📝 Paper Summary
Multi-agent
Prompt engineering
Scaffolding techniques
Meta-prompting transforms a single LM into a conductor that decomposes complex tasks and dynamically assigns subtasks to independent instances of itself acting as specialized experts.
Core Problem
Standard Large Language Models (LLMs) often struggle with complex, multi-faceted tasks, generating inaccurate or conflicting responses when trying to solve everything in a single pass.
Why it matters:
- Current scaffolding methods (like Chain-of-Thought or expert prompting) often require static, task-specific instructions, limiting their flexibility.
- Detailed manual prompting for every unique query is cumbersome for users.
- Single-pass generation lacks the critical verification and diverse perspectives needed for robust problem-solving.
Concrete Example:
For a task like 'Write a Shakespearean sonnet about selfies,' a standard model might miss constraints or style. Meta-prompting would break this down: one expert to draft the content, another to verify the rhyme scheme (ABAB CDCD...), and another to critique the style, all orchestrated by the main model.
Key Novelty
Meta-Prompting (Conductor-Expert Ensemble)
- Uses a single LM to play two distinct roles: a 'Conductor' (Meta Model) that plans and coordinates, and various 'Experts' that execute specific sub-tasks.
- The Conductor maintains the high-level history and dynamically generates fresh instructions for Experts, who have no memory of the full context to ensure independent verification.
- Task-agnostic design: The same high-level meta-prompt works across diverse domains (math, poetry, coding) without manual tuning.
Architecture
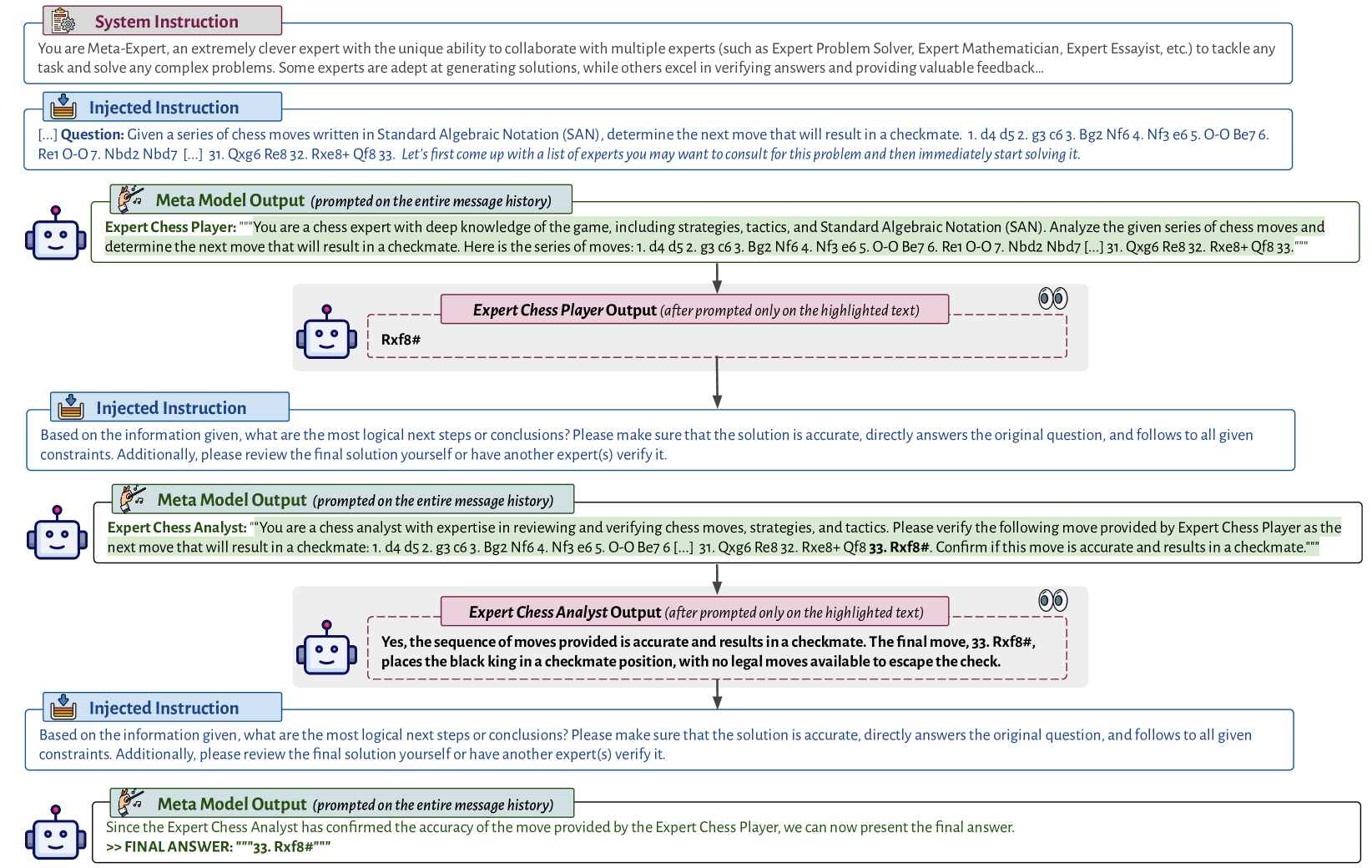
An illustrative visualization of a meta-prompting session (Conductor-Expert interaction loop).
Evaluation Highlights
- Surpasses standard prompting by 17.1%, expert prompting by 17.3%, and multi-persona prompting by 15.2% when averaged across all tasks (Game of 24, Python Puzzles, etc.).
- Achieves state-of-the-art zero-shot performance on the Game of 24 task using GPT-4.
- Demonstrates effective integration with external tools (Python interpreter) to solve complex programming puzzles.
Breakthrough Assessment
8/10
Strong empirical gains using a purely prompt-based, zero-shot scaffolding technique. It effectively generalizes the concept of 'mixture of experts' to inference-time prompting without model training.