📝 Paper Summary
LLM-based recommendation
Instruction Tuning
InstructRec adapts Large Language Models to recommender systems by fine-tuning them on 252K automatically generated natural language instructions covering diverse user preferences, intentions, and task forms.
Core Problem
General-purpose LLMs lack the ability to understand specialized recommendation tasks and behavioral data (like user interaction histories), while traditional recommenders cannot handle flexible natural language instructions from users.
Why it matters:
- Users in traditional systems are passive and cannot explicitly express diverse needs (e.g., 'vague intention' vs. 'specific intention').
- LLMs struggle with complex specialized tasks like recommendation without tuning, despite their general NLP capabilities.
- Existing approaches like P5 focus on task-specific prompts but neglect aligning LLMs with detailed, user-centric needs in practical scenarios.
Concrete Example:
A user might want 'some gifts for my son' (vague intention) or 'blue, cheap, iPhone13' (specific intention). A standard collaborative filtering model only sees item IDs, while a general LLM (like GPT-3.5) fails to connect private behavioral history with these text requests effectively.
Key Novelty
Recommendation as Instruction Following (InstructRec)
- Formalizes recommendation as an instruction following task where user needs are decomposed into Preference (long-term), Intention (short-term), and Task Form (pointwise/matching/reranking).
- Uses a 'Teacher-LLM' (GPT-3.5) to synthesize natural language preferences and intentions from raw user behavior logs (interactions and reviews).
- Applies instruction tuning to a 3B parameter model (Flan-T5-XL) to bridge the gap between general language understanding and personalized recommendation behavior.
Architecture
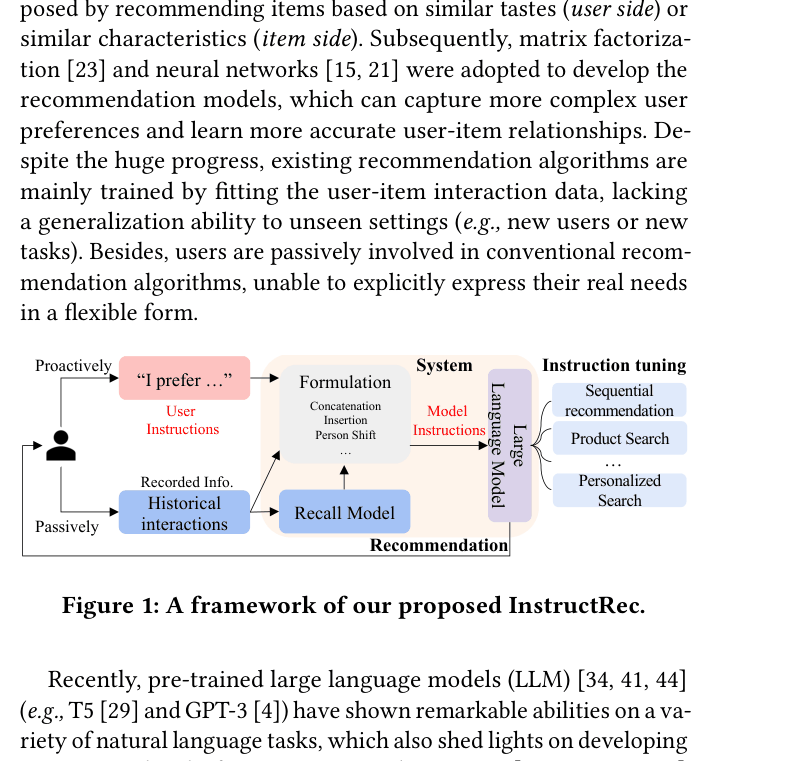
The overall framework of InstructRec. It illustrates the pipeline from converting user data into natural language instructions (Preference, Intention, Task Form), generating instruction data, and fine-tuning the LLM.
Evaluation Highlights
- Outperforms GPT-3.5 significantly on sequential recommendation (HR@1: 0.6947 vs 0.3640) and personalized search (HR@1: 0.6959 vs 0.2740), demonstrating the necessity of domain-specific instruction tuning.
- Achieves superior performance over specialized baselines like SASRec (+4.26% HR@1) in sequential recommendation tasks.
- Surpasses personalized search baselines (TEM) by nearly 40% in HR@1 when handling explicit user preference instructions.
Breakthrough Assessment
7/10
Strong conceptual contribution in formalizing recommendation as instruction following and generating synthetic instruction data. Shows clear gains over zero-shot LLMs, though relies on existing backbone models.