📝 Paper Summary
Multi-call tool use with flexible plan
Invoking internalized APIs
ToolkenGPT represents external tools as special tokens (toolkens) with learnable embeddings, allowing frozen LLMs to select and use massive numbers of tools as easily as generating words.
Core Problem
Existing methods for teaching LLMs to use tools struggle with scalability: fine-tuning is computationally expensive and rigid, while in-context learning cannot handle massive toolsets due to context length limits.
Why it matters:
- Fine-tuning entire LLMs for every new tool is prohibitively costly and risks forgetting general knowledge
- In-context learning fails when hundreds of tools are available because their descriptions exceed the model's context window
- Standard prompts struggle to capture the complex, implicit semantics of tools that require extensive demonstrations to master
Concrete Example:
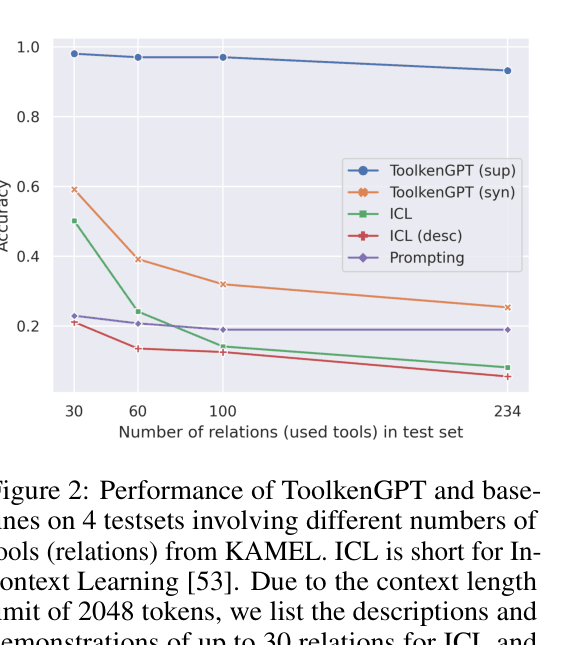
In a knowledge-base QA task with over 200 relations (tools), in-context learning fails because it cannot fit descriptions for all 200 relations into the prompt. Consequently, it achieves low accuracy (~20-30%) compared to ToolkenGPT (~50-95%) which learns embeddings for each relation.
Key Novelty
Representing tools as learnable tokens ('toolkens') in the vocabulary
- Each tool is assigned a specific token embedding ('toolken') that is appended to the LLM's vocabulary, while the rest of the LLM remains frozen
- The model learns to predict these toolkens just like regular words; predicting a toolken triggers a special 'tool mode' to generate arguments
- This decouples tool learning from LLM weights, allowing unlimited tools to be plugged in by simply adding their embeddings
Architecture
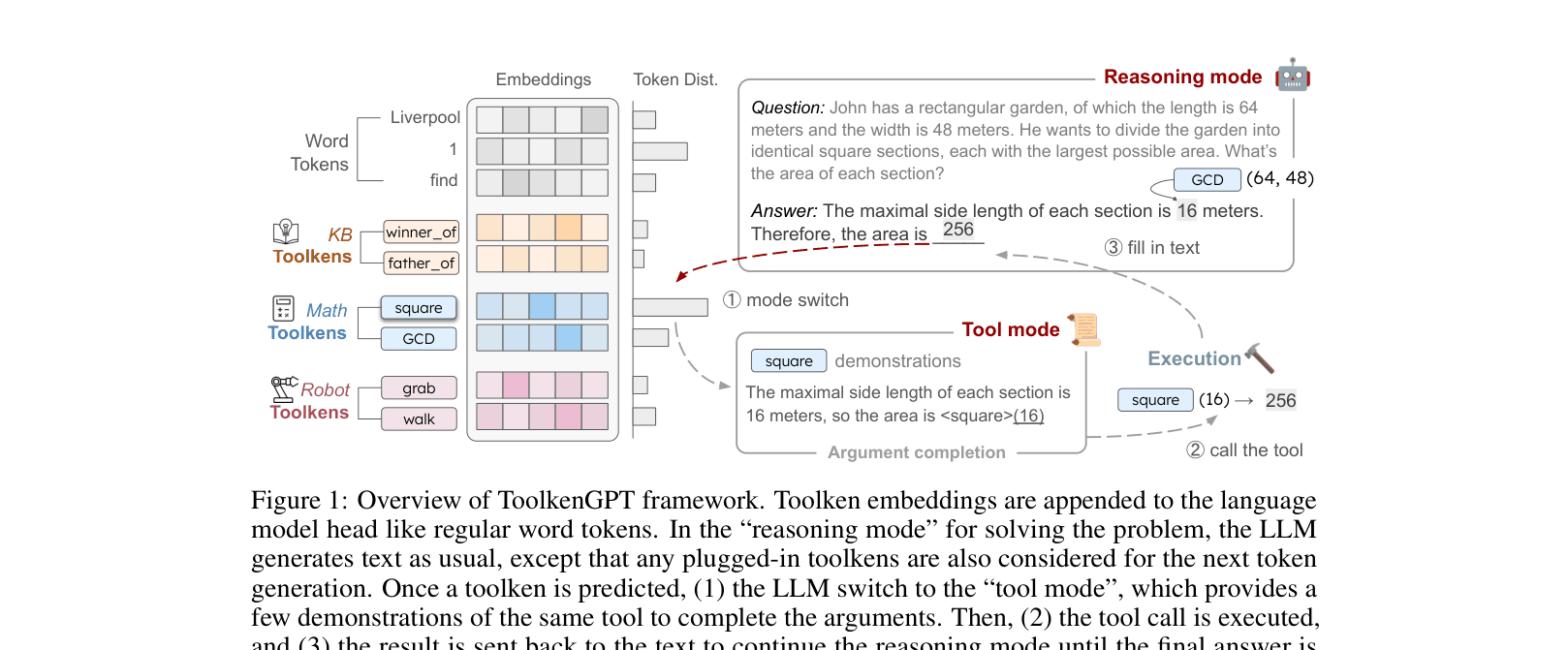
The inference process of ToolkenGPT, illustrating the concatenation of tool embeddings with word embeddings and the switching mechanism between Reasoning Mode and Tool Mode.
Evaluation Highlights
- Achieves up to 95% accuracy on knowledge-based QA with 30 relations using supervised data, compared to ~30% for in-context learning
- Outperforms ReAct by +16% accuracy (0.73 vs 0.57) on complex one-hop numerical reasoning tasks (FuncQA) requiring 13 math tools
- Improves success rate in embodied plan generation (VirtualHome) to 0.68, significantly higher than Grounded Decoding (0.38)
Breakthrough Assessment
8/10
Offers a scalable, efficient solution for the 'massive tools' problem where context windows fail. The idea of 'toolkens' effectively bridges discrete tool use with continuous embedding learning.