📊 Experiments & Results
Evaluation Setup
Zero-shot evaluation on common sense and knowledge benchmarks
Benchmarks:
- MMLU (General knowledge (STEM, Humanities, etc.))
- Core Tasks (Common-sense reasoning (ARC-easy, ARC-challenge, SciQ, PIQA, HellaSwag, Winogrande))
- CMMLU (Chinese-specific knowledge benchmark)
Metrics:
- Zero-shot Accuracy
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Initial experiments establish that without quality control, bilingual training degrades English performance. | ||||
| Core Tasks (English) | Accuracy | 56.4 | 53.4 | -3.0 |
| Controlled experiments show that matching data quality removes the bilingual performance gap. | ||||
| MMLU (English) | Accuracy | 26.5 | 26.3 | -0.2 |
| Filtering experiments demonstrate that the proposed SBERT-based filter improves performance over baselines. | ||||
| Core Tasks (French) | Accuracy | 46.0 | 52.0 | +6.0 |
| Average (Zero-shot) | Accuracy | Not reported in the paper | Not reported in the paper | +1.7% |
Experiment Figures
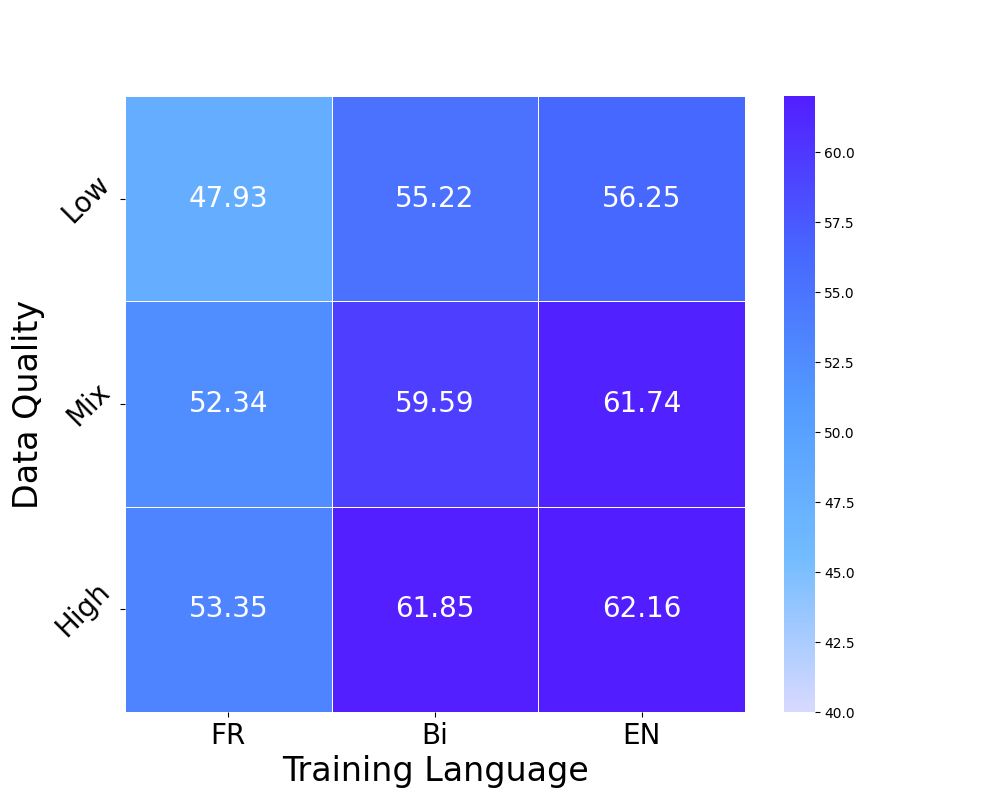
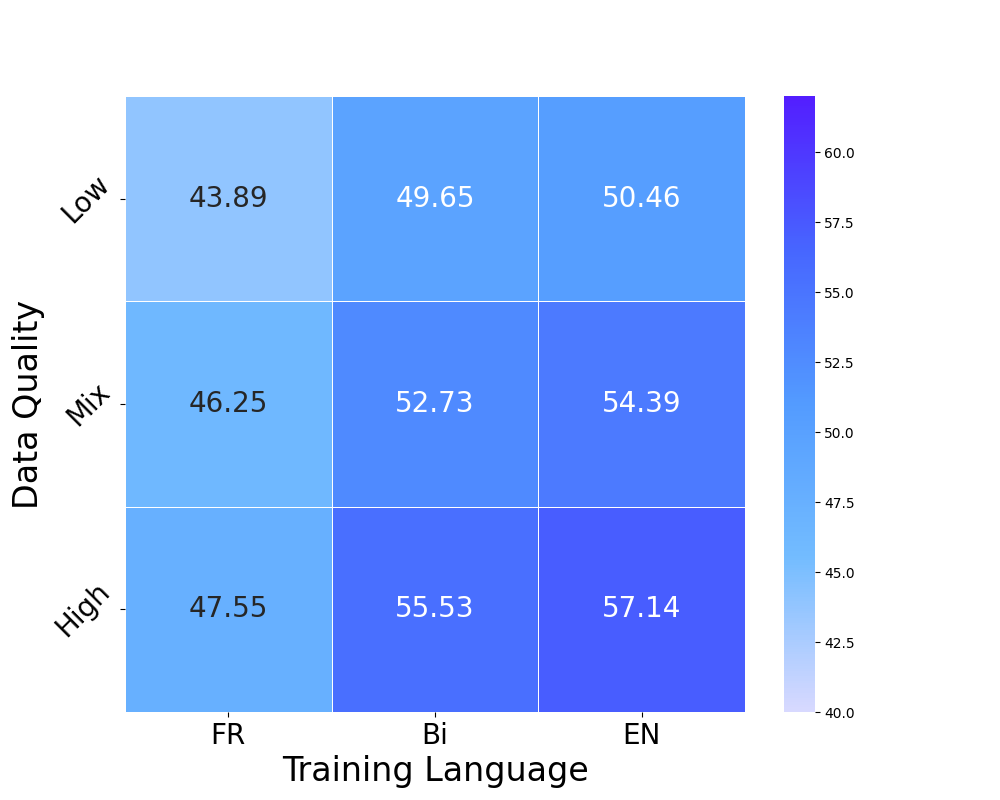
Heatmap of performance gaps when varying data quality (Low/High) and Language (Monolingual/Bilingual/Mixed)
Performance on Core benchmarks as filtering percentile increases (30%, 60%, 90%)
Main Takeaways
- The performance gap between monolingual and bilingual models is driven primarily by data quality discrepancies, not the inherent difficulty of learning multiple languages.
- High-quality English data standards can be successfully projected to other languages (French, German, Chinese) using multilingual embeddings to select better training data.
- Filtered native data (e.g., FineWeb2 filtered) can match the performance of highly curated translated data (TransWebEDU) on translated benchmarks.
- Ideally, data should be high-quality and culturally relevant; high-quality English translations alone are insufficient for culturally specific tasks (e.g., CMMLU).