📝 Paper Summary
Agentic AI
Planning for LLM Agents
This survey provides a systematic taxonomy of planning methodologies for LLM-based agents, categorizing them into decomposition, selection, external assistance, reflection, and memory, while evaluating representative methods on interactive benchmarks.
Core Problem
Conventional planning methods (symbolic, RL) struggle with flexibility and sample efficiency, while LLMs show promise but lack a unified framework for understanding their planning capabilities.
Why it matters:
- Autonomous agents need robust planning to handle complex, multi-step tasks in real-world environments.
- Existing surveys focus on general LLM capabilities or tool learning, lacking specific depth on the planning mechanisms critical for agent autonomy.
- Researchers need a structured view to identify gaps like hallucinations, inefficiency, and lack of fine-grained evaluation in current agent planning.
Concrete Example:
In a complex task like 'make breakfast', a standard LLM might hallucinate steps or fail to check if ingredients exist. Decomposing this into 'buy eggs', 'cook eggs', etc., and reflecting on failures (e.g., 'no eggs found') improves success rates significantly.
Key Novelty
Five-Category Taxonomy for LLM-Agent Planning
- Task Decomposition: Divide complex goals into sub-goals (Decomposition-First vs. Interleaved).
- Multi-plan Selection: Generate multiple reasoning paths and select the best via search algorithms (e.g., Tree of Thoughts).
- External Planner-Aided: Offload constraint handling to symbolic solvers (PDDL) or neural planners while using LLM for formalization.
- Reflection & Refinement: Iteratively improve plans based on self-generated feedback or environmental signals.
- Memory-Augmented: Retrieve past experiences or domain knowledge to guide current planning (RAG-based vs. Embodied/Fine-tuned).
Architecture
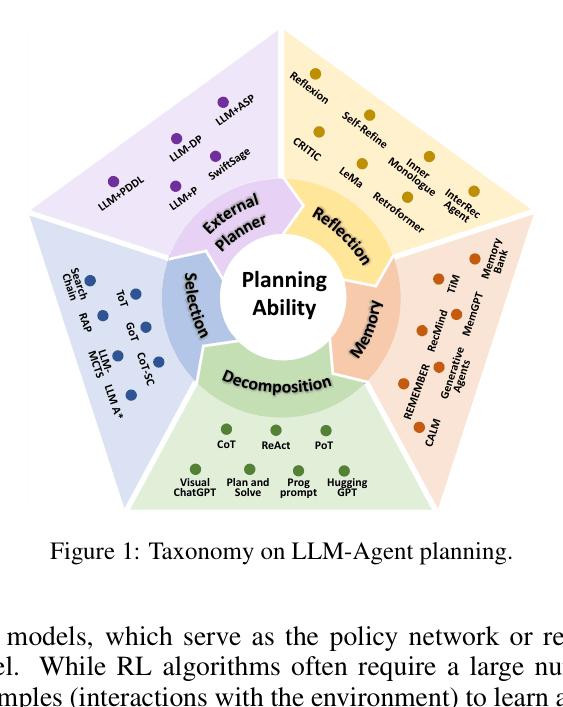
A taxonomy diagram of LLM-Agent planning, dividing the field into five branches: Task Decomposition, Plan Selection, External Module, Reflection, and Memory.
Evaluation Highlights
- +14% success rate improvement for Reflexion over ReAct on ALFWorld (0.71 vs 0.57).
- Reflexion achieves highest success rate (0.71) but incurs highest token expense ($220.17) on ALFWorld compared to baselines.
- ZeroShot-CoT fails significantly on QA tasks (0.01 SR on HotPotQA) compared to few-shot methods (0.32 SR), highlighting the need for examples.
Breakthrough Assessment
7/10
A comprehensive survey that structures a rapidly growing field. While it doesn't propose a new model, its taxonomy and comparative evaluation of existing methods provide valuable insights for researchers.