📝 Paper Summary
Medical Vision-Language Models (Med-LVLMs)
Retrieval-Augmented Generation (RAG)
MMed-RAG improves medical vision-language model factuality by using domain-aware retrieval, adaptively truncating low-quality contexts based on similarity drops, and fine-tuning on preference pairs to align retrieval usage.
Core Problem
Medical Vision-Language Models suffer from factual hallucinations and misalignment issues when using standard RAG, as they may ignore input images or be confused by irrelevant retrieved contexts.
Why it matters:
- Current Med-LVLMs generate non-factual responses, posing severe risks in clinical settings where diagnostic errors have high stakes.
- Existing medical RAG methods are often dataset-specific and cause cross-modality misalignment (ignoring the image) or overall misalignment (confusion by retrieved noise).
- Fine-tuning alone is limited by scarce high-quality medical data and distribution shifts between training and deployment.
Concrete Example:
When an original model is given a noisy image with a different ground truth, it often answers incorrectly. After adding standard RAG based on the original image, it answers correctly 55.08% of the time despite the noisy input, proving it ignores the visual input and relies solely on text retrieval (cross-modal misalignment).
Key Novelty
Versatile Multimodal Medical RAG (MMed-RAG)
- Routes input images to specific retrieval models (radiology, pathology, etc.) via a domain identification module rather than using a generic retriever.
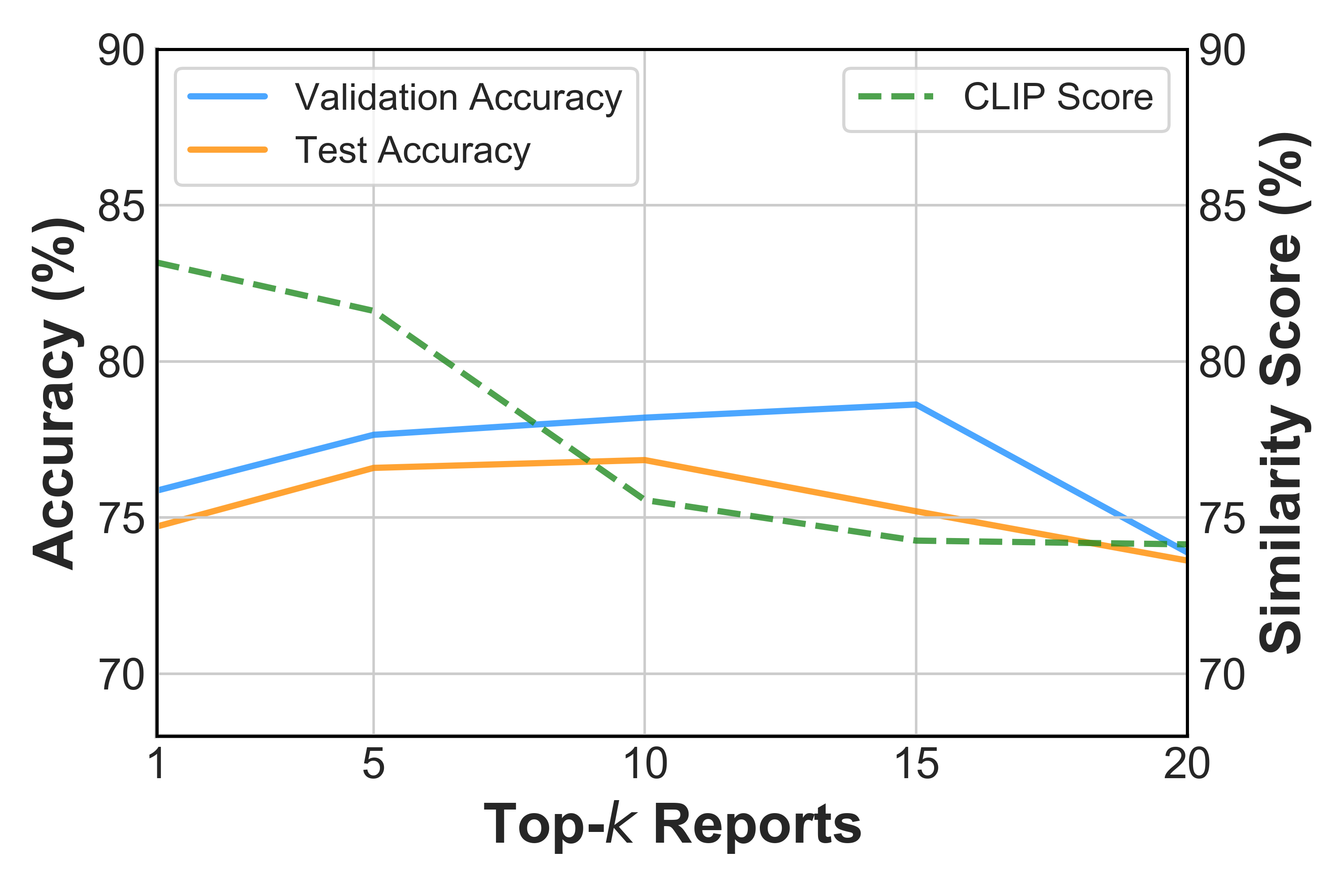
- Dynamically determines the number of retrieved documents (k) by analyzing the 'gap' or drop in similarity scores, truncating when relevance falls sharply.
- Fine-tunes the generator using preference optimization (DPO) on pairs designed to penalize ignoring the image (cross-modal misalignment) or being misled by irrelevant retrieval.
Architecture
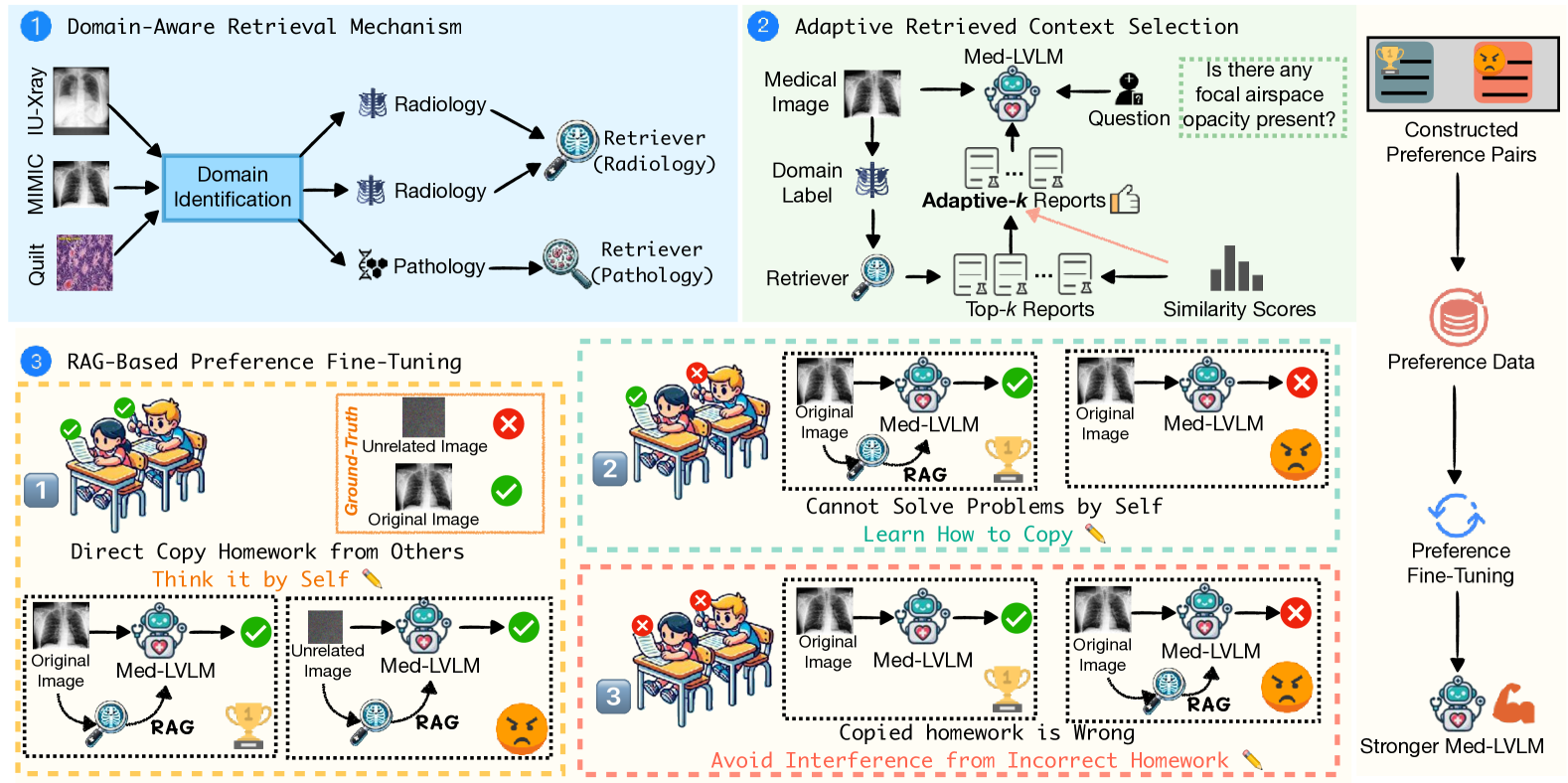
Overview of the MMed-RAG framework, illustrating the three main stages: Domain-Aware Retrieval, Adaptive Context Selection, and RAG-based Preference Fine-tuning.
Evaluation Highlights
- +18.5% average improvement in factual accuracy on Medical VQA tasks compared to the original Med-LVLM baseline.
- +69.1% average improvement in factual accuracy on report generation tasks compared to the original Med-LVLM baseline.
- Achieves 83.20% accuracy on VQA-RAD, outperforming the LLaVA-Med-1.5 baseline (62.40%) by a wide margin.
Breakthrough Assessment
7/10
Significant empirical gains in medical VQA/report generation and a theoretically grounded approach to RAG alignment (DPO for RAG). The adaptive k selection is a smart, practical heuristic.