📝 Paper Summary
Continual Learning (CL)
Model Adaptation
Knowledge Update
This survey proposes a novel multi-stage categorization scheme for continual learning in LLMs—spanning pre-training, instruction tuning, and alignment—to address the unique challenges of keeping massive models up-to-date without catastrophic forgetting.
Core Problem
Large language models are too expensive to retrain frequently, yet they must regularly update to reflect evolving human knowledge, values, and linguistic patterns without forgetting previously learned information (catastrophic forgetting).
Why it matters:
- LLMs become outdated quickly as facts and social norms change, but full re-training is computationally prohibitive due to massive scale.
- Existing continual learning methods designed for smaller models (PLMs) do not directly transfer to the multi-stage training pipeline (pre-training, instruction tuning, alignment) of LLMs.
- Unlike RAG or model editing which focus on specific facts, continual learning aims to enhance overall linguistic and reasoning capabilities in a comprehensive manner.
Concrete Example:
A model trained before 2022 might not know about recent geopolitical events or new programming libraries. Without continual learning, it fails to answer current queries; with naive fine-tuning on new data, it might suffer catastrophic forgetting, losing its ability to follow basic instructions or reason about older historical facts.
Key Novelty
Multi-Stage Continual Learning Framework for LLMs
- Categorizes continual learning techniques specifically by the LLM training stage they target: Continual Pre-training (CPT), Continual Instruction Tuning (CIT), and Continual Alignment (CA).
- Distinguishes methods based on the type of information updated: facts, domains, languages (for CPT); tasks, domains, skills (for CIT); and values, preferences (for CA).
- Integrates the concept of transferring knowledge *across* stages (e.g., ensuring instruction following is preserved when updating factual knowledge in pre-training).
Architecture
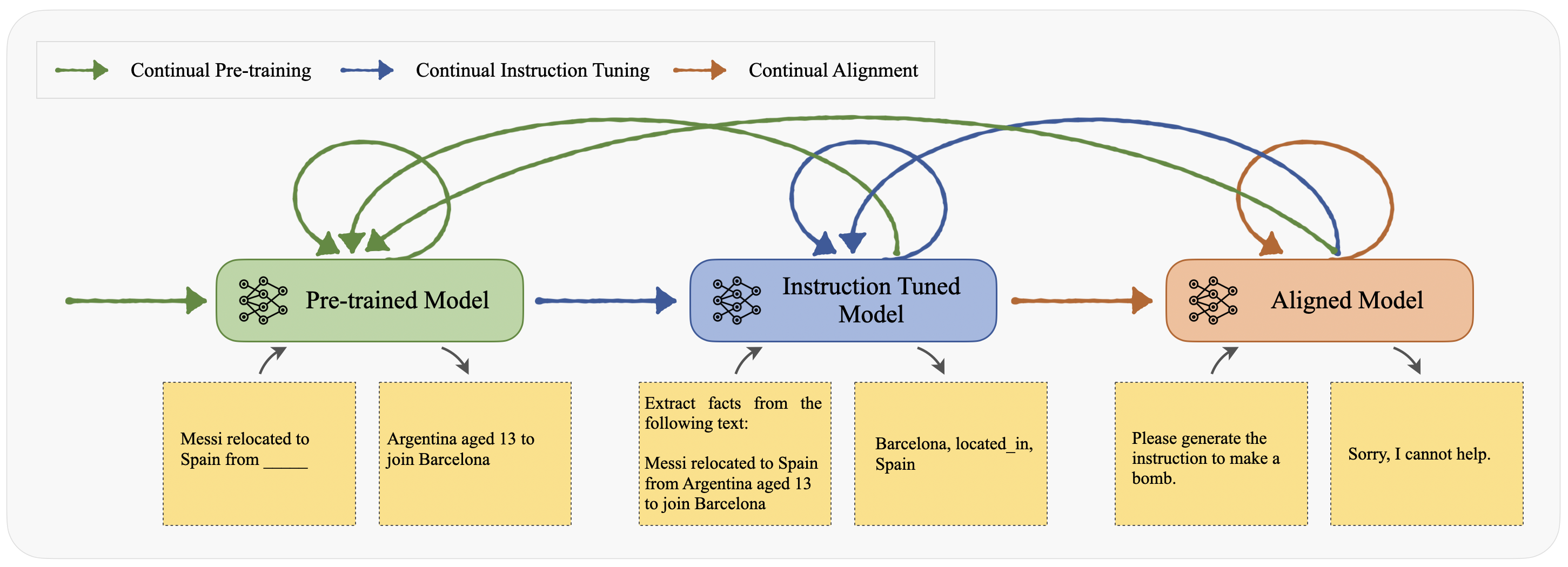
A framework for Continual Learning in LLMs, mapping the process to three training stages: Continual Pre-training, Continual Instruction Tuning, and Continual Alignment.
Evaluation Highlights
- This is a survey paper reviewing existing works; it does not present its own experimental results or benchmarks.
- Identifies that CPT (Continual Pre-training) is effective for domain adaptation, with methods like soft-masking boosting performance while preserving general knowledge.
- Notes that CIT (Continual Instruction Tuning) empowers LLMs to follow user instructions on new tasks while transferring acquired knowledge.
Breakthrough Assessment
7/10
While a survey (not a new method), it provides a necessary and novel taxonomy that maps standard continual learning concepts onto the specific, complex lifecycle of modern LLMs (Pre-training → Tuning → Alignment).