📊 Experiments & Results
Evaluation Setup
Controlled generation under conflict: Prompts intentionally overstate object counts or misstate colors compared to the image.
Benchmarks:
- CountBench (Object Counting (Modified for PIH))
- Visual CounterFact (Color Identification (Modified for PIH))
Metrics:
- Prompt Match Rate (Percentage of outputs matching the incorrect prompt)
- True Count/Color Match Rate (Percentage of outputs matching the visual ground truth)
- Exact Match Accuracy (on baseline prompts)
- Statistical methodology: Pearson correlation reported for confidence vs. prompt conformity. Confidence intervals not explicitly reported.
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Ablating PIH heads drastically reduces the rate at which models copy incorrect object counts from the prompt and increases the rate at which they report the true visual count. | ||||
| CountBench | Prompt Match Rate | 42.13 | 10.08 | -32.05 |
| CountBench | True Count Match Rate | 24.03 | 78.43 | +54.40 |
| CountBench | Prompt Match Rate | 63.24 | 10.74 | -52.50 |
| CountBench | True Count Match Rate | 24.89 | 69.47 | +44.58 |
| CountBench | True Count Match Rate | 15.00 | 70.20 | +55.20 |
| Heads identified via counting task generalize to color tasks, reducing prompt copying without re-identification. | ||||
| Visual CounterFact | Prompt Match Rate | 98.50 | 4.25 | -94.25 |
| Visual CounterFact | Prompt Match Rate | 95.50 | 44.75 | -50.75 |
Experiment Figures
Line graphs showing the probability of the model outputting the Prompt Count (Blue) vs. True Count (Orange) as the number of objects increases.
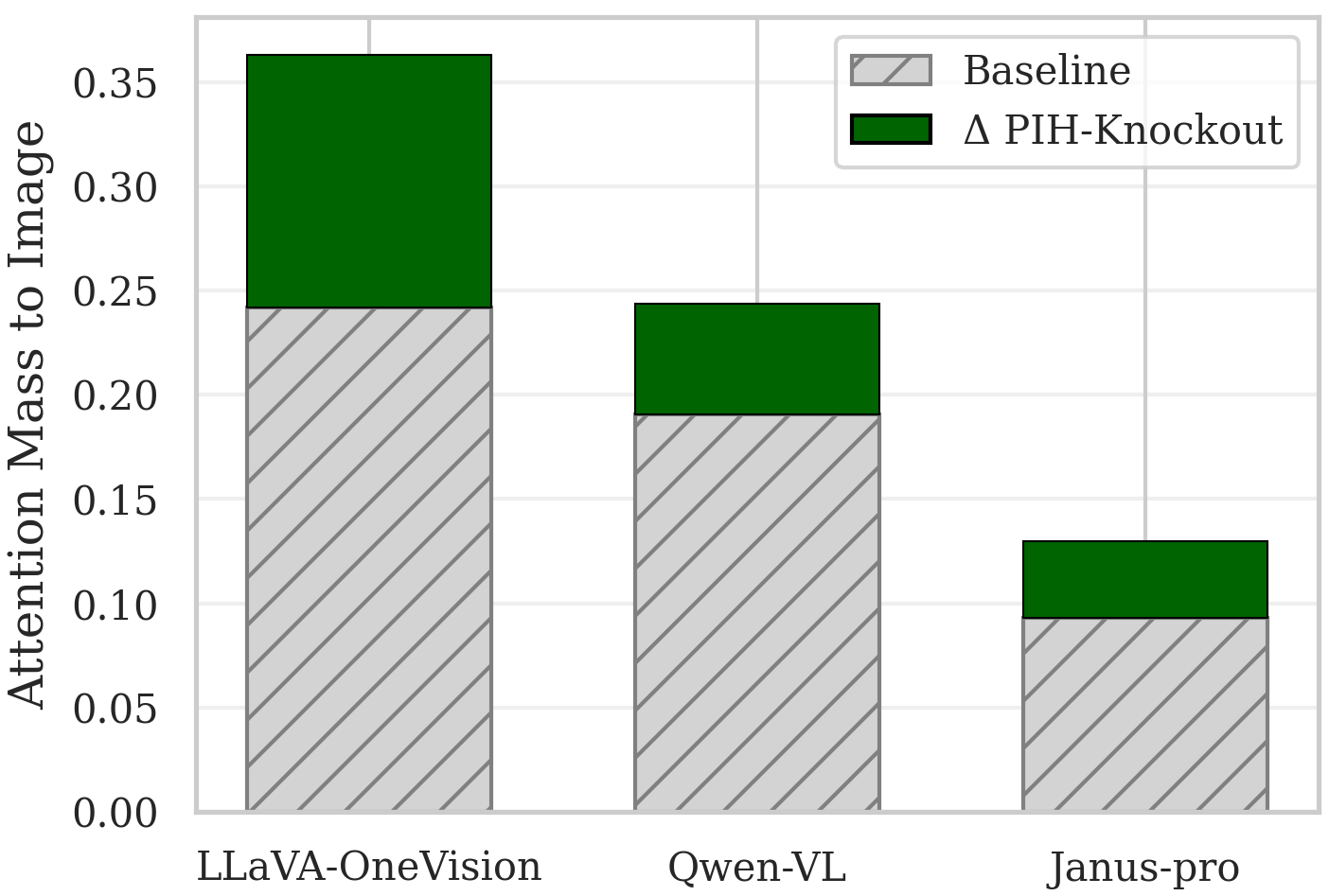
Bar charts displaying the shift in attention mass from text tokens to image tokens after ablating PIH heads.
Main Takeaways
- PIH behavior is highly structured: models resist small discrepancies at low counts (N<4) but capitulate to prompts at higher counts or counts >4.
- A small set of specific attention heads (often in early layers like L0) mediates this copying behavior.
- Ablation mechanisms differ by model: LLaVA-OneVision shifts attention mass significantly to image tokens, while Janus-Pro primarily suppresses format copying.
- The identified heads are task-agnostic regarding the type of hallucination; heads found via counting errors also fix color errors.