📝 Paper Summary
Modularized RAG pipeline
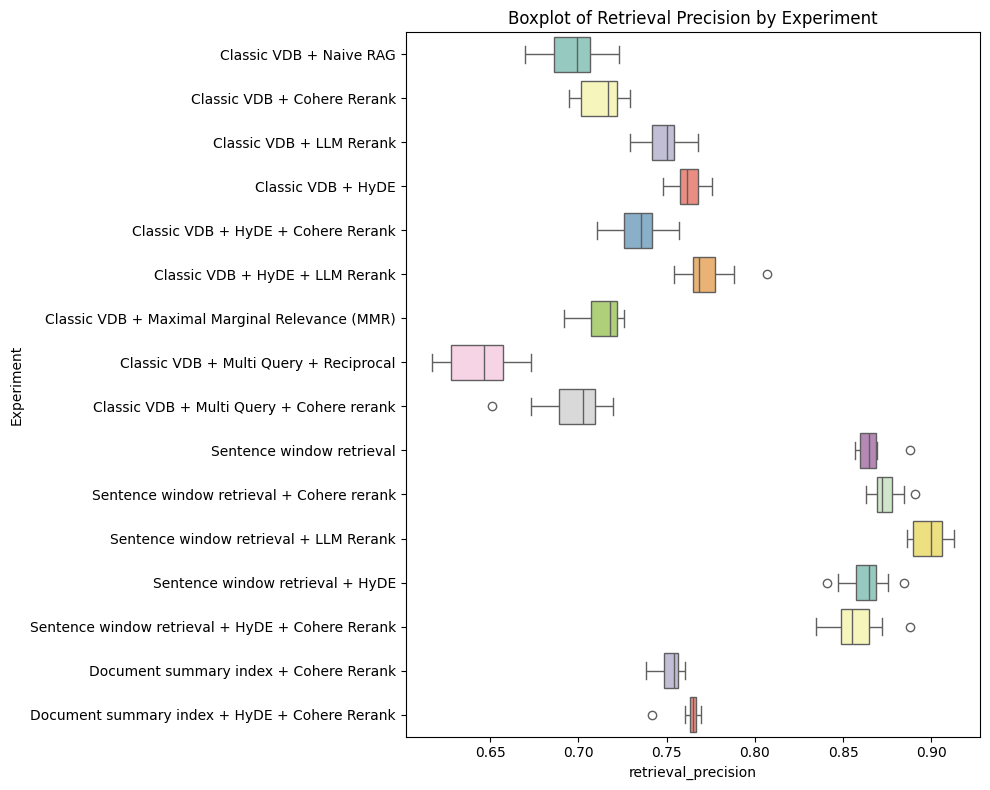
This study experimentally evaluates multiple advanced RAG techniques, finding that Sentence Window Retrieval and HyDE offer the best retrieval precision, while Maximal Marginal Relevance and Multi-query strategies often fail to outperform a naive baseline.
Core Problem
Current RAG literature focuses on systematic reviews or SOTA comparisons, lacking comprehensive experimental benchmarks that isolate the impact of specific retrieval techniques like HyDE, MMR, and reranking on precision and answer similarity.
Why it matters:
- Developers lack empirical guidance on which RAG components actually improve retrieval quality versus just adding complexity.
- Systematic comparisons are needed to understand trade-offs between retrieval precision (finding the right context) and answer similarity (generating the right text).
- Some popular techniques (like Multi-query) may degrade performance in specific setups, but this is rarely documented in broad reviews.
Concrete Example:
When a naive RAG system retrieves irrelevant chunks for a technical question, the LLM hallucinates an answer. The study tests if adding a reranker (like Cohere) or changing the chunking strategy (Sentence Window) fixes this, finding that Sentence Window improves precision significantly while Multi-query actually hurts it.
Key Novelty
Head-to-head empirical benchmarking of advanced RAG modules
- Systematically compares distinct RAG strategies (Naive, Sentence Window, HyDE, Multi-query, MMR, Reranking) on a controlled dataset of AI papers.
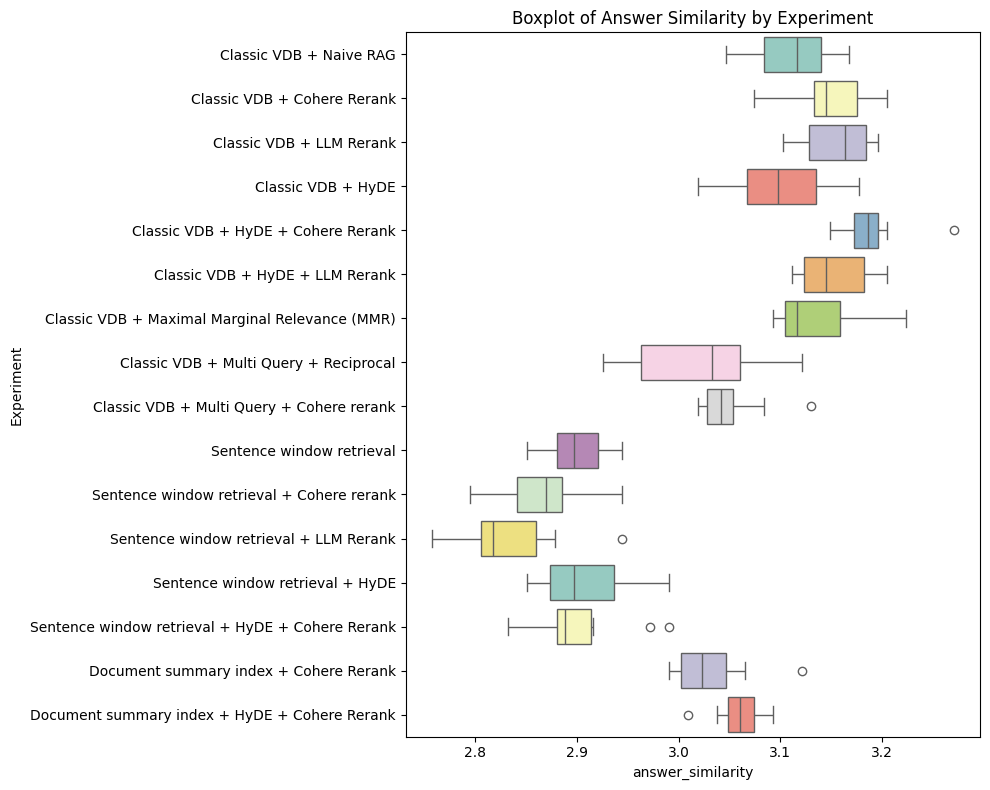
- Decouples evaluation into Retrieval Precision (did we get the right text?) and Answer Similarity (did we write the right answer?) to diagnose component-level failures.
- Demonstrates that 'advanced' techniques like Multi-query do not universally improve performance and can degrade precision compared to simpler baselines.
Architecture
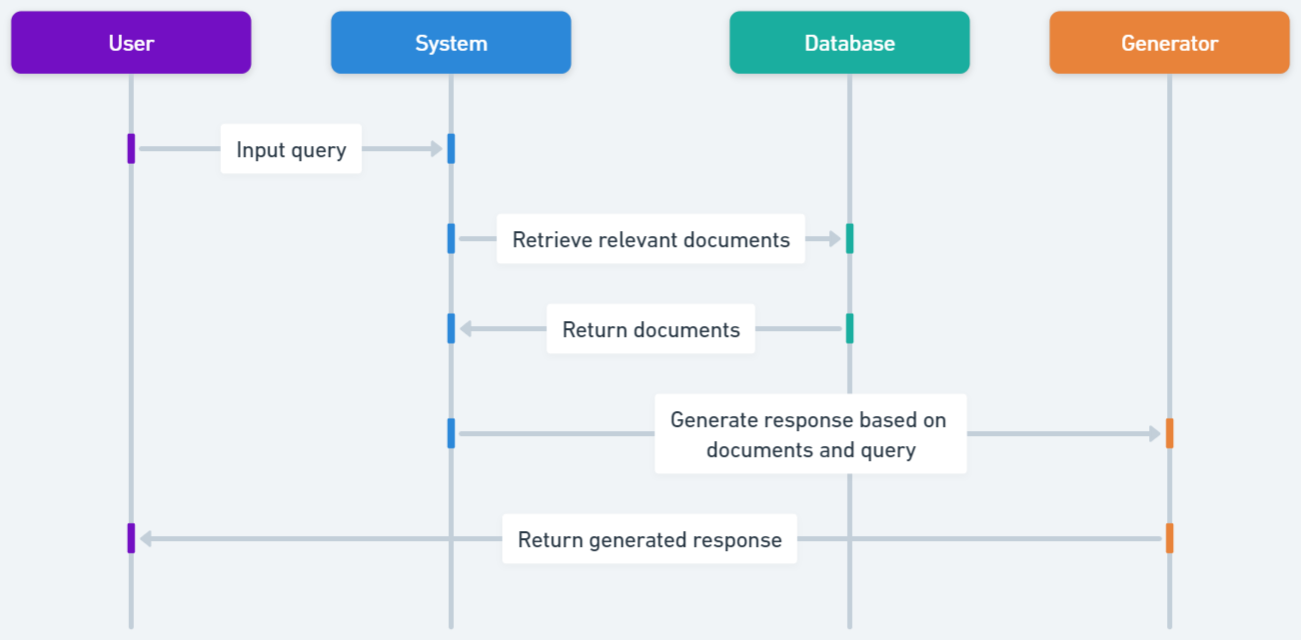
Standard RAG workflow illustrating the baseline system
Evaluation Highlights
- Sentence Window Retrieval achieves the highest median retrieval precision (~0.85-0.90 range), significantly outperforming Naive RAG.
- HyDE (Hypothetical Document Embedding) combined with LLM Rerank statistically significantly outperforms Naive RAG in retrieval precision.
- Multi-query approaches underperformed Naive RAG in retrieval precision, contradicting common assumptions about query expansion benefits.
Breakthrough Assessment
4/10
Valuable exploratory analysis and benchmarking of existing techniques rather than a new architectural breakthrough. Provides useful negative results (MMR/Multi-query performance) for practitioners.