📝 Paper Summary
Agentic RAG pipeline
Modularized RAG pipeline
MA-RAG is a training-free multi-agent framework that orchestrates specialized agents (Planner, Step Definer, Extractor, QA) via chain-of-thought prompting to solve complex retrieval tasks without fine-tuning.
Core Problem
Standard RAG systems treat retrieval and generation as isolated components, failing to resolve ambiguities and reasoning gaps in complex, multi-hop queries.
Why it matters:
- Existing methods struggle with vague queries or scattered evidence, leading to retrieval mismatch and hallucinations.
- End-to-end fine-tuning approaches are computationally expensive and lack interpretability in their intermediate reasoning steps.
- Naively appending retrieved documents often introduces noise and context overflow, degrading performance.
Concrete Example:
For a multi-hop question like 'What conference was the Vermont Catamounts men's soccer team's conference formerly known as...', standard RAG might just retrieve football documents or miss the historical context. MA-RAG decomposes this into structured sub-tasks: finding the team's conference affiliation, then finding that conference's former name.
Key Novelty
Modular Multi-Agent RAG (MA-RAG)
- Decomposes RAG into four distinct agent roles (Planner, Step Definer, Extractor, QA) that communicate via structured state updates.
- Uses an on-demand strategy where agents are invoked only when necessary based on the Planner's decomposition, rather than a fixed linear pipeline.
- Achieves state-of-the-art performance purely through chain-of-thought prompting and agent collaboration, requiring zero model fine-tuning.
Architecture
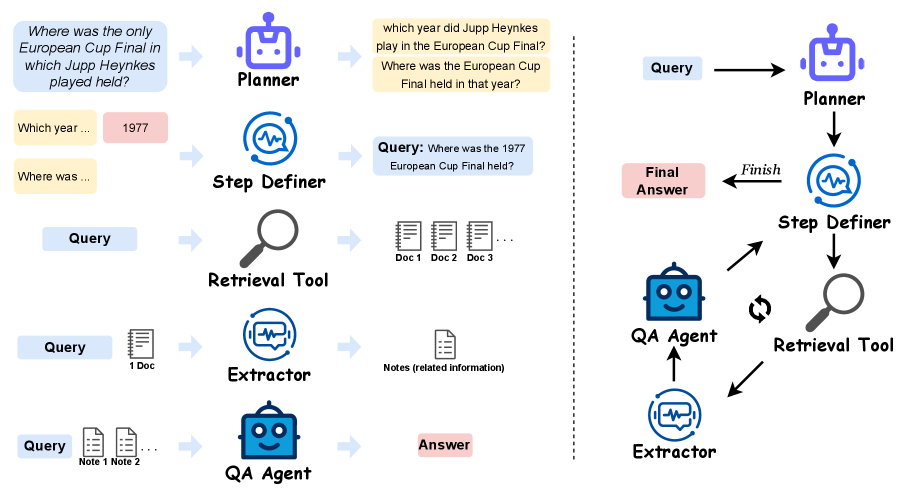
Overview of the MA-RAG framework, illustrating the interaction between the Planner, Step Definer, Retrieval Tool, Extractor, and QA Agent.
Evaluation Highlights
- Surpasses 70B-scale baselines (ChatQA-1.5, RankRAG) using only LLaMA3-8B on NQ (52.5 EM), HotpotQA (52.1 EM), and 2WikimQA (46.4 EM).
- Achieves 59.5 EM on Natural Questions with GPT-4o-mini, outperforming standard GPT-4 (40.3 EM) significantly.
- Generalizes to medical domain (MedMCQA) without fine-tuning, outperforming domain-specific Meditron-70B and PMC-Llama 13B.
Breakthrough Assessment
8/10
Strong evidence that modular, training-free agents can outperform fine-tuned RAG models. The high performance of small 8B models against larger baselines is particularly impressive.