📝 Paper Summary
Language Model Reasoning
Self-Improvement
Reasoning in Unstructured Text
Quiet-STaR trains language models to generate internal thoughts at every token position to better predict future text, learning to reason from unstructured web data without explicit supervision.
Core Problem
Existing reasoning methods (like STaR or Chain-of-Thought) rely on curated QA datasets or explicit prompts, limiting scale and failing to capture the implicit reasoning present between lines of general text.
Why it matters:
- Much of text's meaning is implicit; understanding it requires inferring unstated rationales, which current LMs struggle to learn solely from next-token prediction
- Relying on curated QA datasets limits generalizability and scale compared to learning directly from the vast diversity of unstructured internet text
Concrete Example:
In a math proof, steps are often skipped. A standard LM might hallucinate the next line. Quiet-STaR generates a hidden thought 'To prove A=B, show A subset B and B subset A' before predicting the text 'The first of these...', effectively planning the continuation.
Key Novelty
Generalizing STaR to unstructured text via token-wise parallel thought generation
- Analogy: Instead of only thinking when asked a specific question (like STaR), the model learns to 'talk to itself' quietly between every word it reads to predict what comes next better
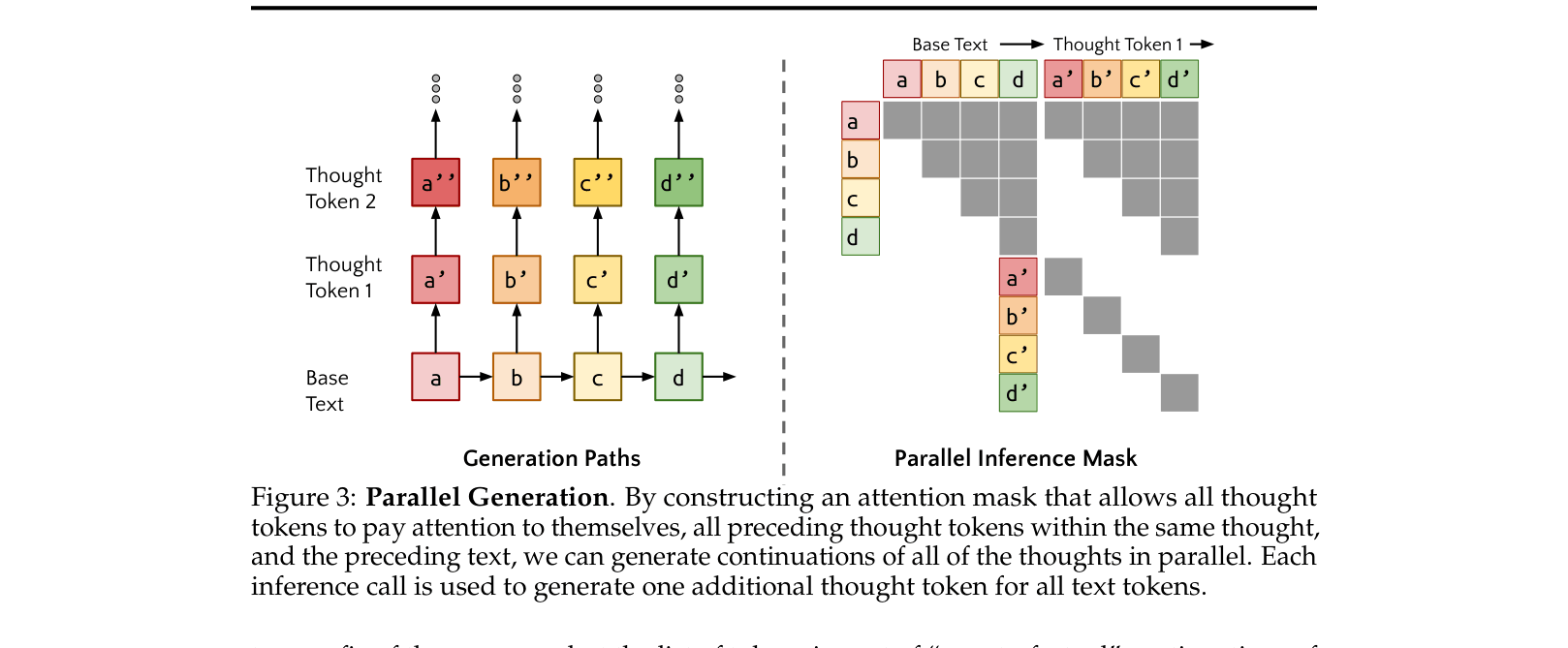
- Uses a parallel sampling algorithm to efficiently generate thoughts for every token in a batch simultaneously, avoiding the massive cost of sequential thought generation
Architecture
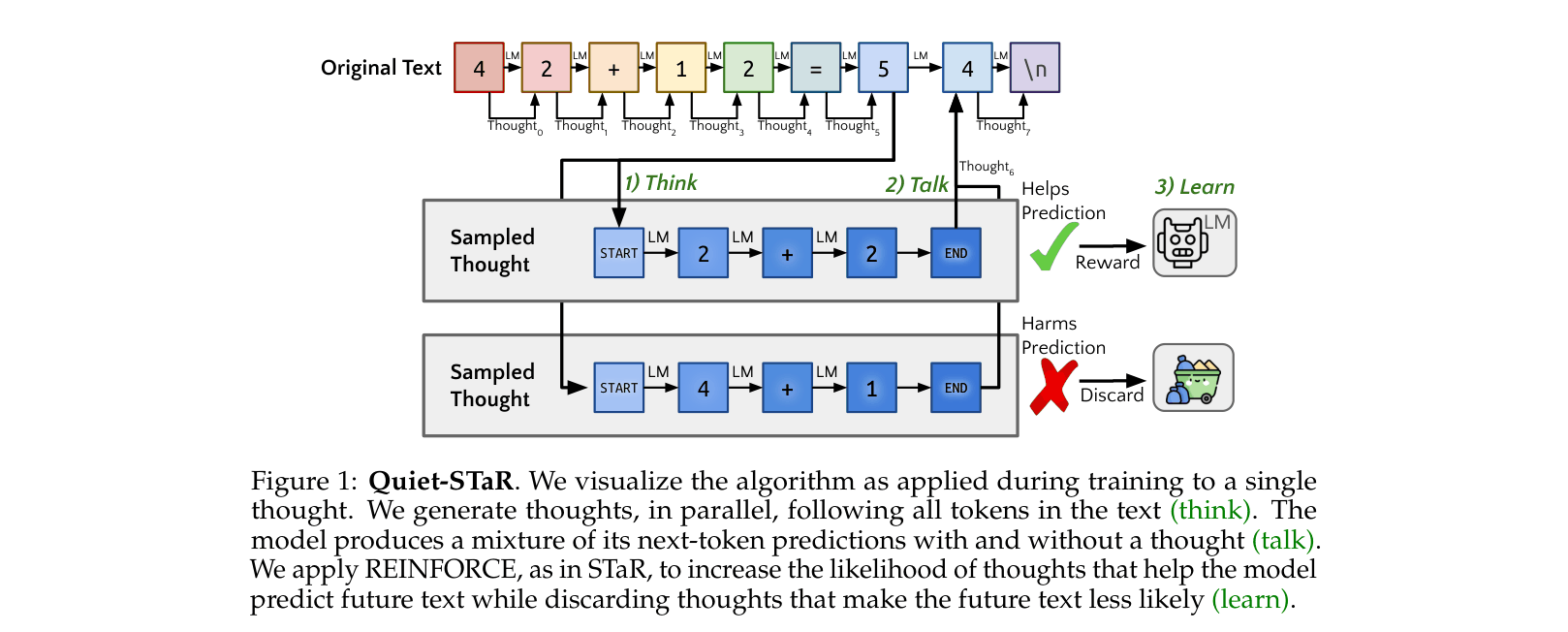
Conceptual overview of the Quiet-STaR training loop: generating thoughts in parallel (Think), mixing predictions (Talk), and updating based on future text probability (Learn).
Evaluation Highlights
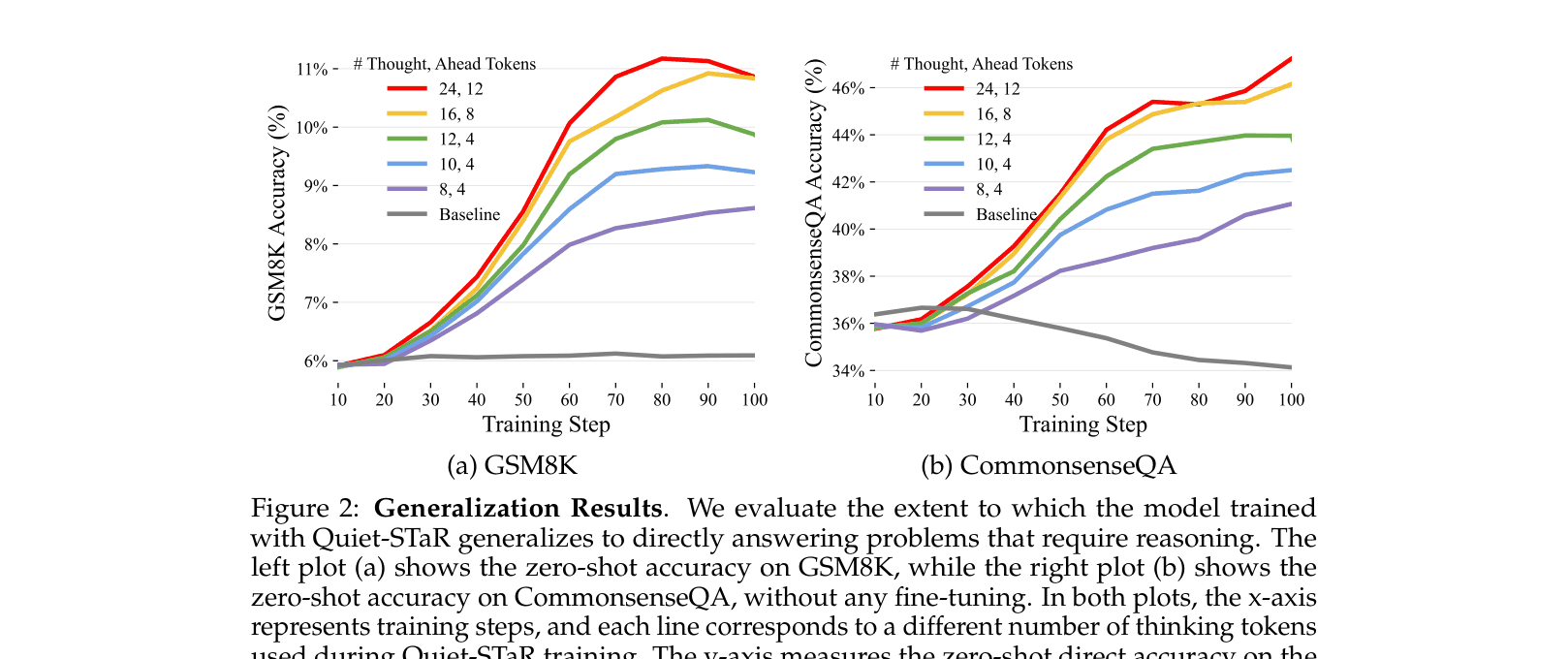
- +10.9% zero-shot accuracy improvement on CommonsenseQA (36.3% -> 47.2%) without any fine-tuning on the task
- +5.0% zero-shot accuracy improvement on GSM8K (5.9% -> 10.9%) compared to the base model
- Performance consistently scales with the length of internal thoughts, validating that the model is effectively using the additional compute to reason
Breakthrough Assessment
9/10
A significant conceptual leap: moving from supervised/prompted reasoning to unsupervised, ubiquitous reasoning learned from raw text. The method is computationally heavy but demonstrates that reasoning patterns can be learned purely from language modeling objectives.