📝 Paper Summary
Memory organization
Knowledge internalization
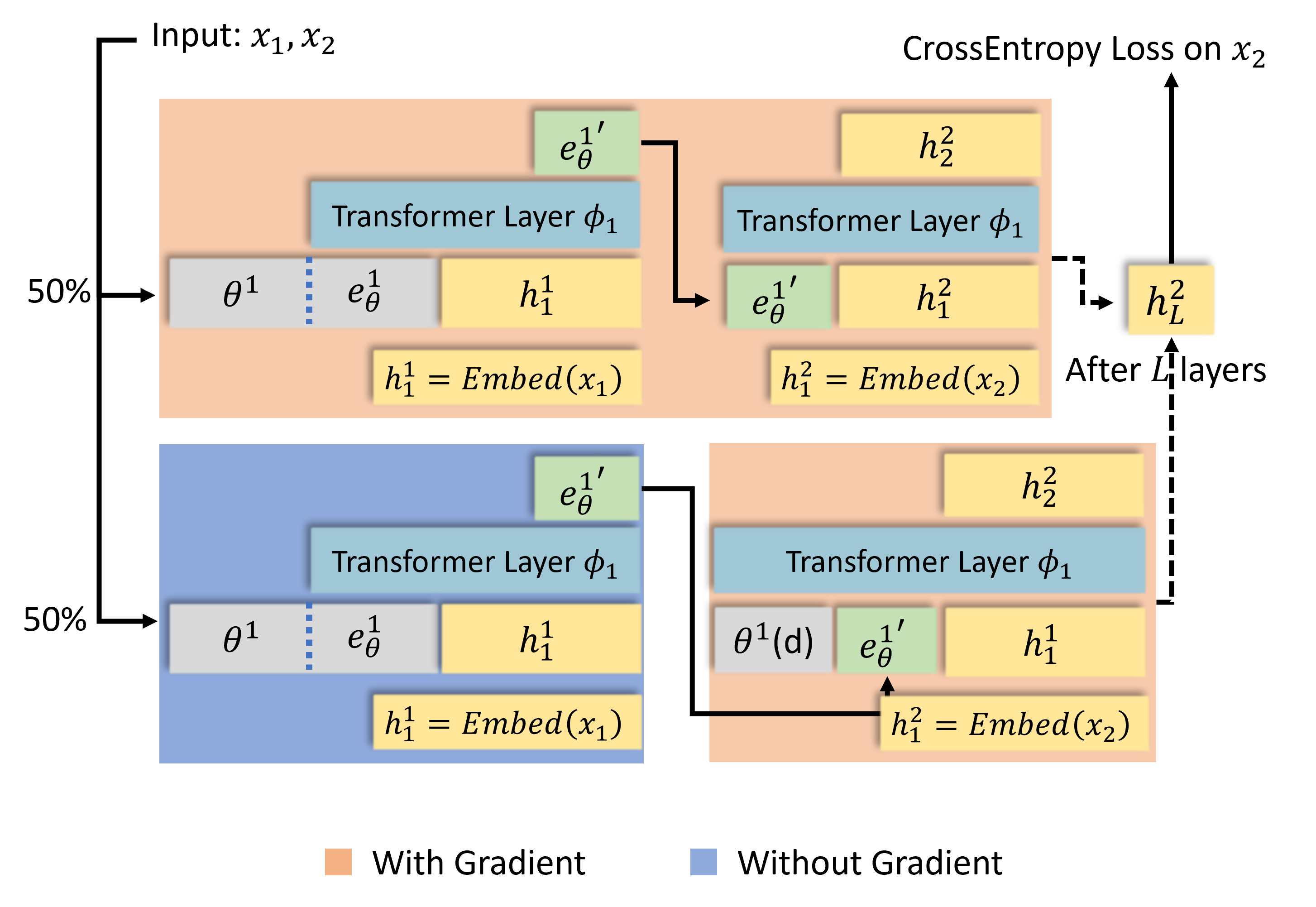
MemoryLLM incorporates a fixed-size, self-updatable memory pool into the transformer's latent space, allowing the model to efficiently ingest new knowledge and slowly forget old information without requiring retraining.
Core Problem
Existing LLMs are static after deployment, making it difficult to inject new knowledge without expensive retraining, while retrieval-based methods suffer from storage redundancy and long-context methods are limited by finite context windows.
Why it matters:
- Complex reasoning tasks require massive up-to-date knowledge that static models lack
- Retrieval-based methods (RAG) face logistical issues managing ever-expanding repositories and high redundancy
- Long-context methods eventually hit context limits and suffer from high computational costs
Concrete Example:
When an LLM needs to learn a long sequence of new facts (like a developing news story or a user's conversation history), RAG stores every sentence (high redundancy), while MemoryLLM compresses this into a fixed set of vectors. Standard LLMs would either run out of context window or require full fine-tuning to 'memorize' the text.
Key Novelty
Latent Space Memory Pool with Self-Update Mechanism
- Embeds a large, fixed-size memory pool (trainable vectors) directly within each transformer layer, distinct from the static model weights
- Uses the model's own attention mechanism to 'read' new text and update the memory pool by compressing input tokens into memory tokens
- Implements an exponential forgetting strategy where old memory tokens are randomly dropped to make space for new ones, ensuring the memory size remains constant
Architecture

Overview of MemoryLLM during generation and self-update. (a) Generation: The Transformer attends to both input text tokens and the fixed-size memory pool (θ) to generate output. (b) Self-Update: New context is processed by the Transformer along with a subset of the memory pool to generate new memory tokens, which are then integrated into θ using a drop-and-shift mechanism.
Evaluation Highlights
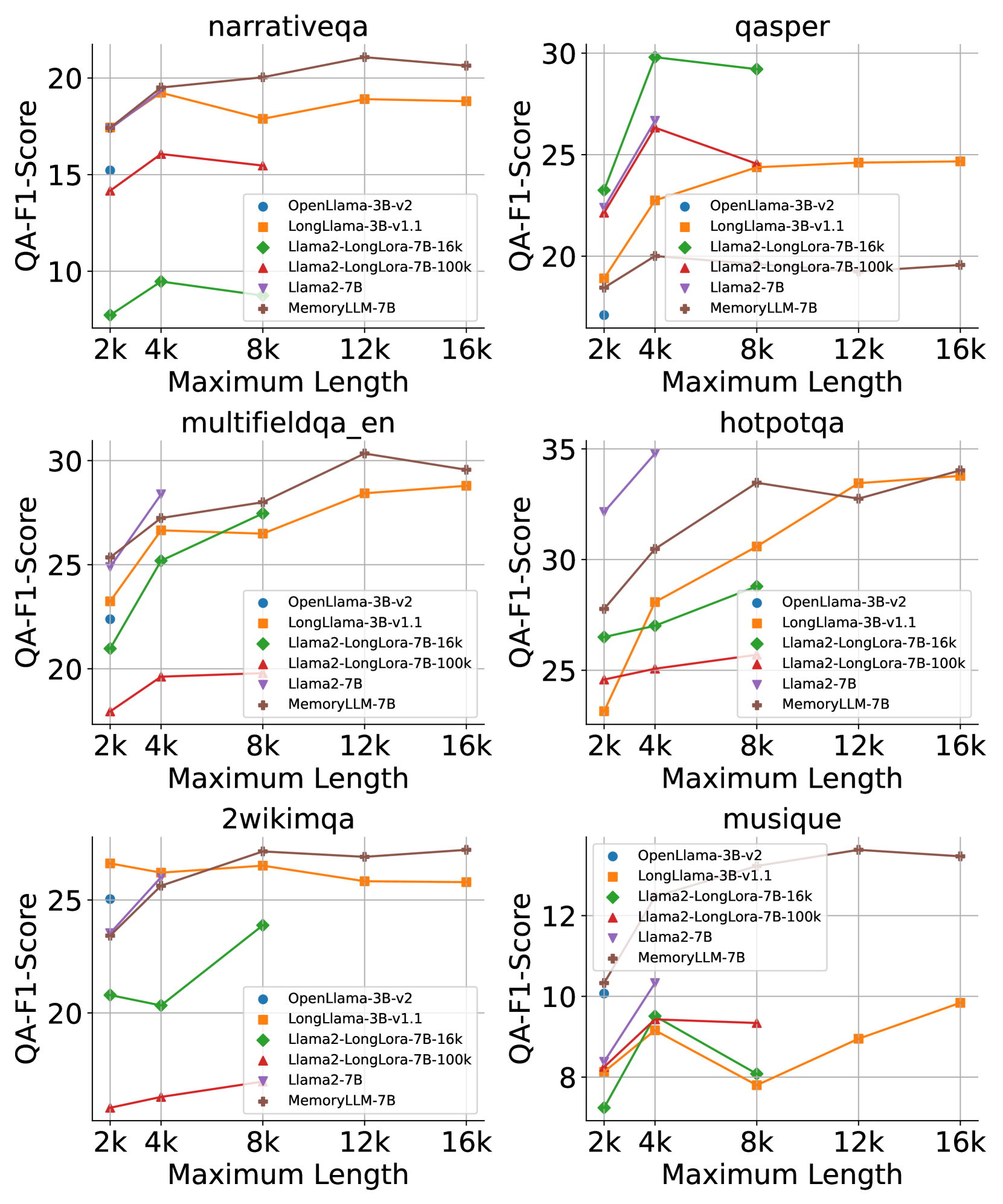
- +13.6% accuracy improvement on the zsRE model editing benchmark compared to the strong baseline Me-Llama (7B)
- Maintains performance (integrity) after nearly 1 million memory update steps, whereas standard fine-tuning often degrades general capabilities
- Achieves 96.6% accuracy on a custom 'Knowledge Retention' task for retrieving facts injected 50 steps ago, significantly outperforming long-context baselines like LongChat (20.0%)
Breakthrough Assessment
8/10
Proposes a novel architecture where memory is part of the latent space rather than an external database or extended context. The ability to handle 1M+ updates without degradation is a significant step toward lifelong learning agents.