📝 Paper Summary
Video-Language Models (Video LLMs)
Temporal Grounding
D2VLM decouples video understanding into pure grounding followed by evidence-referenced answering, supported by special tokens that capture visual semantics and a factorized preference optimization algorithm.
Core Problem
Existing video LLMs handle temporal grounding and textual response in a coupled manner without clear logical structure, leading to sub-optimal objectives where grounding tokens focus only on timestamps rather than visual semantics.
Why it matters:
- Coupled learning objectives confuse the model, leading to inaccurate temporal localization and hallucinations in textual answers.
- Current special tokens for grounding only represent timestamps, missing the rich visual context of the event needed for the subsequent textual answer.
- Lack of explicit preference optimization for temporal grounding limits the model's ability to align with human intent on localization tasks.
Concrete Example:
In a video query asking 'What did I put in the rack?', a standard model might output a timestamp '[23.5s - 46.1s]' but incorrectly describe the object as a 'Large basket' because the timestamp token didn't capture the specific visual event of placing a 'Small bag'.
Key Novelty
D2VLM (Decoupled & Dependent Video-Language Model)
- Decomposes generation into two stages: first 'pure grounding' to find evidence, then 'interleaved text-evidence answering' that references that evidence.
- Introduces a visual-semantic '<evi>' token that aggregates features from relevant video frames, explicitly capturing event content rather than just time boundaries.
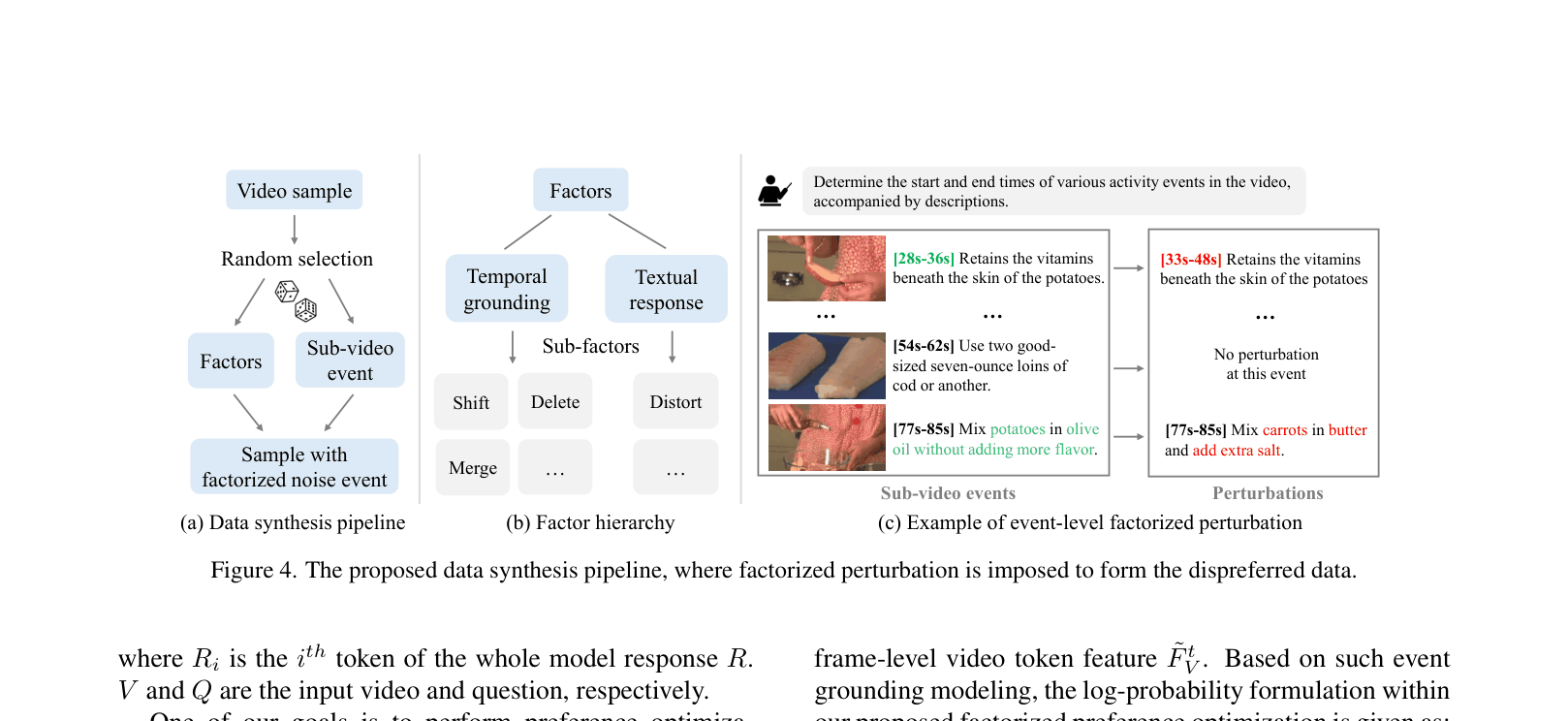
- Proposes Factorized Preference Optimization (FPO) to optimize both textual quality and probabilistic grounding accuracy using a synthetic factorized dataset.
Architecture

The D2VLM framework showing the two-stage generation process and the evidence token mechanism.
Evaluation Highlights
- +21.6% average F1 improvement on E.T. Bench Grounding compared to E.T.Chat-3.8B (38.6% → 60.2%).
- +4.4% improvement on Charades-STA R@1(IoU=0.5) compared to E.T.Chat-3.8B (45.9% → 50.3%).
- Outperforms larger 7B/13B models (e.g., LITA-13B, TimeChat-7B) using a smaller 3.8B parameter model across grounding and captioning benchmarks.
Breakthrough Assessment
8/10
Significant performance jumps (+20% F1) on grounding benchmarks with a smaller model. The factorized preference optimization for grounding is a novel and methodologically sound contribution to aligning multimodal models.