📝 Paper Summary
Inference Acceleration
Large Vocabulary LLMs
DynaSpec accelerates speculative decoding for large-vocabulary models by dynamically selecting small, context-dependent token clusters for the drafter to predict from, avoiding the cost of full output projections.
Core Problem
As LLM vocabularies scale past 100k tokens, the draft model in speculative decoding becomes bottlenecked by its output projection layer (O(|V|d)), diminishing speedups.
Why it matters:
- Recent scaling laws suggest larger vocabularies improve model performance, but they linearly increase the computational cost of the final layer.
- Existing solutions like static frequency-based shortlisting suppress rare or domain-specific tokens, reducing acceptance rates and limiting speedups on diverse tasks.
- Small draft models are disproportionately affected because the output layer constitutes a larger fraction of their total computation compared to large target models.
Concrete Example:
In a coding task requiring rare syntax tokens, a static top-p% shortlist might exclude these tokens. The drafter fails to propose them, forcing the expensive target model to generate them, thereby reverting latency to standard decoding speeds.
Key Novelty
Context-Dependent Dynamic Shortlisting via Cluster Routing
- Partitions the vocabulary into coarse clusters based on semantic similarity of LM-head weights.
- Uses a lightweight router to predict relevant clusters for the current context, restricting the drafter's computation to this dynamic subset.
- Employes a position-aware budget that allocates larger shortlists to early tokens and fewer to later ones to balance acceptance rate with computational cost.
Architecture
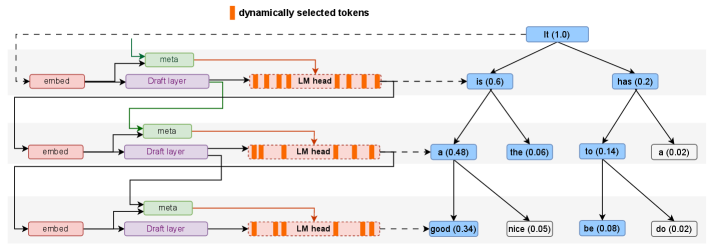
The DynaSpec inference step showing parallel execution of the Router and Drafter.
Evaluation Highlights
- Achieves up to 2.23x throughput gain on Llama-3-8B compared to 1.91x for static frequency-based approaches.
- Recovers 98.4% of full-vocabulary mean accepted length for Llama-3-8B, significantly outperforming fixed-shortlist baselines which only reach 93.6%.
- Improves mean accepted length from 3.64 to 3.83 tokens/step on Llama-3-8B compared to static shortlists, while using a smaller average shortlist size (~28K vs 32K).
Breakthrough Assessment
8/10
DynaSpec effectively addresses a growing bottleneck in LLM inference (vocabulary scaling) where static methods fail. The combination of dynamic routing and position-aware budgeting offers a robust trade-off between speed and accuracy.