📝 Paper Summary
Graph-based RAG pipeline
Domain-specific RAG (Medical)
MedGraphRAG enhances medical LLM reliability by constructing a three-tier knowledge graph linking private data to medical literature and dictionaries, then employing a top-down U-shaped retrieval strategy.
Core Problem
General LLMs struggle with specialized medical knowledge, often hallucinating or lacking traceability, while standard GraphRAG is computationally expensive and lacks mechanisms to ensure responses are grounded in verified medical sources.
Why it matters:
- Medicine relies on precise terminology and established truths; hallucinations or creative modifications of data can be dangerous.
- Fitting vast medical knowledge bases into finite context windows is impossible, and SFT is often prohibitively expensive or unfeasible.
- Existing GraphRAG approaches lack specific designs for response authentication and credibility required in high-stakes healthcare settings.
Concrete Example:
When asking about specific disease symptoms or drug side effects, a standard RAG model might hallucinate plausible-sounding but incorrect interactions. MedGraphRAG prevents this by linking the user document to a specific entry in a trusted medical dictionary (UMLS) and citing the source explicitly.
Key Novelty
MedGraphRAG (Medical Graph Retrieval-Augmented Generation)
- Triple Graph Construction: hierarchically links user documents to established medical textbooks/papers and controlled vocabulary (UMLS) to ensure traceability.
- U-Retrieval: A 'U-shaped' process that performs top-down precise indexing via hierarchical tags to find relevant graphs, then bottom-up response refinement to generate answers.
- Hybrid Chunking: Combines character-based separation with topic-based semantic segmentation to better capture medical context.
Architecture
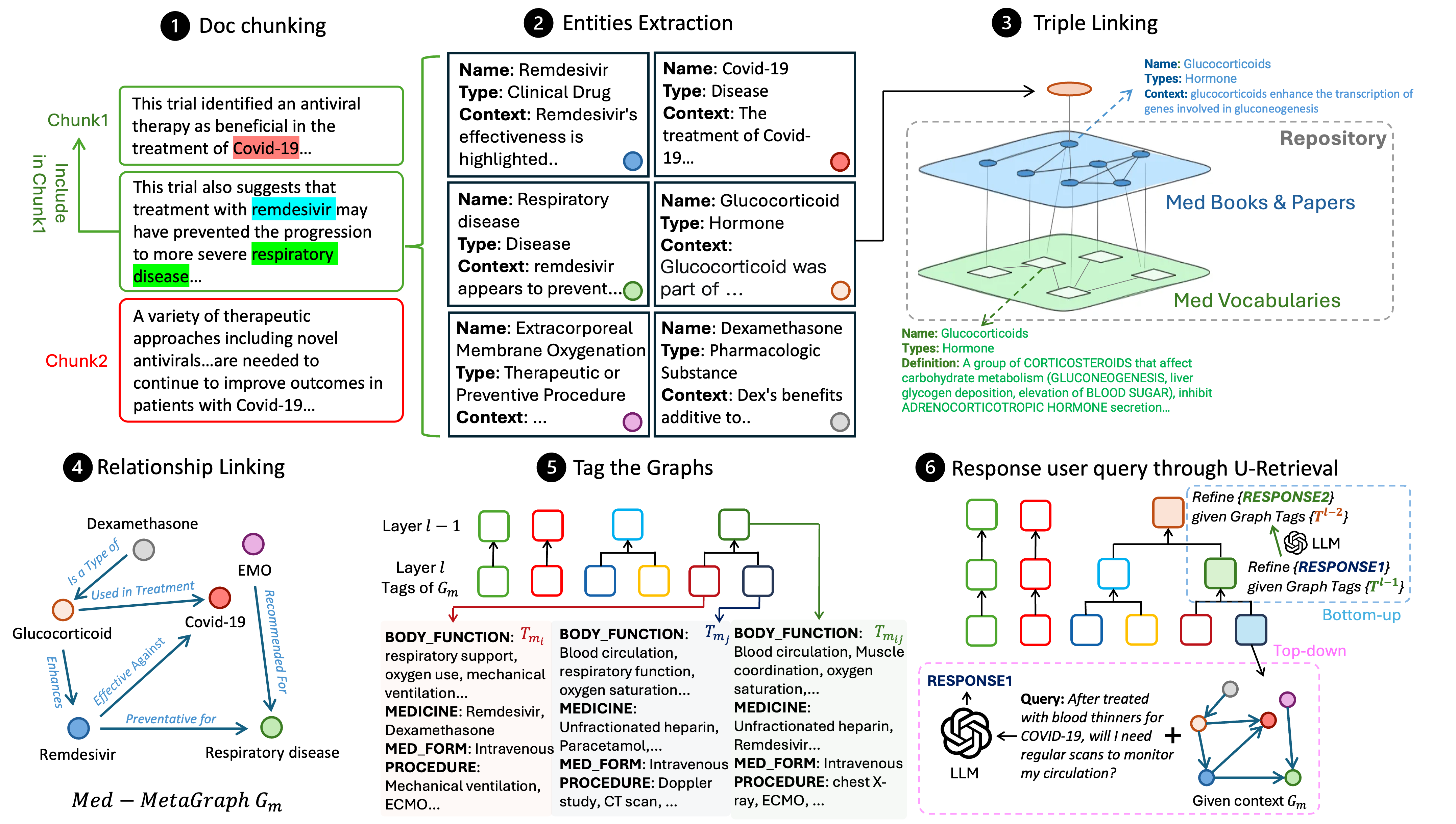
The complete MedGraphRAG workflow, including Document Processing, Triple Graph Construction, and U-Retrieval.
Evaluation Highlights
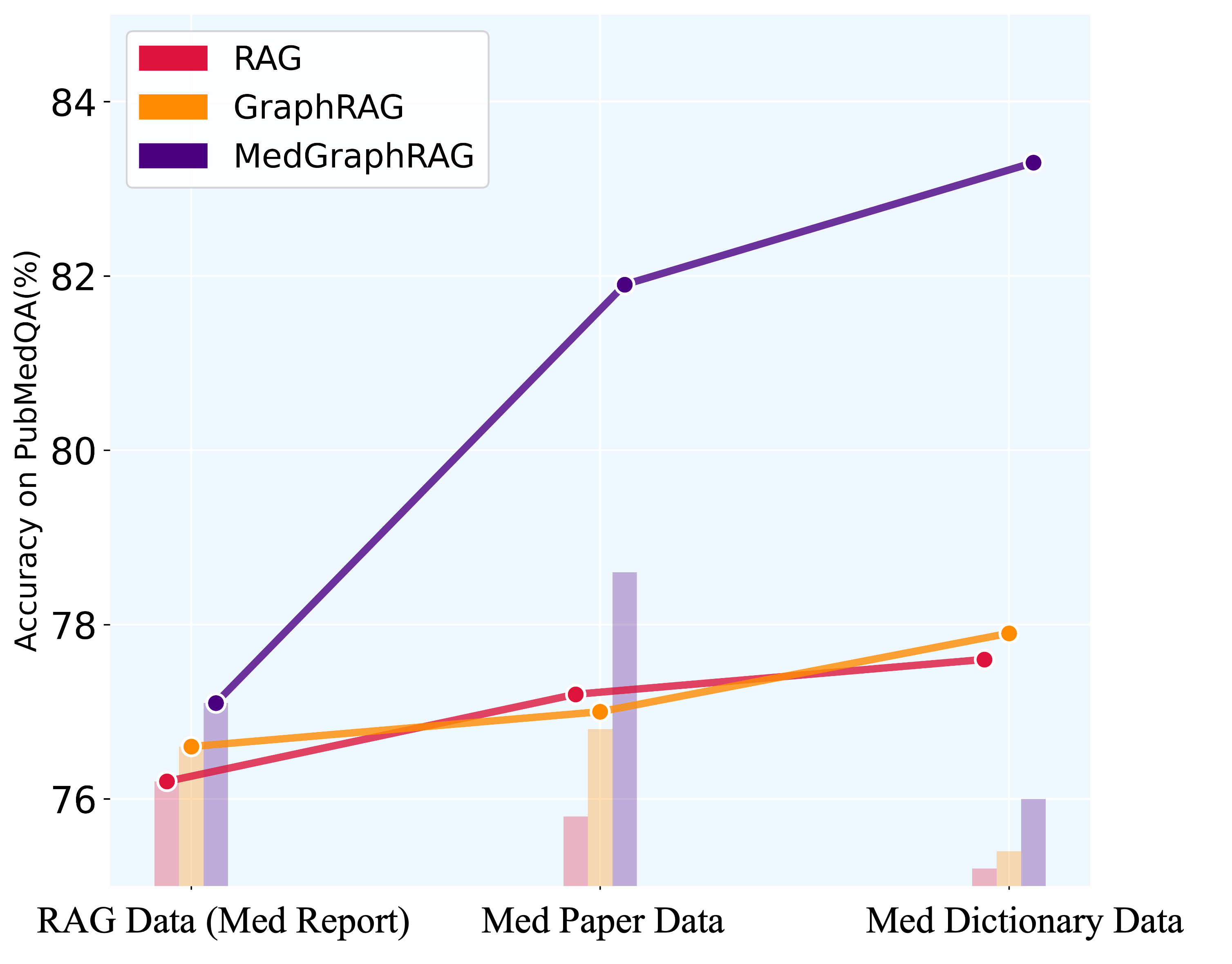
- Outperforms state-of-the-art models on all 9 medical Q&A benchmarks (e.g., +2.53% accuracy on PubMedQA over Med-PaLM 2).
- Outperforms GraphRAG on comprehensive long-form generation tasks (68.64 vs 47.92 in comprehensiveness score).
- Achieves significantly higher source utilization rate (63.82%) compared to GraphRAG (29.27%) in human evaluation.
Breakthrough Assessment
8/10
Strong methodological contribution in adapting GraphRAG for high-stakes domains via source grounding (Triple Graph) and efficient retrieval (U-Retrieval). consistently beats domain-specific SOTA models.