📝 Paper Summary
Survey of RAG Paradigms
Evaluation of RAG Systems
This survey systematizes Retrieval-Augmented Generation (RAG) into three paradigms—Naive, Advanced, and Modular—and provides a comprehensive review of retrieval, generation, and augmentation techniques alongside evaluation frameworks.
Core Problem
LLMs suffer from hallucinations, outdated knowledge, and non-transparent reasoning, while existing RAG research is fragmented without a systematic synthesis of its evolution and evaluation methods.
Why it matters:
- Rapid growth in RAG research (over 100 studies) lacks a unified taxonomy to guide researchers
- Current reviews often focus on methods but neglect the critical aspect of how to evaluate RAG systems effectively
- Practitioners need clear guidance on choosing between RAG and fine-tuning for specific applications
Concrete Example:
When a user asks ChatGPT about a recent news event, the model fails due to training data cutoffs. A Naive RAG approach might retrieve irrelevant chunks due to poor indexing, while an Advanced RAG system would use query rewriting and re-ranking to provide accurate, up-to-date context.
Key Novelty
Tripartite RAG Taxonomy (Naive, Advanced, Modular)
- Categorizes RAG evolution into three distinct stages: 'Naive' (simple retrieve-read), 'Advanced' (pre/post-retrieval optimization), and 'Modular' (flexible architectures with routing, memory, and specialized modules)
- Deconstructs RAG into three core technical foundations: Retrieval, Generation, and Augmentation, analyzing synergies between them
- Compiles a comprehensive evaluation framework covering 26 tasks and nearly 50 datasets to standardize RAG assessment
Architecture
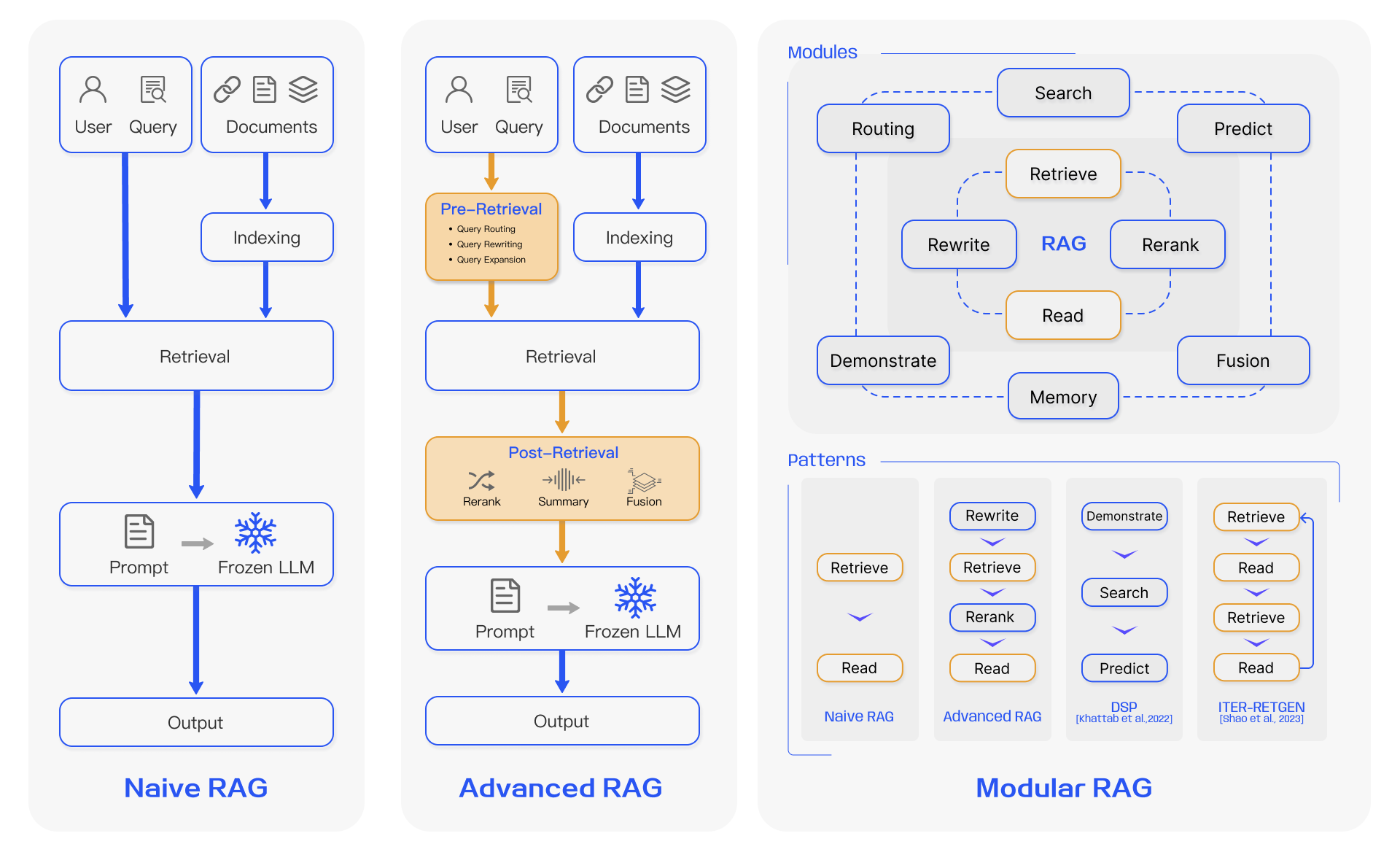
The evolution of RAG paradigms: Naive RAG, Advanced RAG, and Modular RAG
Evaluation Highlights
- Categorizes over 100 RAG studies into a unified evolutionary framework
- Summarizes evaluation methods across 26 downstream tasks and nearly 50 datasets
- Establishes a comparative analysis between RAG and Fine-Tuning, highlighting RAG's superiority in dynamic environments and interpretability
Breakthrough Assessment
9/10
A foundational survey that defines the taxonomy for the field. While it doesn't propose a new model, its classification of 'Naive, Advanced, Modular' RAG has become the standard vocabulary for researchers and practitioners.