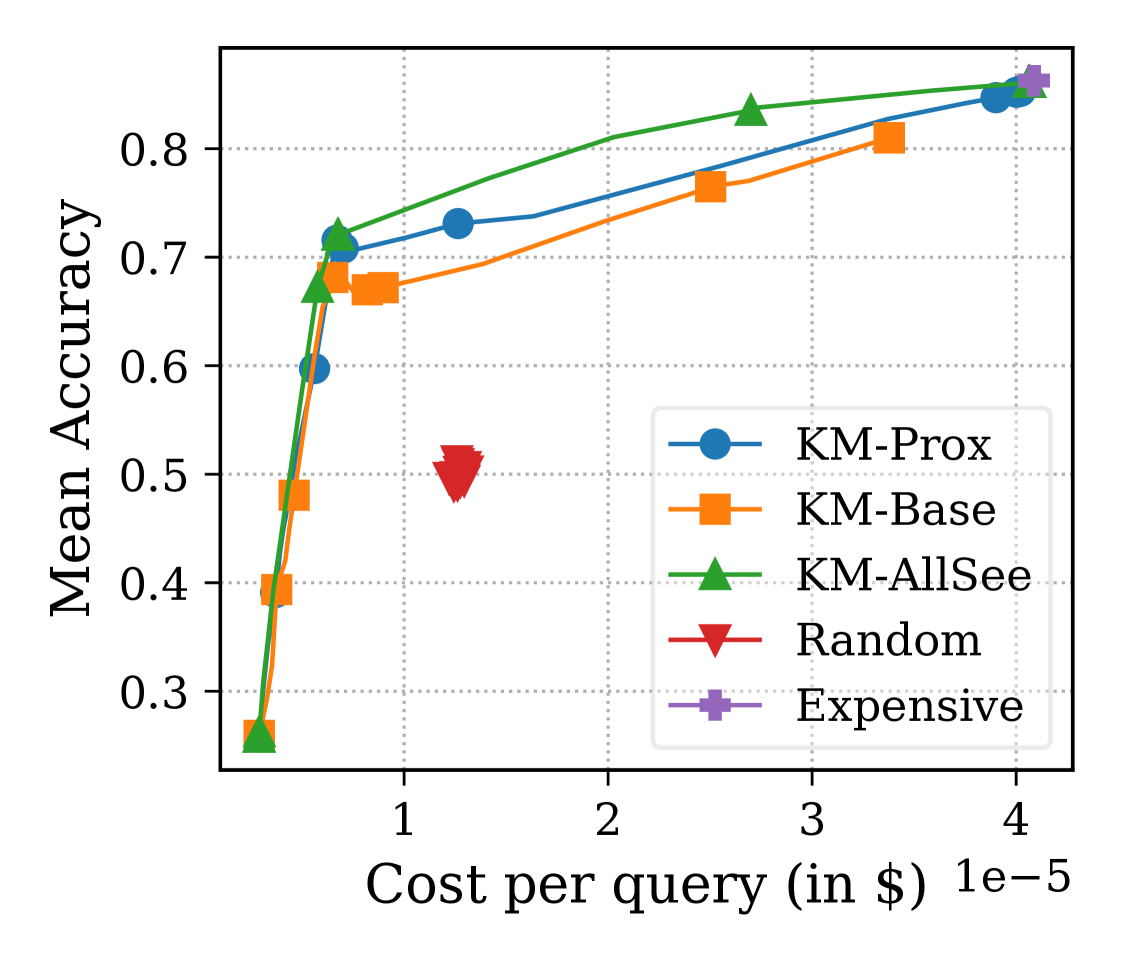
- Outperforms standard K-Means routing on Leave-Task-Out benchmarks (Hellaswag, MedQA), bringing performance closer to an 'AllSee' upper bound that trains on those tasks.
- Achieves higher accuracy at lower costs than baselines by effectively identifying when to use fine-tuned specialized models instead of generic large models.
Breakthrough Assessment
7/10
Provides a mathematically grounded unification of nonparametric routers and significantly improves robustness to outliers without retraining. A solid, practical contribution to efficient inference systems.