📝 Paper Summary
LLM-based recommendation
Prompt-based recommendation
Generative recommendation
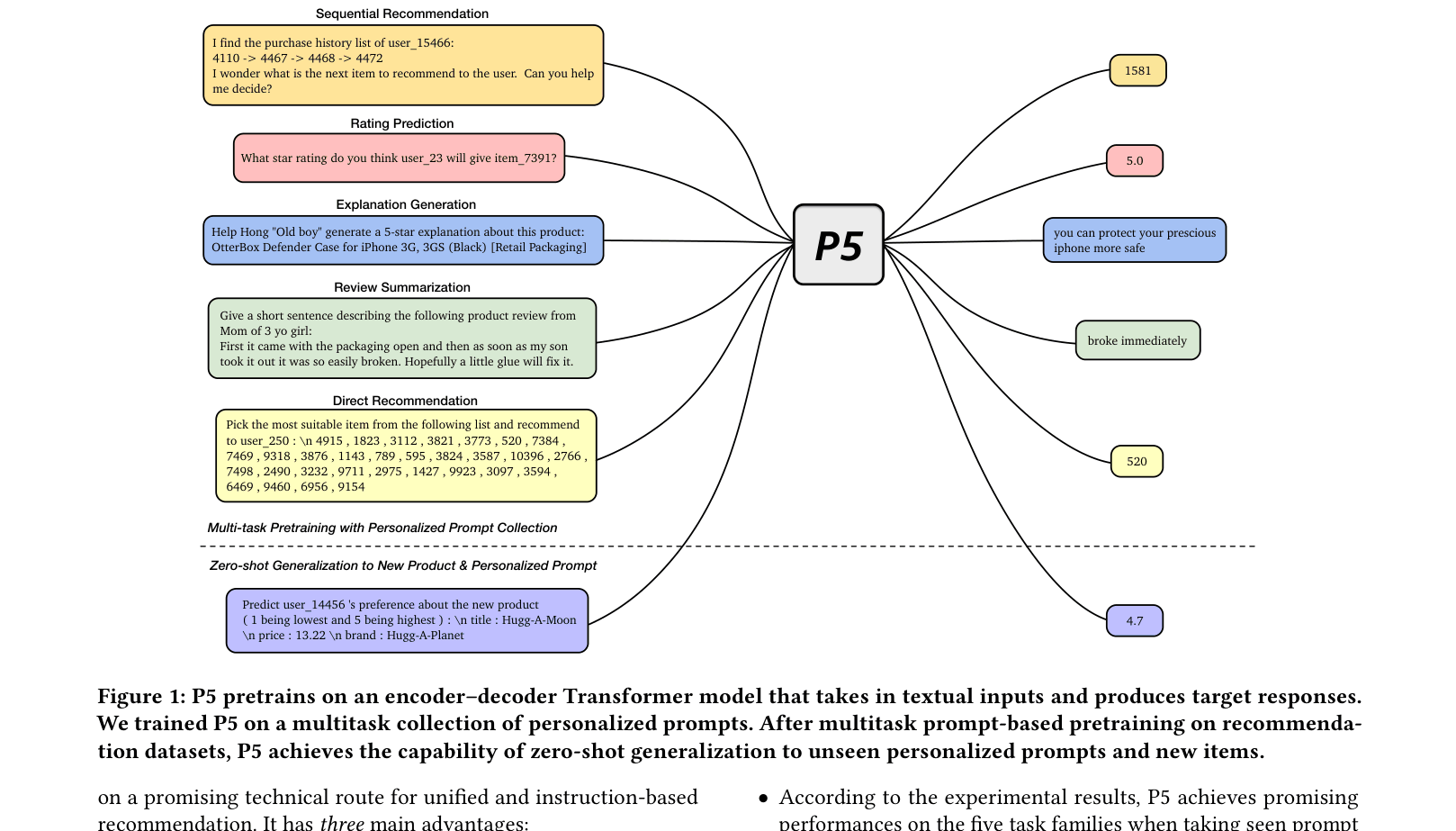
P5 unifies five distinct recommendation tasks into a single conditional text generation framework by converting all user-item data into natural language sequences via personalized prompts.
Core Problem
Traditional recommendation tasks (rating, sequential, explanation) typically require distinct, incompatible model architectures, preventing knowledge transfer and restricting generalization to new tasks.
Why it matters:
- Task-specific architectures create silos where a sequential model cannot easily help with explanation generation, wasting potential shared knowledge
- Existing unified frameworks often overlook personalization or require extensive fine-tuning for downstream tasks rather than enabling zero-shot capability
- Developing separate models for every recommendation sub-task is inefficient compared to a universal engine
Concrete Example:
A sequential recommendation model trained to predict the next item ID (e.g., '10396') cannot naturally generate a text explanation for why the user likes it, nor can it summarize reviews, whereas P5 handles both by just changing the text prompt.
Key Novelty
Pretrain, Personalized Prompt & Predict Paradigm (P5)
- Reformulates all data (user IDs, item metadata, reviews) into natural language sequences using a collection of personalized instruction-based prompts
- Trains a single encoder-decoder model (T5-based) on multiple recommendation tasks simultaneously using a unified language modeling objective
- Enables zero-shot transfer to unseen prompts and new items by leveraging the semantic understanding learned during multitask pretraining
Architecture
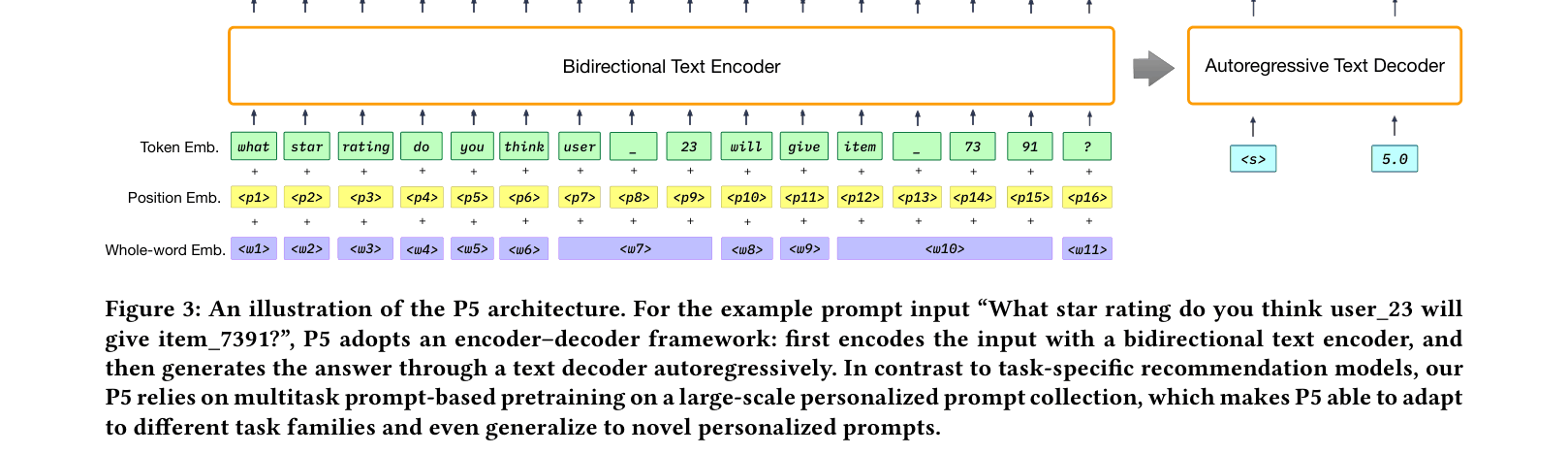
The P5 architecture showing the encoder-decoder flow with input tokenization and embedding summation.
Evaluation Highlights
- Outperforms strong baselines (like SimpleX and BERT4Rec) on sequential and direct recommendation tasks across Sports, Beauty, and Toys datasets (e.g., +2.9% HR@5 on Beauty Sequential)
- Achieves zero-shot generalization to unseen prompts, often matching or beating performance on seen prompts (e.g., P5-B on Sports uses unseen Prompt 2-13 to beat seen Prompt 2-3)
- Demonstrates cross-domain transfer capability, generating plausible explanations for items in a new domain (e.g., trained on Toys, predicting on Beauty) without fine-tuning
Breakthrough Assessment
9/10
A seminal paper establishing the 'Recommendation as Language Processing' paradigm. It successfully unifies disparate tasks (ranking, explanation, rating) into one generative model with strong zero-shot capabilities.