📝 Paper Summary
Modularized RAG pipeline
Benchmarks and evaluation
AutoNuggetizer refactors the TREC nugget evaluation methodology using LLMs to automatically create and assign atomic facts (nuggets) for assessing RAG answer quality, achieving strong correlation with human judgments.
Core Problem
Evaluating long-form RAG responses is difficult and lacks standardization; manual evaluation is labor-intensive, while existing automatic metrics may not capture the recall of specific atomic facts.
Why it matters:
- The lack of standardized, scalable evaluations impedes progress in RAG and information access systems.
- Traditional manual nugget evaluation (e.g., TREC QA 2003) is accurate but too costly and slow for modern scale.
- Purely lexical metrics or simple LLM scoring often fail to diagnose specific missing information in complex answers.
Concrete Example:
For the query 'how did african rulers contribute to the triangle trade', a system must synthesize facts from multiple documents. A simple metric might miss that the answer omits a specific vital fact (e.g., 'rulers sold enslaved people for goods'), whereas nugget evaluation explicitly checks for the presence/absence of this atomic unit.
Key Novelty
AutoNuggetizer Framework
- Refactors the 2003 TREC QA 'nugget' methodology by replacing human assessors with LLMs (GPT-4o) for both creating atomic facts (nuggetization) and checking if answers contain them (assignment).
- Validates fully automatic RAG evaluation against high-quality human (NIST assessor) judgments from the TREC 2024 RAG Track, calibrating the trade-off between automation and human effort.
Architecture
The AutoNuggetizer workflow showing the two-step process of Nugget Creation and Nugget Assignment.
Evaluation Highlights
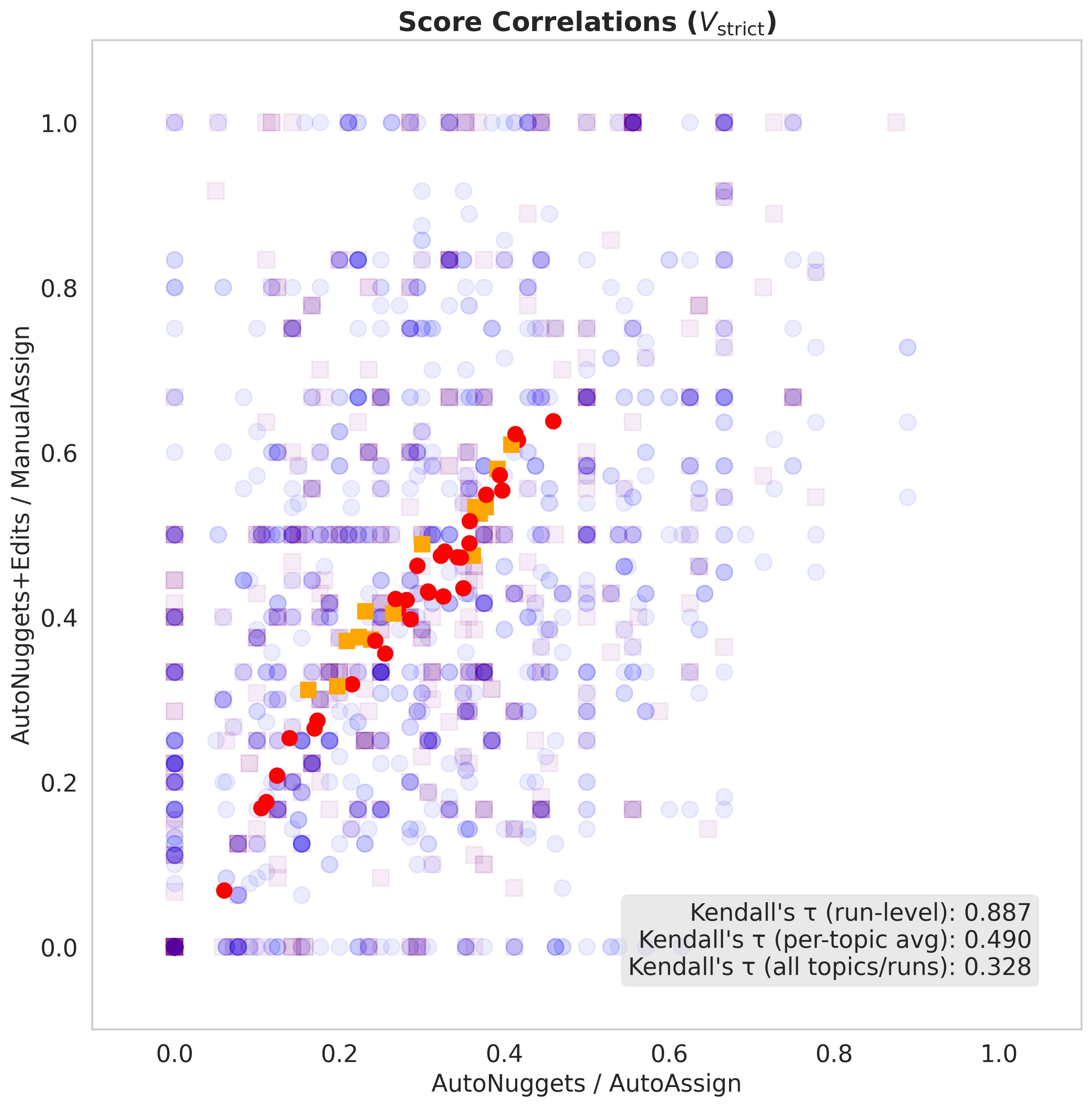
- Fully automatic nugget evaluation scores show strong run-level correlation with manual human evaluations.
- Automating only the nugget assignment step (while keeping manual nugget creation) yields even stronger agreement with fully manual baselines than fully automating both steps.
- LLM assessors are generally stricter than NIST human assessors when assigning nuggets to answers.
Breakthrough Assessment
7/10
While not a new architectural model, it provides a crucial validation of scalable, automated evaluation for RAG, grounded in rigorous TREC methodologies and human correlation.