📝 Paper Summary
Memory management for LLMs
Agentic systems
MemGPT manages limited LLM context windows using an operating system-inspired hierarchy that pages information between physical context (prompt tokens) and external storage via function calls.
Core Problem
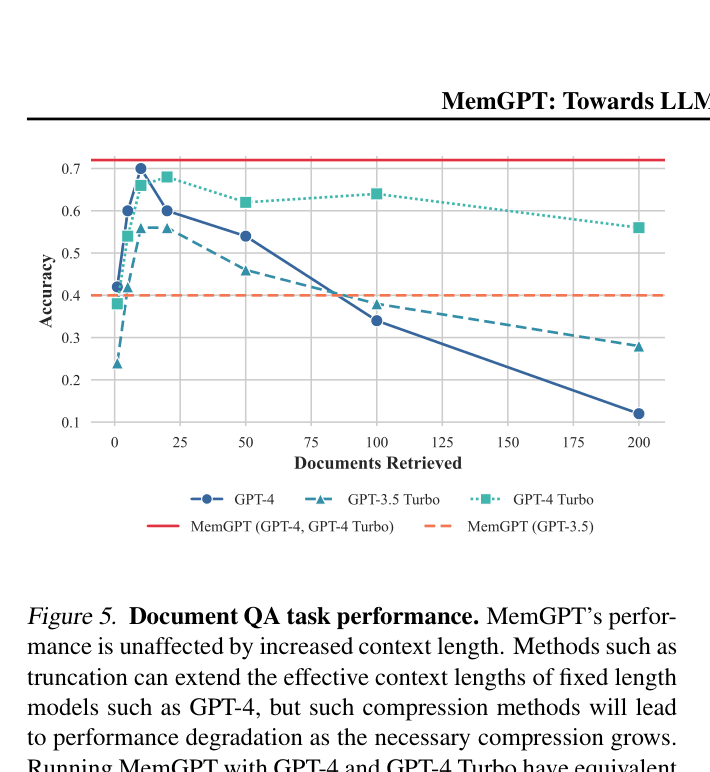
LLMs are constrained by fixed-length context windows, preventing them from effectively handling extended conversations or reasoning over large documents that exceed their input capacity.
Why it matters:
- Directly extending context length incurs quadratic computational costs due to the transformer self-attention mechanism
- Long-context models struggle to utilize additional context effectively, often failing to recall information in the middle of the window ('lost in the middle' phenomenon)
- Conversational agents lack long-term consistency and memory over weeks or months of interaction due to limited history retention
Concrete Example:
In the Deep Memory Retrieval task, a user asks a specific question about a topic discussed in a session five conversations ago. A standard GPT-4 model (limited context) fails to answer correctly (32.1% accuracy) because the relevant history was truncated, whereas MemGPT retrieves the specific detail to answer correctly (92.5% accuracy).
Key Novelty
Virtual Context Management (MemGPT)
- Analogy to Operating Systems: Treats the LLM context window as 'RAM' (limited, fast) and external databases as 'Disk' (unlimited, slow), swapping data between them as needed
- Self-Directed Memory Management: The LLM itself decides when to read/write to memory or evict items via generated function calls, rather than relying on a fixed heuristic
- Interrupt-Driven Control Flow: Uses events (user messages, system alerts like 'memory pressure') to trigger processing, allowing the agent to pause, think, and paginate through results
Architecture
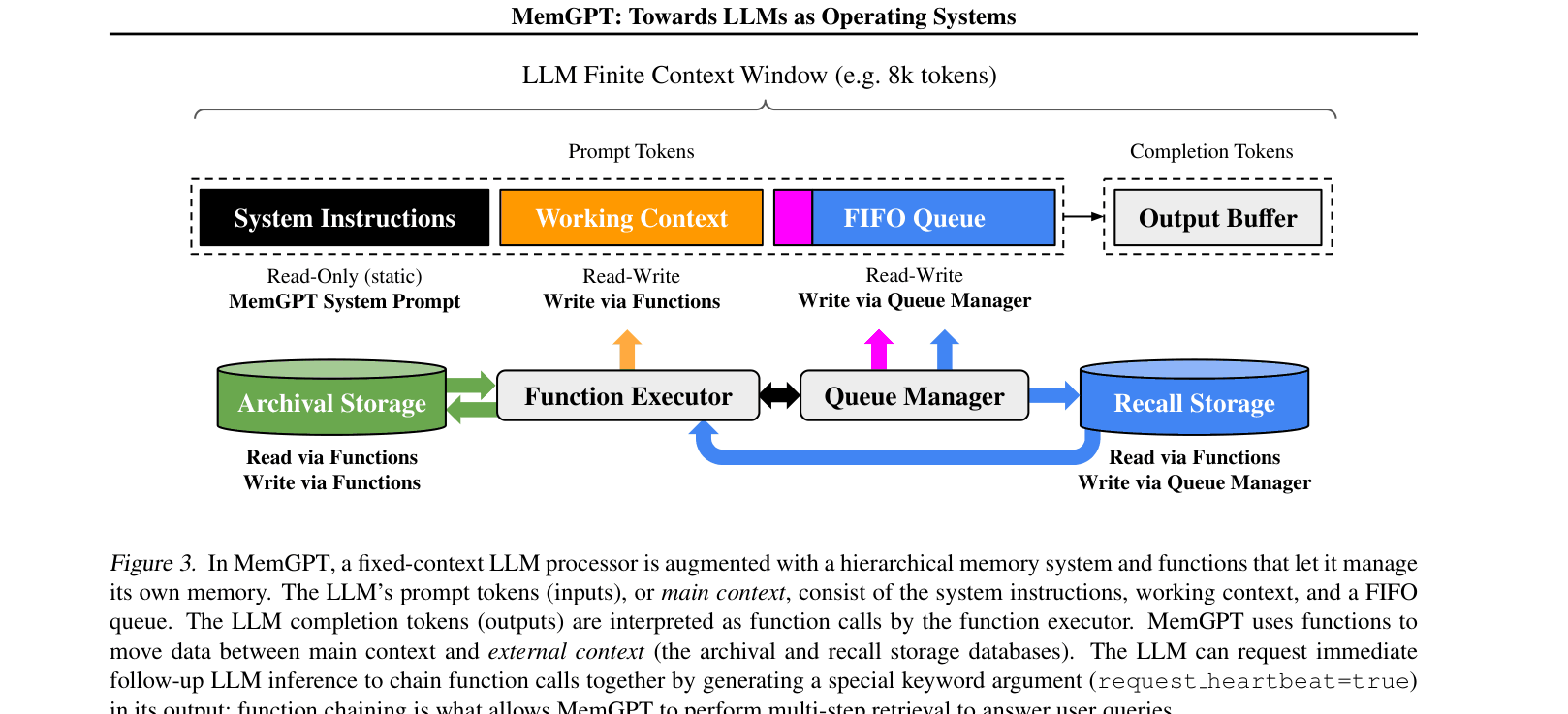
The MemGPT system architecture, illustrating the flow between the Fixed-Context LLM Processor (Main Context) and External Context (Storage).
Evaluation Highlights
- +60.4% accuracy improvement on Deep Memory Retrieval (DMR) task using GPT-4 (92.5% vs 32.1% baseline)
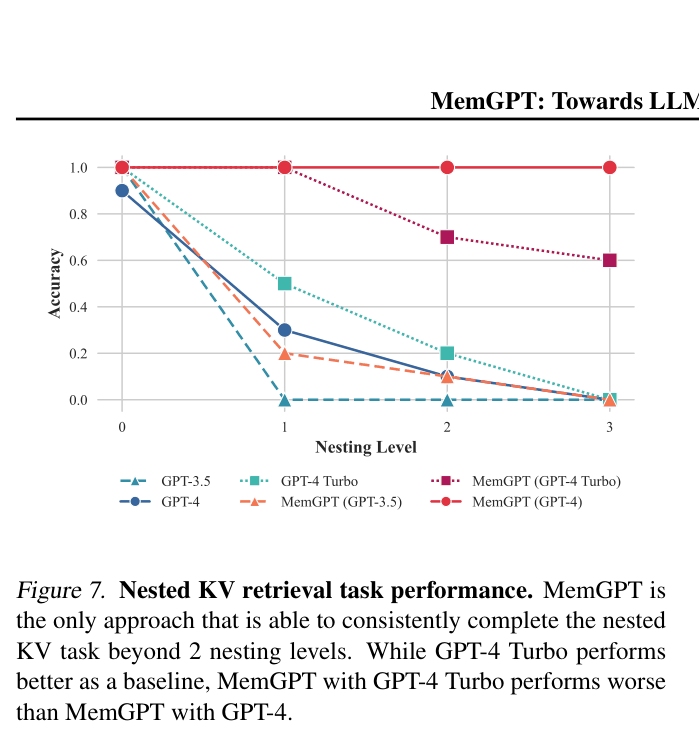
- Consistently solves Nested Key-Value Retrieval with up to 4 nesting levels, whereas GPT-4 and GPT-3.5 fail completely (0% accuracy) after 3 and 1 levels respectively
- Achieves higher persona consistency (0.868 CSIM score) in conversation openers compared to human-generated openers (0.800 CSIM) on the Multi-Session Chat dataset
Breakthrough Assessment
9/10
Introduce a paradigm shift by treating LLMs as OS processors with hierarchical memory. Demonstrated ability to effectively make fixed-context models behave as infinite-context agents is a significant practical leap.