📊 Experiments & Results
Evaluation Setup
Theoretical derivation and illustrative toy examples (e.g., Gaussian Mixture Models).
Metrics:
- Statistical methodology: Not explicitly reported in the paper
Experiment Figures
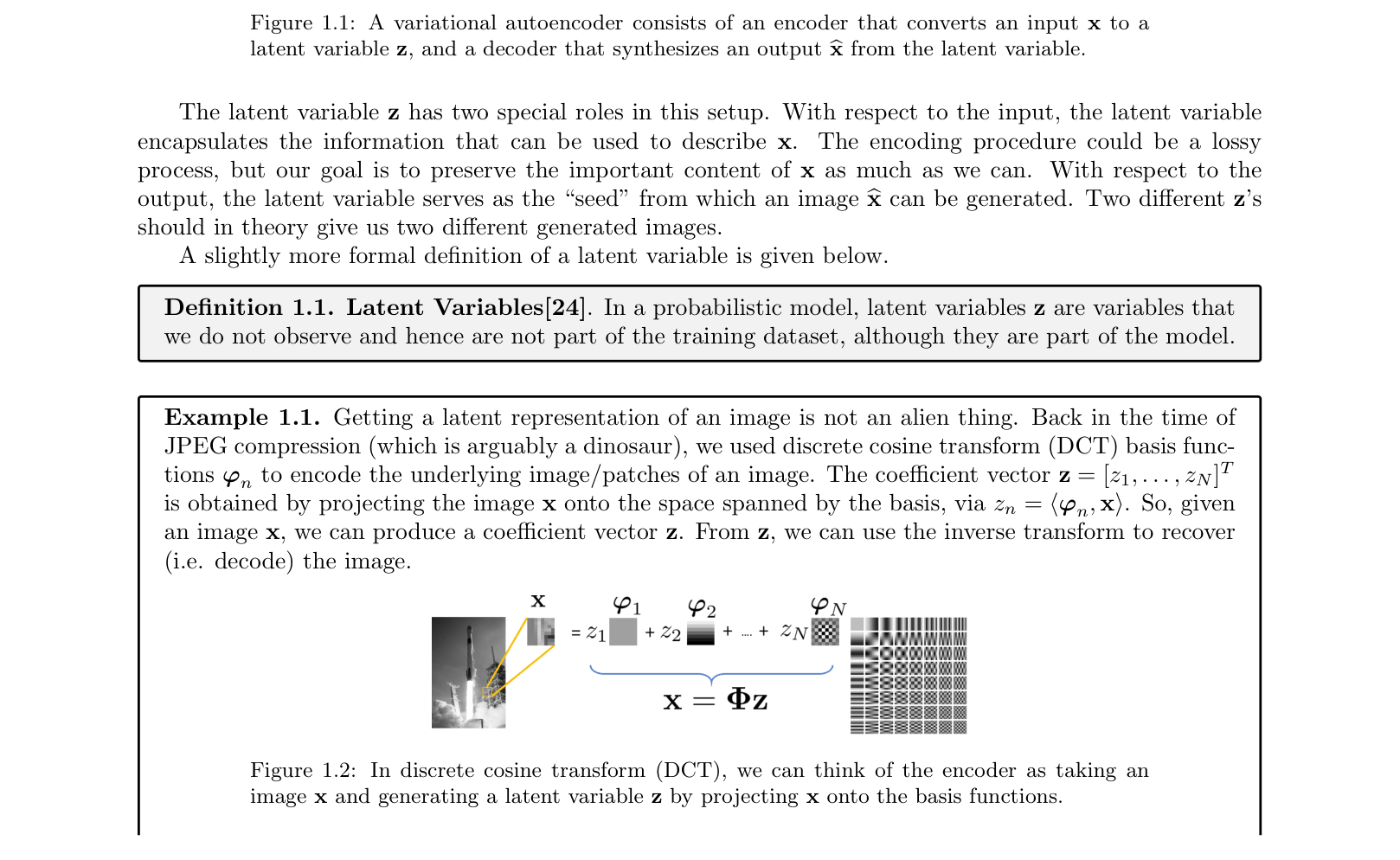
Visualization of the gap between the true log-likelihood log p(x) and the Evidence Lower Bound (ELBO).
Main Takeaways
- The 'magic' of diffusion models is mathematically equivalent to maximizing the Evidence Lower Bound (ELBO), just like in VAEs, but with a specific structure that allows the loss to simplify to a weighted squared error of noise prediction.
- The forward diffusion process q(xt|x0) can be computed in closed form for any timestep t without iterating through all intermediate steps, thanks to properties of Gaussian distributions.
- The reverse process p(xt-1|xt) can be approximated as a Gaussian if the forward steps are small enough (T is large), justifying the functional form of the decoder.
- Discrete iterative diffusion models (DDPM, SMLD) can be viewed as numerical solvers (discretizations) of continuous Stochastic Differential Equations (SDEs), providing a unified view of generation as time-reversal of a diffusion process.