📝 Paper Summary
Chain-of-thought prompting
Decoding strategies
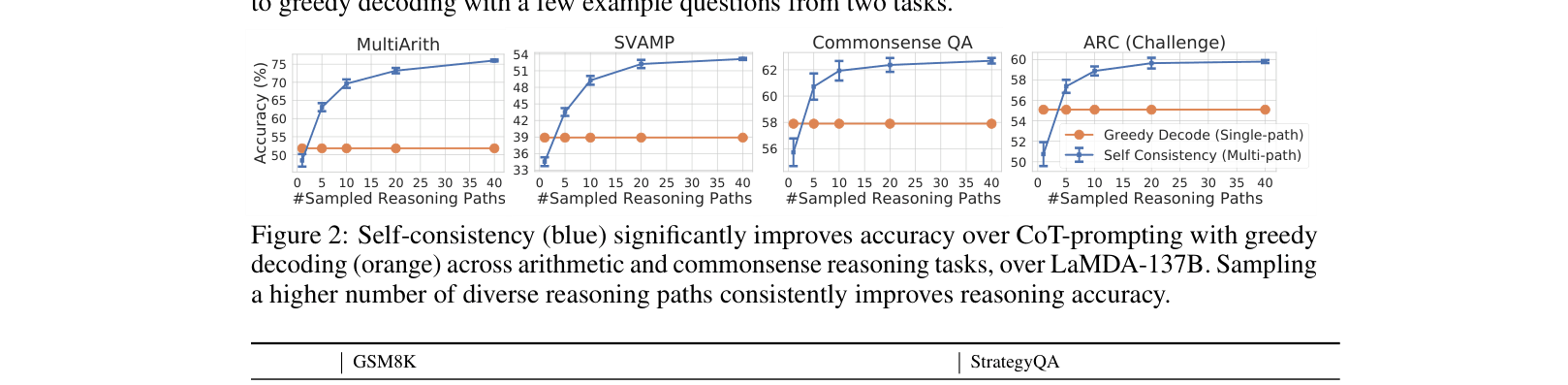
Self-consistency replaces greedy decoding in chain-of-thought prompting by sampling diverse reasoning paths and selecting the answer with the most consistent final result.
Core Problem
Naive greedy decoding in chain-of-thought prompting often yields suboptimal or incorrect reasoning paths because language models are not perfect reasoners.
Why it matters:
- Complex reasoning tasks typically require deliberate thinking, where a single greedy path often fails to capture the correct solution
- Language models may produce incorrect reasoning steps or make mistakes in a single generation, leading to wrong answers
- Greedy decoding suffers from repetitiveness and local optimality, failing to explore the diversity of thought processes available to the model
Concrete Example:
In a math problem about egg sales, a greedy decode might miscalculate '16 - 3 - 4 = 9' and incorrectly answer '$18'. Self-consistency samples multiple paths: some might repeat the error, but if the majority correctly calculate '16 - 3 = 13; 13 - 4 = 9' or arrive at the answer '$18' through valid logic, the aggregated result is more reliable.
Key Novelty
Sample-and-Marginalize Decoding for Reasoning
- Replaces the standard 'greedy decode' used in chain-of-thought prompting with a sampling strategy (e.g., high temperature) to generate diverse reasoning paths
- Leverages the intuition that while there are many incorrect ways to reason, correct reasoning paths tend to lead to the same unique answer
- Aggregates the final answers from the sampled paths using majority voting (marginalization) to select the most consistent solution
Architecture
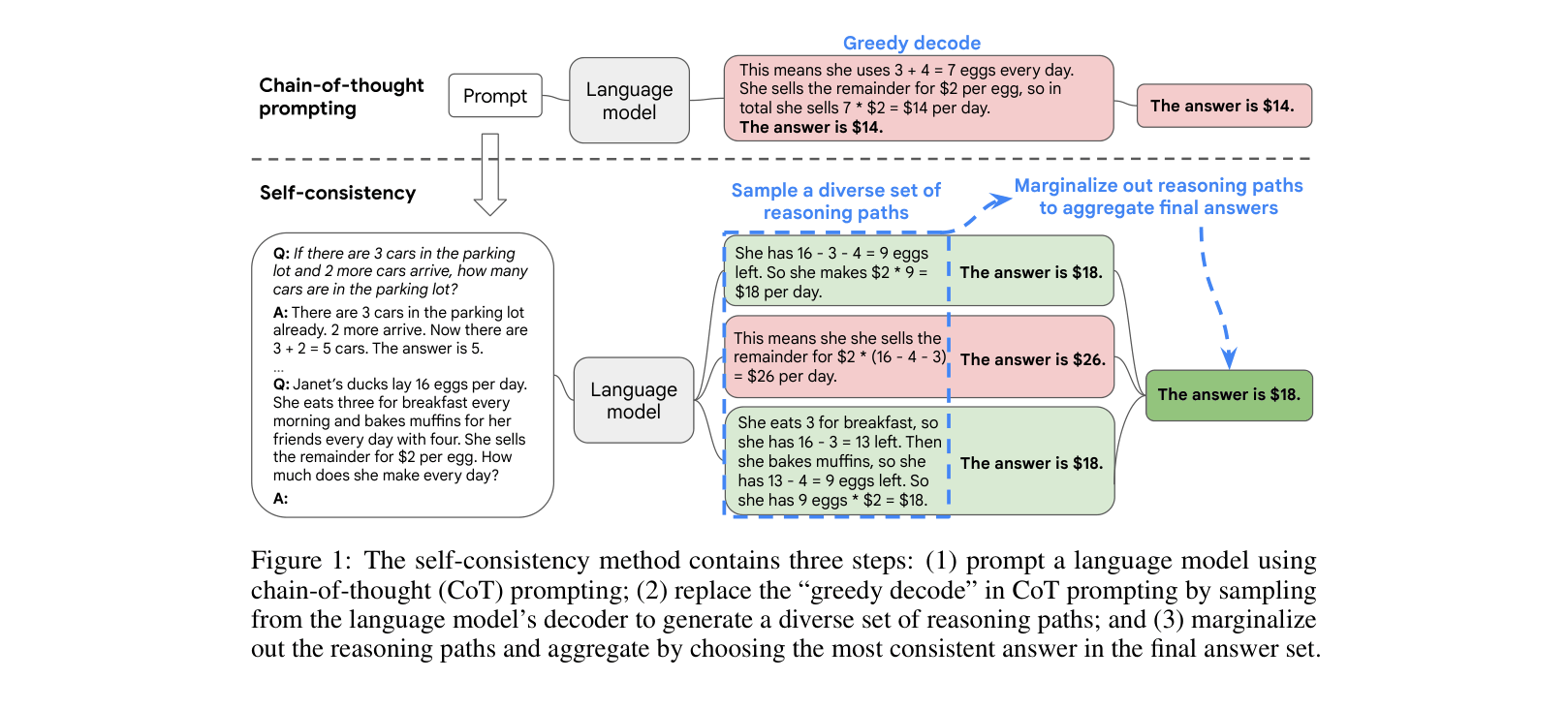
Conceptual comparison between Greedy Decode and Self-Consistency method
Evaluation Highlights
- +17.9% absolute accuracy improvement on GSM8K using PaLM-540B compared to standard chain-of-thought prompting
- +12.2% absolute accuracy improvement on AQuA using PaLM-540B compared to standard chain-of-thought prompting
- +11.0% absolute accuracy improvement on SVAMP using PaLM-540B compared to standard chain-of-thought prompting
Breakthrough Assessment
9/10
A simple, unsupervised, and highly effective drop-in replacement for greedy decoding that significantly boosts reasoning performance across multiple benchmarks and model scales.