📝 Paper Summary
Hallucination suppression
Knowledge internalization
R-Tuning fine-tunes models to refuse questions beyond their parametric knowledge by first identifying the knowledge gap between training data and the model's internal beliefs, then training on refusal-augmented data.
Core Problem
Standard instruction tuning forces models to complete every answer regardless of whether they possess the relevant knowledge, teaching them to hallucinate rather than admit ignorance.
Why it matters:
- Forcing completion on unknown data causes hallucination, as models learn to guess rather than express uncertainty
- There is a significant gap between the knowledge in human-labeled instruction datasets and the parametric knowledge acquired during pre-training
- Models lacking the ability to say 'I don't know' are unreliable in high-stakes domains where factual accuracy is critical
Concrete Example:
A model may not know the capital of a specific country but is forced to output a city name during standard fine-tuning. R-Tuning identifies this gap and trains the model to output 'I am unsure' instead of a hallucinated city.
Key Novelty
Refusal-Aware Instruction Tuning (R-Tuning)
- Identifies 'uncertain' data by checking if the pre-trained model can answer the training questions correctly before fine-tuning
- Constructs a 'refusal-aware' dataset by appending uncertainty markers (e.g., 'I am unsure') to labels the model got wrong, and certainty markers to those it got right
- Treats refusal as a meta-skill that generalizes across tasks, allowing the model to estimate its own uncertainty better than post-hoc methods
Architecture
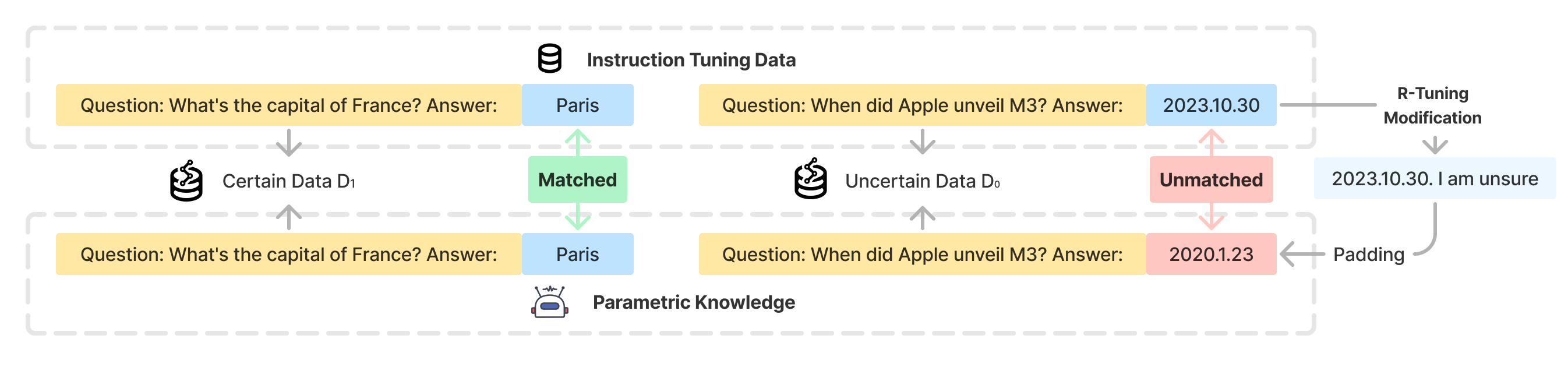
The R-Tuning process: (1) Measuring knowledge gap by comparing model prediction to label, (2) Constructing refusal-aware data by appending 'I am sure/unsure', (3) Fine-tuning.
Evaluation Highlights
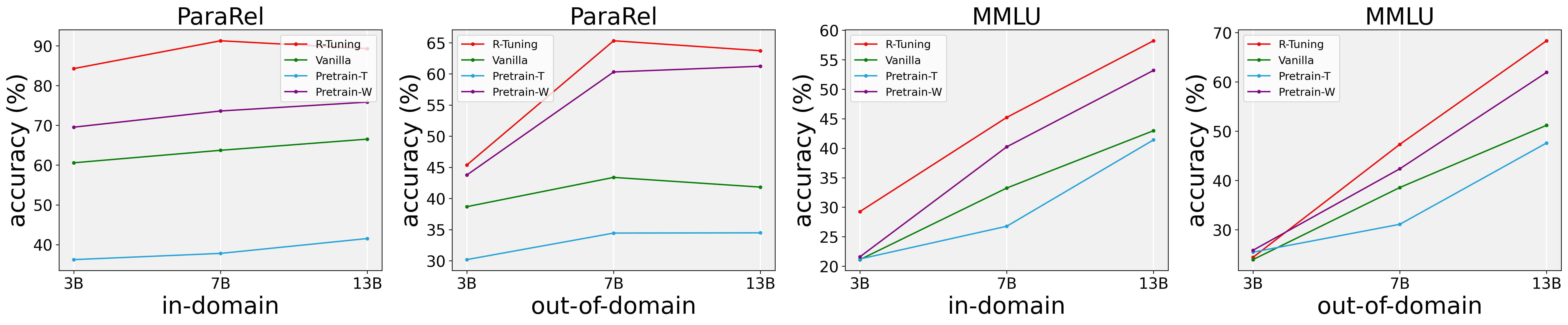
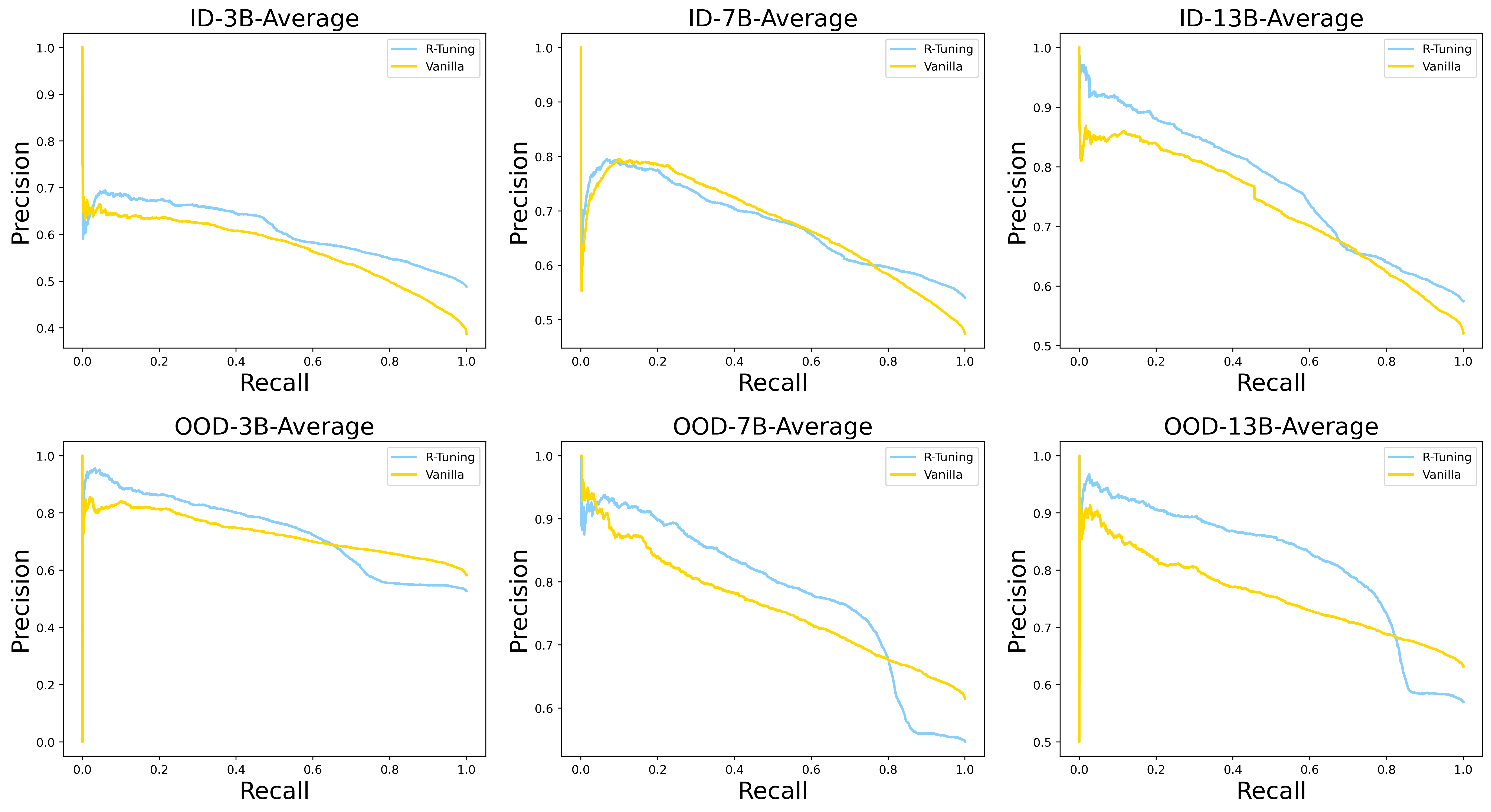
- Outperforms Vanilla fine-tuning on MMLU (in-domain) by +12.3 points in Average Precision (AP) using OpenLLaMA-3B
- Achieves higher AP scores on out-of-domain datasets (e.g., +5.8 points on ParaRel OOD) compared to vanilla tuning, showing generalized refusal skills
- Surprisingly, learning uncertainty during training yields better calibration than simply filtering by uncertainty at test time
Breakthrough Assessment
7/10
Simple yet effective conceptual shift: aligning fine-tuning data with the model's actual knowledge boundary rather than forcing all labels. Strong generalization results for refusal skills.