📝 Paper Summary
LLM Alignment
Reinforcement Learning from AI Feedback (RLAIF)
A language model iteratively trains itself by generating its own instructions and candidate responses, then acting as its own reward model to evaluate and select the best responses for fine-tuning.
Core Problem
Standard alignment methods like RLHF rely on frozen reward models trained from static human data, which bottlenecks performance and prevents the reward model from improving alongside the LLM.
Why it matters:
- Human preference data is expensive and limited in quantity and quality, restricting model growth.
- Frozen reward models cannot adapt or improve during training, capping the 'ceiling' of alignment performance.
- Separating reward modeling from instruction following hinders the transfer of capabilities between these related tasks.
Concrete Example:
In standard RLHF, a reward model trained on human data might rate a mediocre response as 'good' forever. A Self-Rewarding model, however, improves its judgment over iterations, eventually recognizing that response as 'mediocre' and demanding higher quality, thus pushing the generation capabilities further.
Key Novelty
Iterative Self-Rewarding Loop
- The model plays two roles: an instruction follower that generates responses, and a judge that scores those responses.
- Crucially, the 'judge' capability is updated in every iteration, meaning the reward mechanism improves simultaneously with the generation mechanism.
- This creates a positive feedback loop where better instruction following leads to better reward modeling, which in turn enables better training data generation.
Architecture
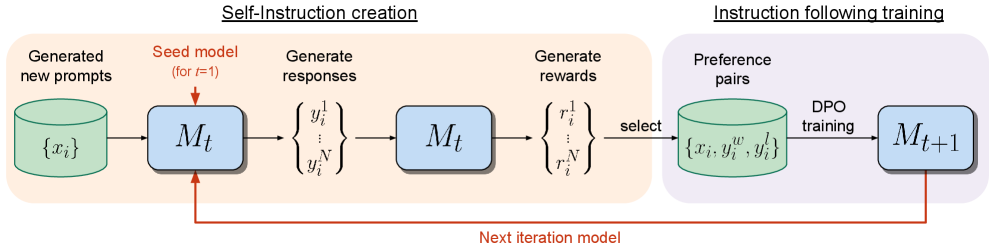
The Self-Rewarding Language Model training pipeline.
Evaluation Highlights
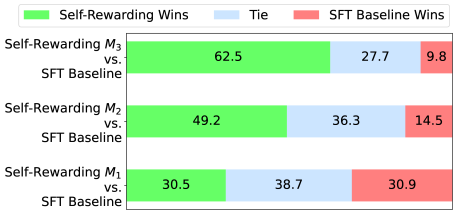
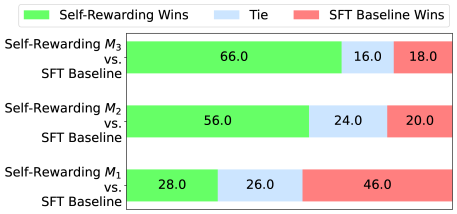
- +20.44% win rate against GPT-4 Turbo on AlpacaEval 2.0 after 3 iterations (starting from 9.94%).
- Outperforms Claude 2, Gemini Pro, and GPT-4 0613 on the AlpacaEval 2.0 leaderboard.
- Reward modeling ability improves during training: pairwise accuracy with human rankings increases from 78.7% (Iteration 1) to 81.7% (Iteration 3).
Breakthrough Assessment
9/10
Significant step toward superhuman agents by removing the human-data bottleneck. Shows for the first time that a model's reward-modeling capability can self-improve alongside its generation capability without external labels.