📝 Paper Summary
LLM-based Recommendation
Graph Augmentation for Recommender Systems
Side Information Enhancement
LLMRec uses Large Language Models to augment interaction graphs by predicting user-item edges and generating node attributes, then refines this data via noise pruning and masked autoencoders to improve collaborative filtering.
Core Problem
Collaborative filtering suffers from sparse implicit feedback, and incorporating side information often introduces noise, heterogeneity, or low-quality data that hinders accurate user preference modeling.
Why it matters:
- Sparse interaction data limits the effectiveness of Graph Neural Networks (GNNs) in capturing user preferences
- Side information (e.g., text descriptions) on platforms like Netflix is often noisy, incomplete, or irrelevant to the collaborative filtering task
- Existing augmentation methods (like contrastive learning) may not fully leverage the semantic richness and reasoning capabilities of LLMs
Concrete Example:
In a micro-video recommender, irrelevant textual titles that fail to capture the video's content introduce noise. Similarly, privacy concerns may lead to missing user profiles. Standard models struggle to learn from this incomplete or noisy heterogeneous data.
Key Novelty
LLM-based Graph Augmentation (Edges + Attributes + Profiles)
- Uses an LLM as a knowledge-aware sampler to predict likely positive/negative user-item interactions (edges) from a candidate pool based on natural language reasoning
- Generates missing user profiles and enhances item attributes using the LLM's world knowledge to bridge heterogeneous feature gaps
- Employs a robustification mechanism with noise pruning for edges and MAE-based feature enhancement to filter out unreliable augmented data
Architecture

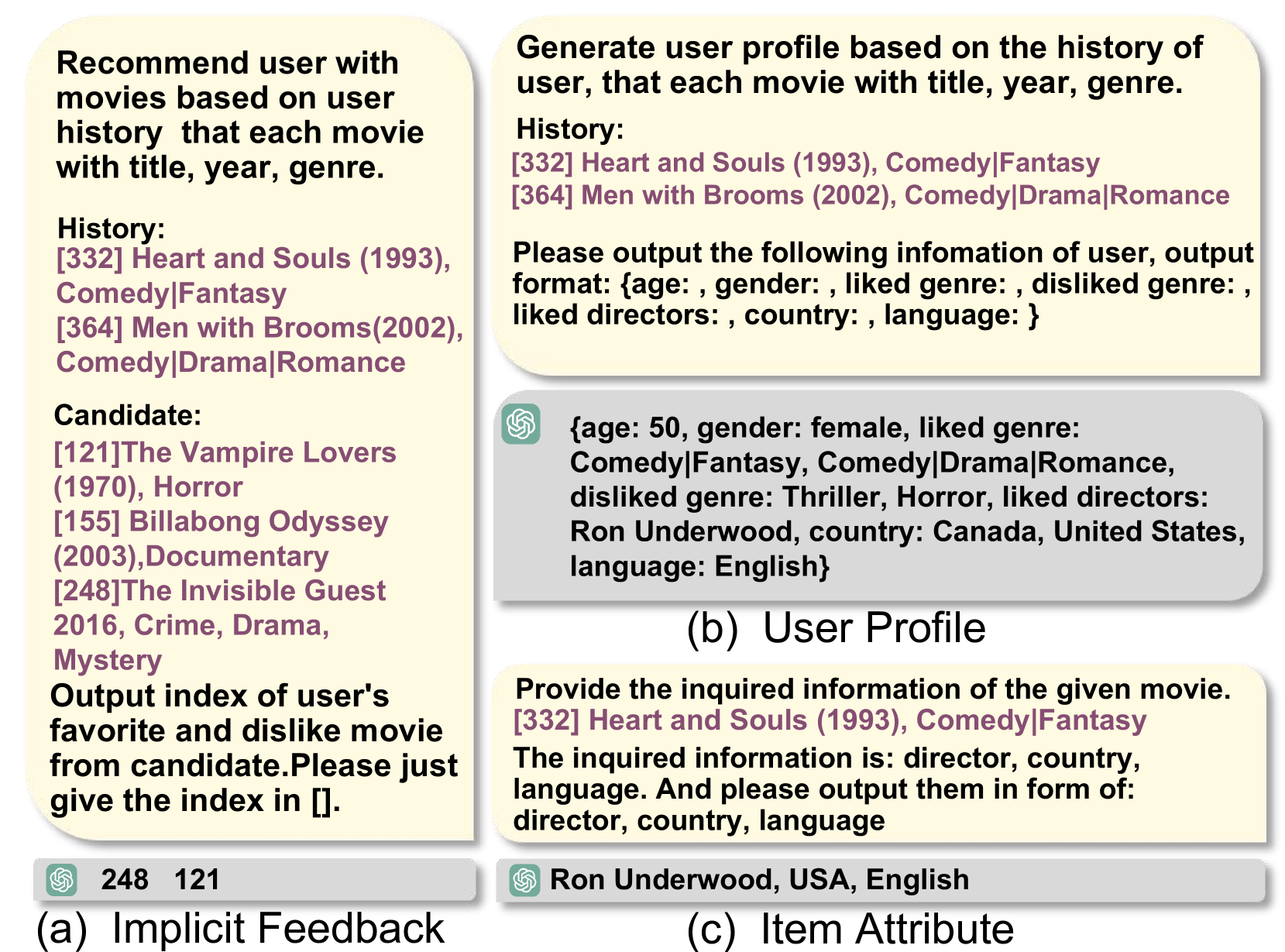
The overall LLMRec framework. It illustrates the three-step augmentation process: (1) LLM-based implicit feedback augmentation (Edge Augmentation), (2) LLM-based side information augmentation (Node Attribute Augmentation), and (3) The robust training pipeline with noise pruning and MAE enhancement.
Evaluation Highlights
- Outperforms state-of-the-art baselines (e.g., MMSSL, LATTICE) on Netflix and MovieLens datasets
- Achieves significant improvements in Recall@10 and NDCG@10 compared to base models like LightGCN and various augmentation strategies
- Demonstrates robustness to data sparsity and noise through ablation studies and varying training data ratios
Breakthrough Assessment
7/10
Novel application of LLMs specifically for *graph augmentation* (both edges and features) in standard CF pipelines, addressing data quality issues directly. Strong results, though it relies on standard LLM inference rather than a new architecture.