📝 Paper Summary
Specialized RAG pipeline
Biological Question Answering
BioRAG improves biological question answering by combining a domain-specific vector database of 22M papers with a hierarchical retrieval system and iterative self-evaluation to fetch data from specialized external tools.
Core Problem
General-purpose RAG systems fail to handle the complexity, rapid evolution, and scarcity of high-quality corpora in the biological domain.
Why it matters:
- Biological knowledge is complex and interdisciplinary, making standard retrieval methods prone to missing intricate relationships.
- Rapid discoveries render static model knowledge obsolete, requiring systems that can access up-to-date external databases.
- Existing fine-tuned biomedical LLMs (like BioBERT) are computationally expensive to update and often hallucinate when details are missing.
Concrete Example:
When asked 'What are the differences between innate immunity and adaptive immunity?', a standard RAG might return generic definitions. BioRAG identifies 'Adaptive Immunity' and 'Animals' as MeSH terms, filters the vector search to relevant sub-domains, and retrieves specific protein/gene interactions to build a precise answer.
Key Novelty
Hierarchy-Aware Iterative Biological RAG
- Constructs a massive local vector database from 22M high-quality PubMed abstracts using a CLIP-enhanced PubMedBERT embedding model.
- Uses a 'Self-evaluated Information Retriever' that first filters by Medical Subject Headings (MeSH) for precision, then uses vector similarity.
- Implements a recursive loop: if retrieved info is deemed insufficient by the LLM, it queries external biological hubs (Gene, dbSNP) or search engines before generating the final answer.
Architecture
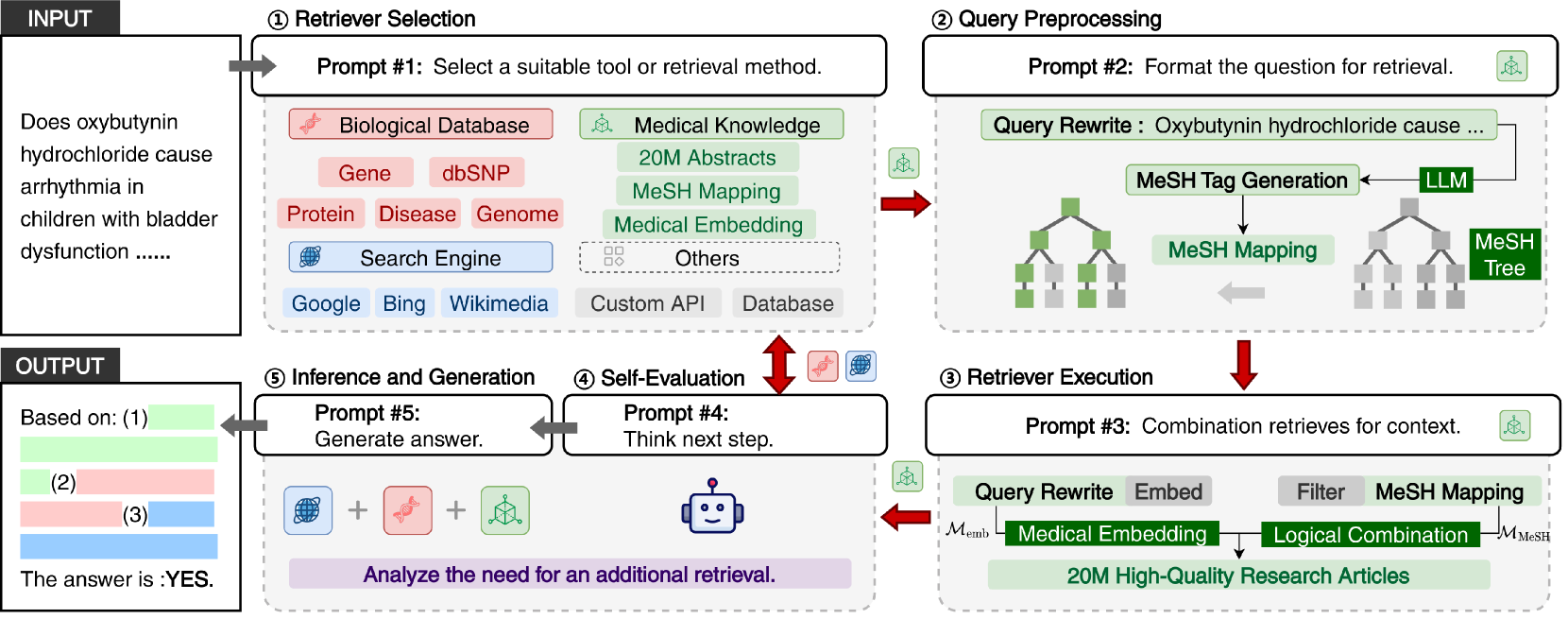
The complete BioRAG pipeline, illustrating the flow from User Question to Answer Generation.
Evaluation Highlights
- Outperforms GPT-4 by +6.8% on average across multiple biological QA datasets.
- Achieves highest accuracy on the MMLU-Medical genetics benchmark (83.33%) compared to baselines like PMC-Llama and GPT-3.5.
- Demonstrates +16% improvement over standard RAG implementations on the PubMedQA dataset.
Breakthrough Assessment
7/10
Strong engineering effort integrating domain-specific hierarchy (MeSH) and external tools into RAG. While the architectural components (iterative retrieval, tool use) are known, the specific application to a massive 22M-paper corpus constitutes a valuable domain contribution.