📝 Paper Summary
Mathematical reasoning
Reward modeling
Process supervision
Process supervision (rewarding individual reasoning steps) significantly outperforms outcome supervision (rewarding final answers) for training reliable reward models in complex mathematical reasoning.
Core Problem
Large language models often produce logical mistakes and hallucinations in multi-step reasoning tasks, and outcome-based feedback is insufficient for precise credit assignment.
Why it matters:
- Single logical errors can derail entire solutions in complex domains like math
- Outcome supervision (checking only the final answer) provides sparse feedback and struggles with credit assignment
- Models trained on outcomes may learn to reach correct answers via incorrect reasoning (misalignment)
- Human feedback is expensive, making efficient data collection strategies critical
Concrete Example:
A model might output a solution that makes a calculation error in step 3 but accidentally arrives at the correct final answer. An outcome-supervised model would label this 'correct', reinforcing bad logic. A process-supervised model would flag step 3 as incorrect.
Key Novelty
Large-Scale Process Supervision with Active Learning
- Train a Process-supervised Reward Model (PRM) using a massive dataset (PRM800K) of 800,000 human-labeled intermediate steps
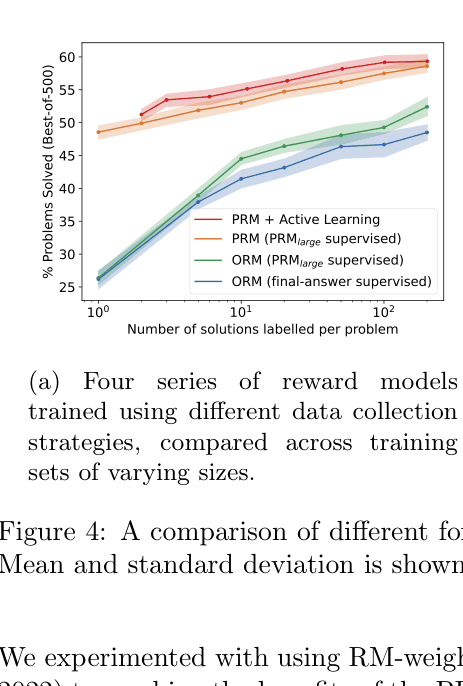
- Use active learning to select 'convincing wrong-answer' solutions (high PRM score but wrong final answer) for human labeling, maximizing data efficiency
- Define the score of a whole solution as the probability that *every* step is correct (product of step probabilities)
Architecture

Screenshot of the data collection interface showing a step-by-step solution with human-assigned labels (positive/neutral/negative).
Evaluation Highlights
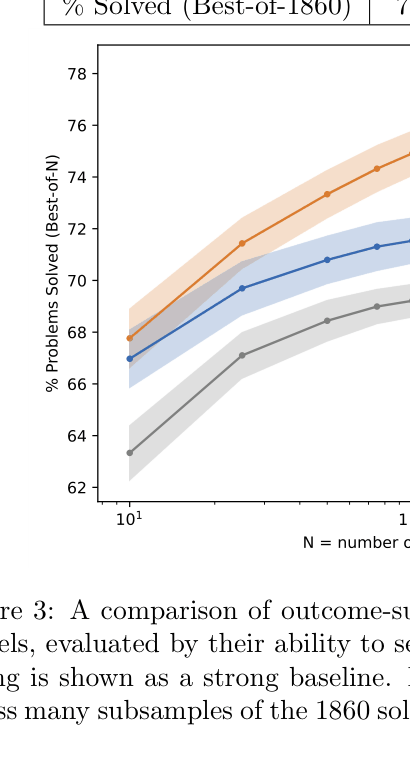
- Process-supervised Reward Model (PRM) solves 78.2% of problems on a representative subset of the MATH test set (Best-of-N search)
- Outcome-supervised Reward Model (ORM) solves 72.4% on the same subset, despite being trained on more (but outcome-only) data
- Active learning improves data efficiency by approximately 2.6x compared to uniform data labeling
Breakthrough Assessment
9/10
Establishment of process supervision as clearly superior to outcome supervision for reasoning, backed by a massive released dataset (PRM800K) and state-of-the-art results on MATH.