📝 Paper Summary
Prompt Engineering
Complex Reasoning
Retrieval-Augmented Generation (RAG)
Step-Back Prompting improves LLM reasoning on complex tasks by first prompting the model to identify high-level concepts or principles, then using that abstraction to guide the final solution.
Core Problem
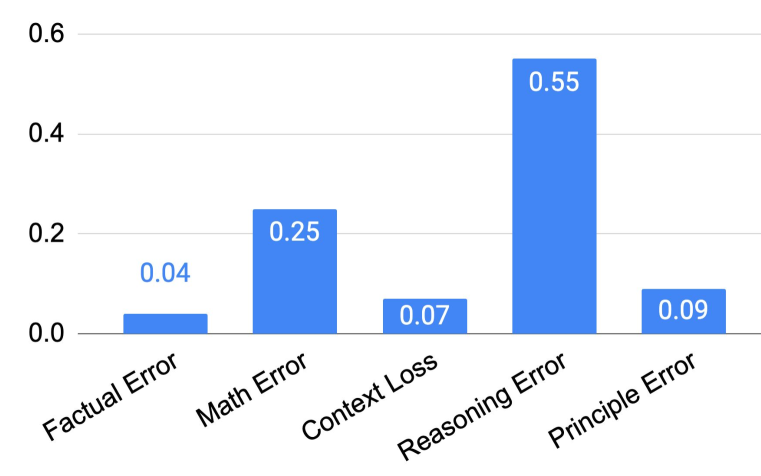
Complex reasoning tasks often contain excessive details that distract LLMs, causing them to miss relevant facts or hallucinate intermediate steps when reasoning directly.
Why it matters:
- State-of-the-art LLMs (like PaLM-2L, GPT-4) still struggle with multi-step reasoning in STEM and knowledge-intensive domains, often achieving only ~40% accuracy on hard tasks.
- Direct prompting or Chain-of-Thought (CoT) can lead to error accumulation in intermediate steps, especially when specific details overwhelm the model's retrieval or reasoning logic.
Concrete Example:
When asked 'Estella Leopold went to which school between Aug 1954 and Nov 1954?', a standard LLM fails to retrieve the specific date-bound fact. Step-Back Prompting first asks 'What was Estella Leopold’s education history?', retrieving the full history to correctly infer the specific answer.
Key Novelty
Step-Back Prompting
- Decomposes the reasoning process into two stages: Abstraction and Reasoning.
- First, prompts the LLM to generate a 'step-back question' about a higher-level concept or principle (e.g., Physics laws or general history) relevant to the specific query.
- Second, uses the answer to this high-level question as grounding context to reason about the original specific detailed question.
Architecture
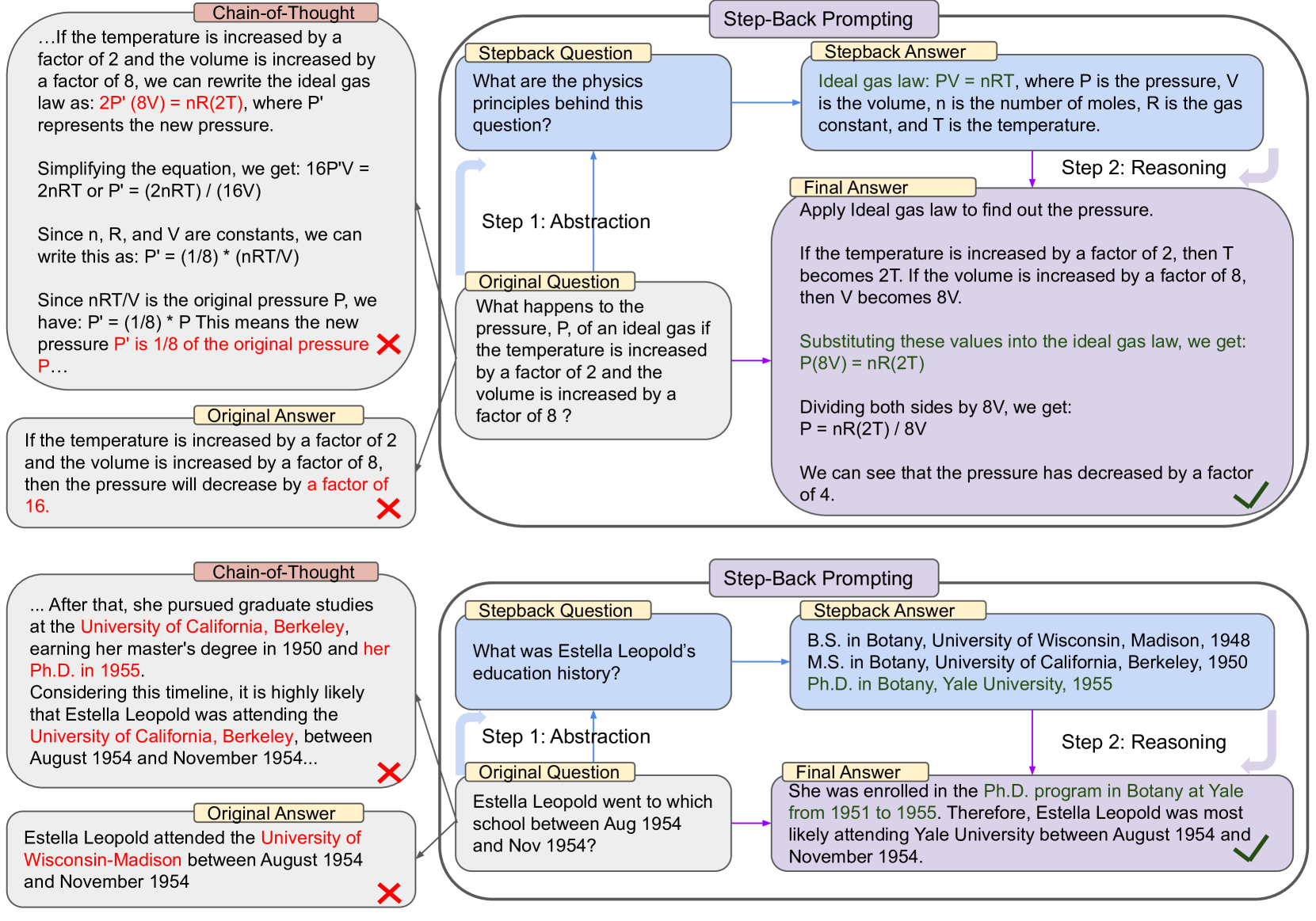
Conceptual workflow of Step-Back Prompting vs. Chain-of-Thought
Evaluation Highlights
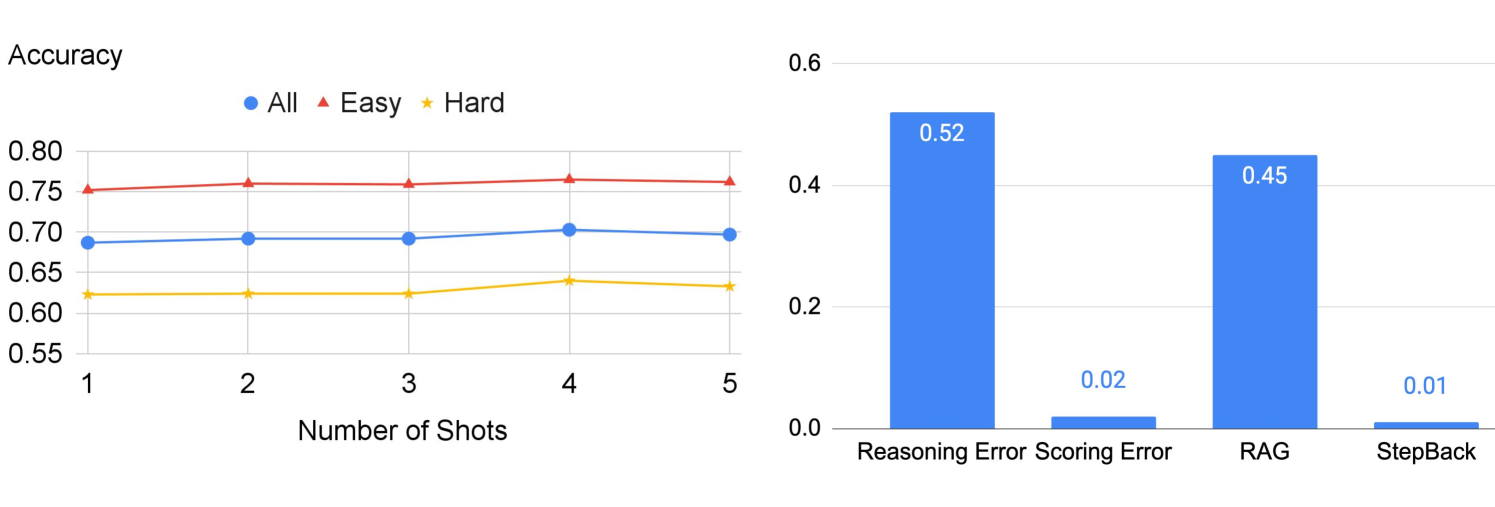
- +27% accuracy improvement on TimeQA over PaLM-2L baseline (from 41.5% to 68.7%) using Step-Back + RAG.
- +7% and +11% improvement on MMLU Physics and Chemistry respectively with PaLM-2L compared to standard prompting.
- Outperforms GPT-4 on TimeQA Hard subset (62.3% vs 42.6%) when using PaLM-2L with Step-Back + RAG.
Breakthrough Assessment
8/10
Simple yet highly effective prompting technique that yields massive gains (up to 27%) on hard reasoning tasks where CoT fails, requiring no model training.