📝 Paper Summary
In-Context Learning (ICL)
Compositional Generalization
Providing examples of simple tasks often hurts performance on composite tasks because models fail to recognize the composition, a failure mitigated by explicitly aligning examples to steps via Expanded Chain-of-Thought.
Core Problem
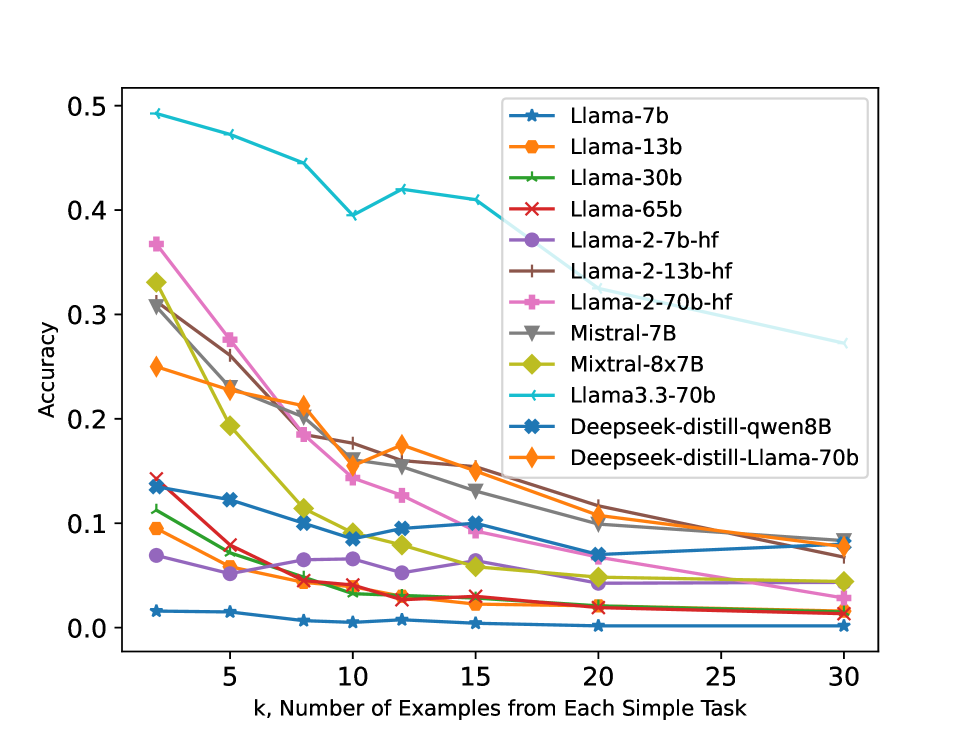
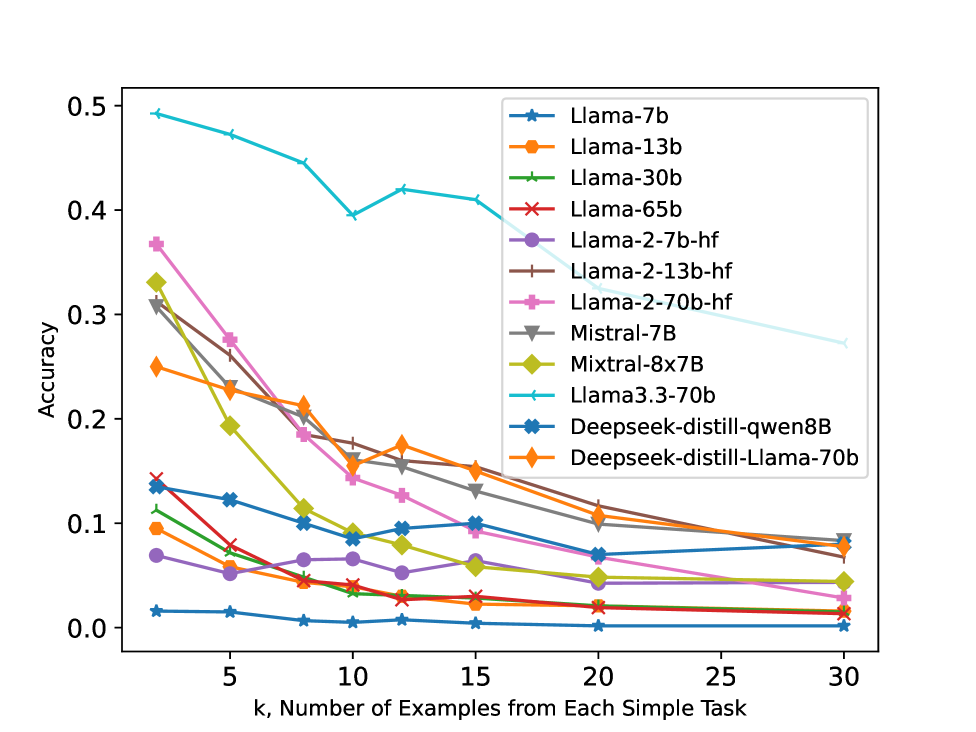
Models struggle to perform composite tasks (combining basic skills) in-context when given examples of the simple skills, often performing worse with more simple examples.
Why it matters:
- The exponential number of possible task compositions makes learning each individually impossible; systems must generalize by composing known skills.
- Current assumptions that providing examples of basic skills helps models solve complex queries are empirically contradicted.
- Models treat relevant skill examples as interfering noise rather than useful signals for composition.
Concrete Example:
For a composite task 'opposition+swap' (e.g., input '* Grow Respect #'), providing more examples of just the 'opposition' task causes the model to ignore the 'swap' operation and output only the antonyms (e.g., 'Shrink Disrespect') instead of the swapped antonyms.
Key Novelty
Expanded Chain-of-Thought (ExpCoT)
- Treats simple task examples as 'composite examples with missing steps' rather than distinct tasks.
- Expands all examples into a uniform Chain-of-Thought format where missing operations are marked with special placeholders (e.g., 'Step 1: ???').
- Explicitly aligns each example to its corresponding step in the composition process, preventing the model from matching the query to the wrong task.
Architecture
The ExpCoT (Expanded Chain-of-Thought) algorithm procedure.
Evaluation Highlights
- Increasing simple task examples (k=2 to 30) causes average accuracy drops of ~7.5% on Llama-13B for composite tasks.
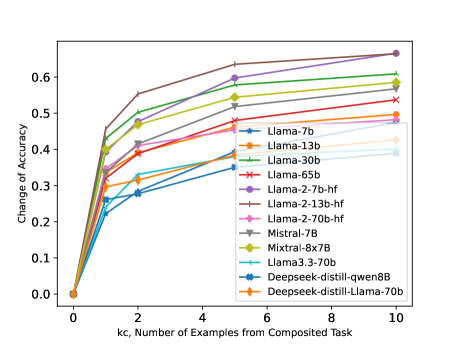
- ExpCoT significantly outperforms standard prompting and Naïve CoT; e.g., on Llama-2-13B, ExpCoT achieves ~60% accuracy vs <20% for Naïve CoT on specific tasks.
- Inner attention analysis reveals high cosine similarity between simple and composite task queries, confirming models fail to distinguish them structurally.
Breakthrough Assessment
7/10
Reveals a counter-intuitive failure mode in ICL (simple examples hurt composition) and provides a theoretically grounded, effective fix (ExpCoT). High value for understanding ICL limitations.