📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Instruction Tuning
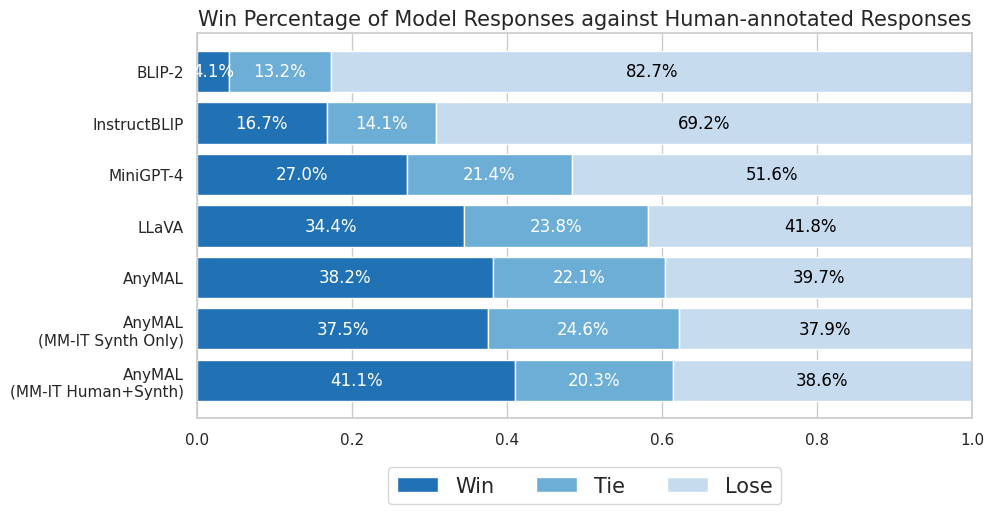
AnyMAL aligns diverse modalities (image, video, audio, IMU) to a frozen 70B LLM via lightweight adapters and fine-tunes with a custom multimodal instruction set for broad reasoning capabilities.
Core Problem
Prior multimodal LLMs typically focus on limited modalities (mostly image-text), often lack open-source scalability, or fail to generalize to diverse instruction-following tasks beyond simple Q&A.
Why it matters:
- Restricting models to single non-text modalities (like only images) limits their ability to reason over complex, real-world sensory environments.
- Existing datasets for instruction tuning often lack the diversity required for creative or complex reasoning (e.g., 'write a poem based on this image').
- Scaling multimodal pre-training to 70B parameter models is computationally expensive and memory-intensive.
Concrete Example:
When asked to 'Write a short story about the scene' involving seagulls, baselines like BLIP-2 or InstructBLIP often output short, caption-like fragments (e.g., 'a bird'), whereas AnyMAL generates a coherent narrative with dialogue.
Key Novelty
Unified Multimodal Alignment with Quantized Pre-training
- Projects signals from diverse pre-trained encoders (image, audio, video, IMU) into a shared text embedding space using lightweight adapters while keeping the massive LLM (70B) frozen.
- Uses quantization (4-bit/8-bit) during pre-training to fit the 70B model on standard hardware, enabling scalable alignment without full fine-tuning.
- Introduces a manually collected 'Multimodal Instruction Tuning' (MM-IT) dataset specifically designed for open-ended, complex reasoning tasks beyond standard VQA.
Architecture
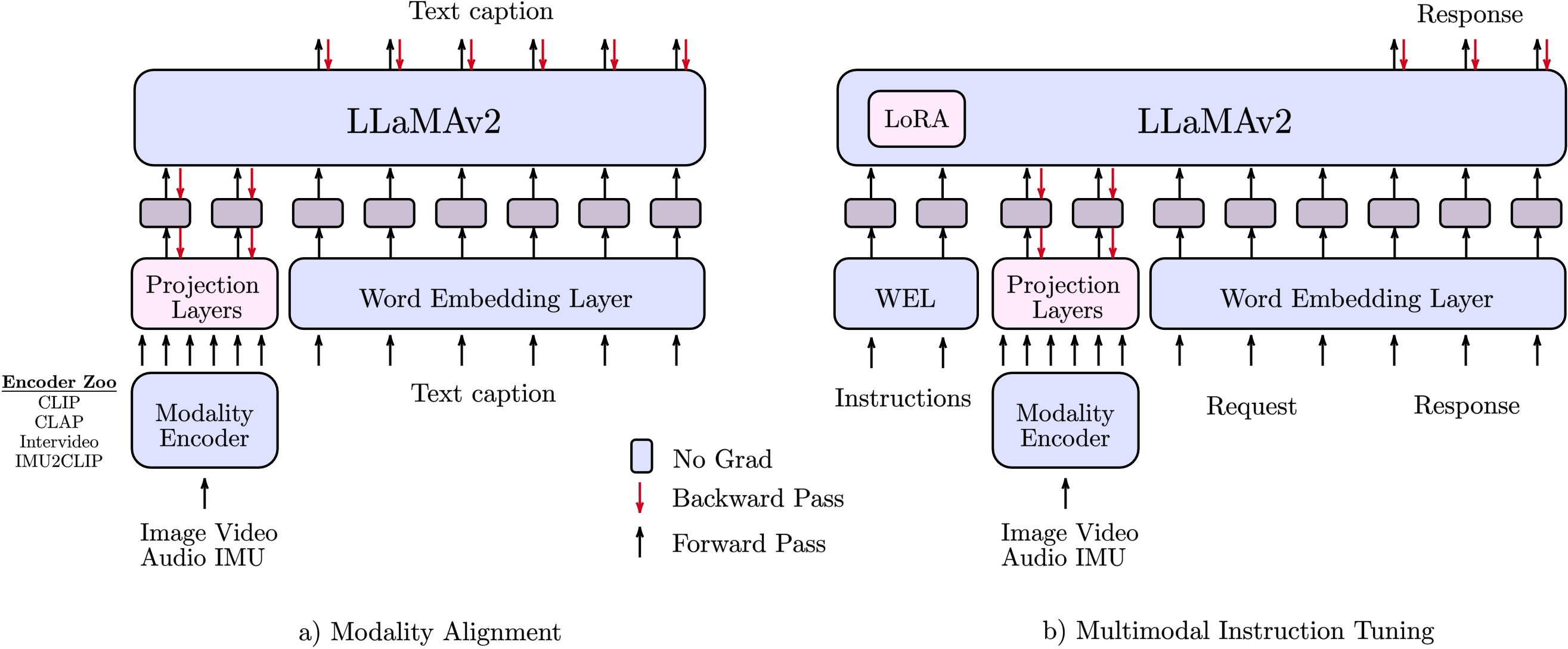
The AnyMAL methodology: aligning diverse modalities (Image, Audio, Video, IMU) to a frozen LLM via lightweight adapters.
Evaluation Highlights
- +7.0% relative accuracy improvement on VQAv2 zero-shot compared to literature baselines.
- +8.4 CIDEr score improvement on zero-shot COCO image captioning compared to previous state-of-the-art.
- +14.5 CIDEr score improvement on AudioCaps audio captioning compared to literature baselines.
Breakthrough Assessment
8/10
Significantly expands multimodal capabilities beyond vision to audio/IMU with strong zero-shot performance and a new high-quality instruction dataset. Demonstrates effective scaling to 70B models via quantization.