📝 Paper Summary
Agentic RAG pipeline
RAG-R1 replaces brittle single-query retrieval with multi-query parallelism within a reinforcement learning framework, enabling models to adaptively reason, search, and synthesize diverse evidence.
Core Problem
Existing RL-based RAG methods rely on single-query serial execution, which causes prohibitive latency due to sequential waiting and brittleness where one bad query derails the entire reasoning path.
Why it matters:
- Serial execution in multi-hop reasoning accumulates latency at each step, making real-time application impractical
- Single-query approaches are fragile; a suboptimal initial search locks the model into an unrecoverable failure mode
- Models memorize solution paths during standard training rather than learning true generalization to novel scenarios
Concrete Example:
In a multi-hop question like 'Which writer born in 1970 wrote Book X?', a single-query model might search for 'Book X writer' and fail if the first result is ambiguous. By contrast, RAG-R1 generates 'Book X writer', 'Writers born in 1970', and 'Book X publication date' simultaneously, recovering if one path fails.
Key Novelty
Multi-Query Parallelism + Outcome-Based RL
- Transitions from single-threaded think-then-search to a parallel architecture where the model generates multiple queries simultaneously, reducing the number of serial retrieval steps needed
- Uses a two-stage training framework: first learning the 'think-then-search' format via Supervised Fine-Tuning, then optimizing the reasoning and retrieval logic using Reinforcement Learning with outcome-based rewards
Architecture
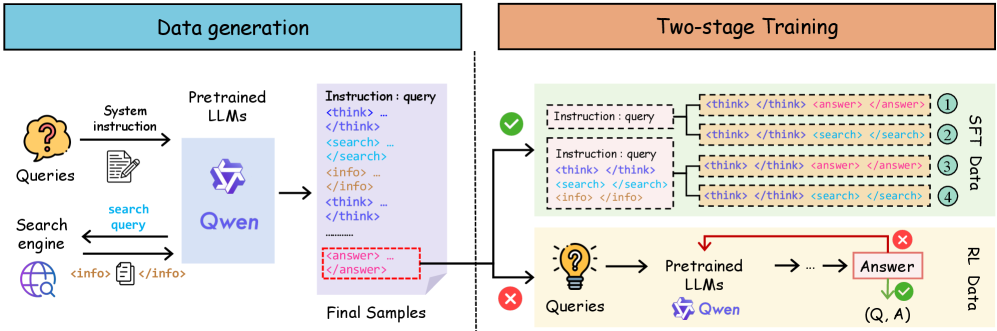
The two-stage training framework of RAG-R1. Stage 1 (Format Learning SFT) shows data segmentation into reasoning/search samples. Stage 2 (Retrieval-Augmented RL) shows the PPO loop with environment interaction.
Evaluation Highlights
- Outperforms the strongest RL-based baseline (R1-Searcher) by 13.7% on average across seven QA benchmarks
- Reduces inference time by 11.1% compared to single-query baselines by parallelizing retrieval steps
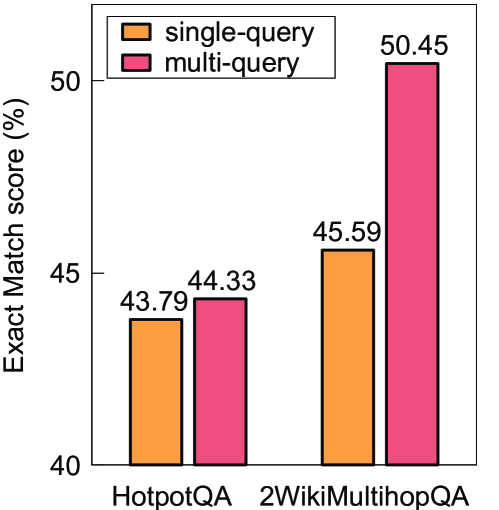
- Achieves 65.5% Exact Match on HotpotQA (multi-query), surpassing the single-query variant (63.7%) and standard RAG baselines
Breakthrough Assessment
8/10
Significant architectural shift from serial to parallel retrieval in RL-based RAG, addressing both latency and robustness. Strong empirical gains (+13.7%) on major benchmarks justify a high score.