📊 Experiments & Results
Evaluation Setup
Pretraining followed by zero-shot or few-shot evaluation on downstream tasks
Benchmarks:
- NaturalQuestions (Factual QA)
- TriviaQA (Factual QA)
- HotpotQA (Multi-hop QA)
- MMLU (General Knowledge)
- HumanEval (Coding)
Metrics:
- Exact Match (EM)
- F1 score
- Pass-at-1
- Negative Log-Likelihood (NLL)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Memory layers significantly outperform dense baselines on factual QA tasks. | ||||
| NaturalQuestions | Exact Match | Not reported in the paper | Not reported in the paper | Not reported in the paper |
Experiment Figures
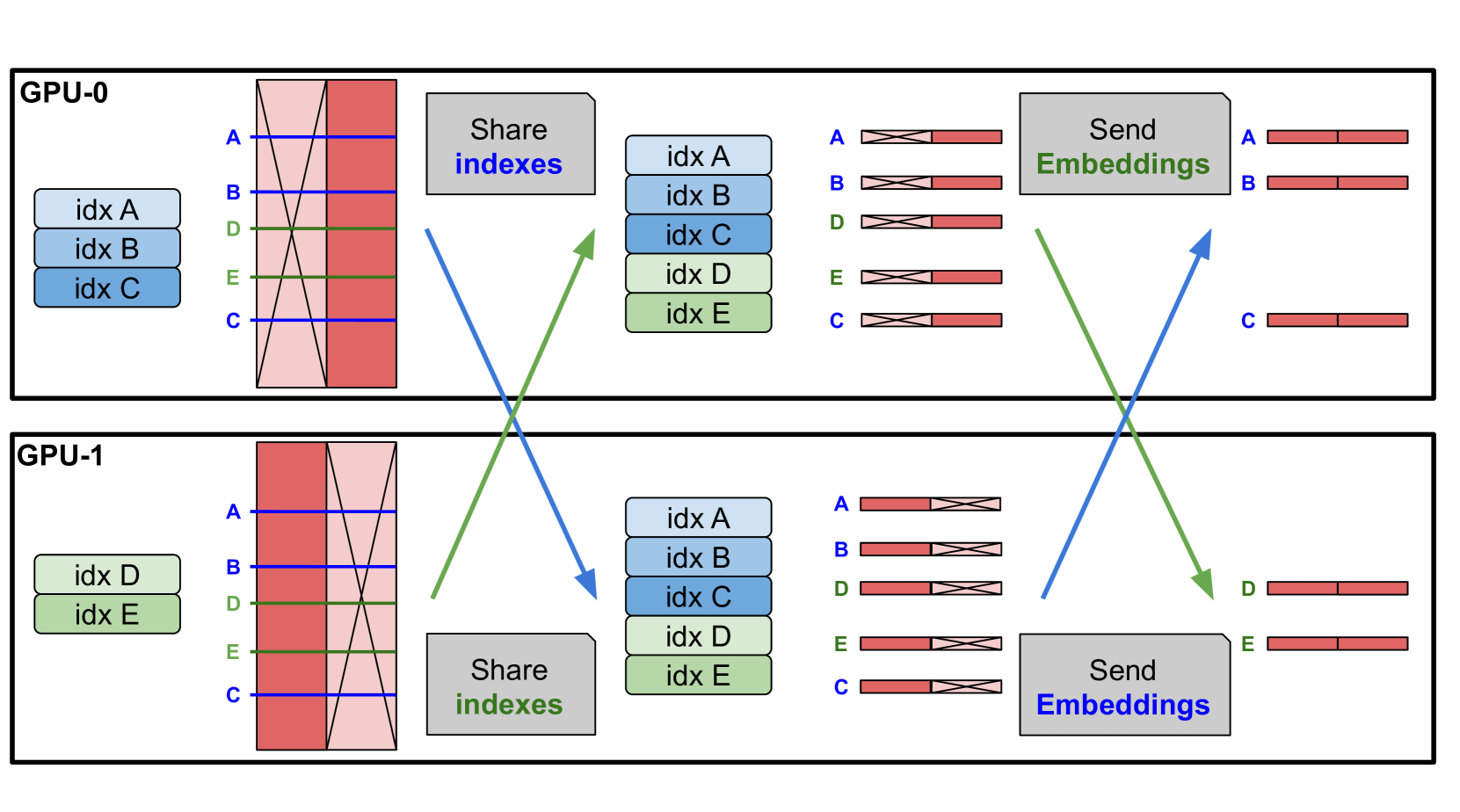
Parallel memory lookup and aggregation across GPUs
Main Takeaways
- Memory augmented models outperform dense models with >2x computation budget on downstream tasks.
- Gains are most pronounced on factual tasks (NaturalQuestions, TriviaQA), confirming the hypothesis that memory layers store associations efficiently.
- Memory layers outperform MoE models when matched for compute and parameter size, especially on factuality.
- Scaling laws hold: performance improves with memory size up to 128B parameters.
- Sharing memory parameters across multiple layers improves performance compared to single-layer memory, but replacing too many FFN layers degrades it.