📝 Paper Summary
Graph-based RAG pipeline
Benchmark
GraphRAG-Bench is a comprehensive benchmark that evaluates GraphRAG systems across varying levels of retrieval and reasoning difficulty using structured domain corpora to identify when graph structures provide measurable benefits over vanilla RAG.
Core Problem
Existing benchmarks for Retrieval-Augmented Generation (RAG) focus on simple fact retrieval from generic corpora, failing to evaluate the deep reasoning and hierarchical contextual understanding that GraphRAG is designed to solve.
Why it matters:
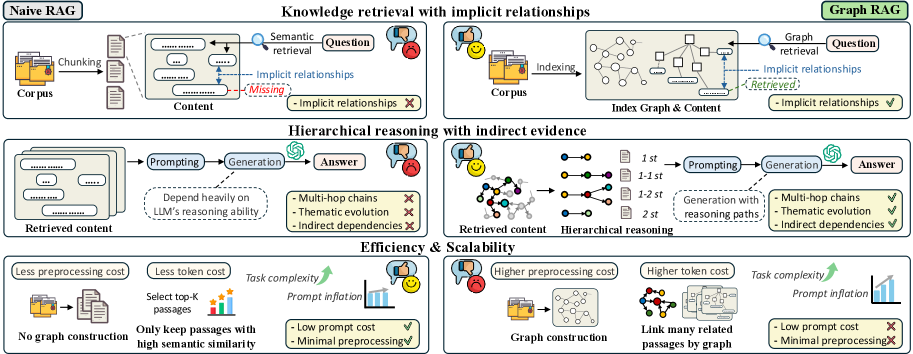
- GraphRAG conceptually promises better reasoning but often underperforms vanilla RAG in practice, yet current benchmarks cannot explain why due to lack of complex reasoning tasks
- Existing datasets (HotpotQA, MultiHopRAG) use loose, generic text (Wikipedia) that lacks the dense domain hierarchies required to test graph traversal capabilities
- Prior evaluations treat GraphRAG as a black box, measuring only final answer accuracy without assessing the quality of graph construction or intermediate retrieval steps
Concrete Example:
A typical benchmark question asks 'Who founded Company Kjaer Weis and where were they born?', which only requires retrieving two discrete facts. In contrast, explaining 'why Company Kjaer Weis failed in a specific market' requires synthesizing financial reports, competitor analysis, and supply chain disruptions—a task requiring the structural reasoning GraphRAG claims to offer but which existing benchmarks do not test.
Key Novelty
GraphRAG-Bench: A Multi-Level Reasoning Benchmark
- Designs tasks with progressive difficulty levels, ranging from simple fact retrieval to 'Contextual Summarize' and 'Creative Generation' that require global graph topology understanding
- Constructs corpora with varying information density: tightly structured medical guidelines (explicit hierarchies) and pre-20th-century novels (implicit, non-linear narratives) to test adaptability
- Implements a 'white-box' evaluation pipeline that assesses performance at three specific stages: graph construction quality, retrieval relevance, and final generation faithfulness
Architecture
Comparison of RAG vs. GraphRAG pipelines
Evaluation Highlights
- GraphRAG models frequently underperform vanilla RAG on real-world tasks (e.g., 13.4% lower accuracy on Natural Questions in prior studies)
- GraphRAG significantly increases latency (e.g., 2.3x higher latency on HotpotQA reported in prior studies), raising questions about cost-benefit trade-offs
- The benchmark introduces specific metrics like 'Average Clustering Coefficient' and 'Evidence Recall' to quantitatively measure graph quality and retrieval completeness beyond simple accuracy
Breakthrough Assessment
8/10
Provides a critical, much-needed standardization for the GraphRAG field. By moving beyond simple accuracy to stage-wise evaluation and hierarchical reasoning, it addresses the 'why is GraphRAG failing?' question effectively.