📝 Paper Summary
Open-source NLP libraries
Pretrained model distribution
Transfer learning infrastructure
Transformers is an open-source library that unifies state-of-the-art NLP architectures under a single API and provides a centralized hub for distributing and deploying pretrained models.
Core Problem
The rapid proliferation of Transformer architectures and pretraining methods created a fragmented landscape where accessing, reproducing, and deploying state-of-the-art models required significant engineering effort.
Why it matters:
- Researchers need a standardized codebase to compare new architectures against baselines without reimplementing everything from scratch
- Practitioners need easy access to pretrained models to apply transfer learning to downstream tasks without expensive pretraining
- The ubiquity of Transformers created a need for tools that handle the entire lifecycle: training, scaling, sharing, and deployment
Concrete Example:
Before this library, using BERT required Google's TensorFlow code, while using GPT-2 required OpenAI's code. A researcher wanting to compare them on a new dataset had to wrangle two completely different codebases and data formats. With Transformers, switching between them takes changing one string in a configuration object.
Key Novelty
Unified API and Community Model Hub
- Standardizes disparate Transformer implementations (BERT, GPT-2, RoBERTa) into a consistent three-part abstraction: Tokenizer, Transformer, and Head
- Decouples model architecture from framework, allowing interoperability between PyTorch and TensorFlow via standard serialization
- Introduces a centralized Model Hub where users can upload/download pretrained weights with a simple string identifier, democratizing access to compute-heavy models
Architecture
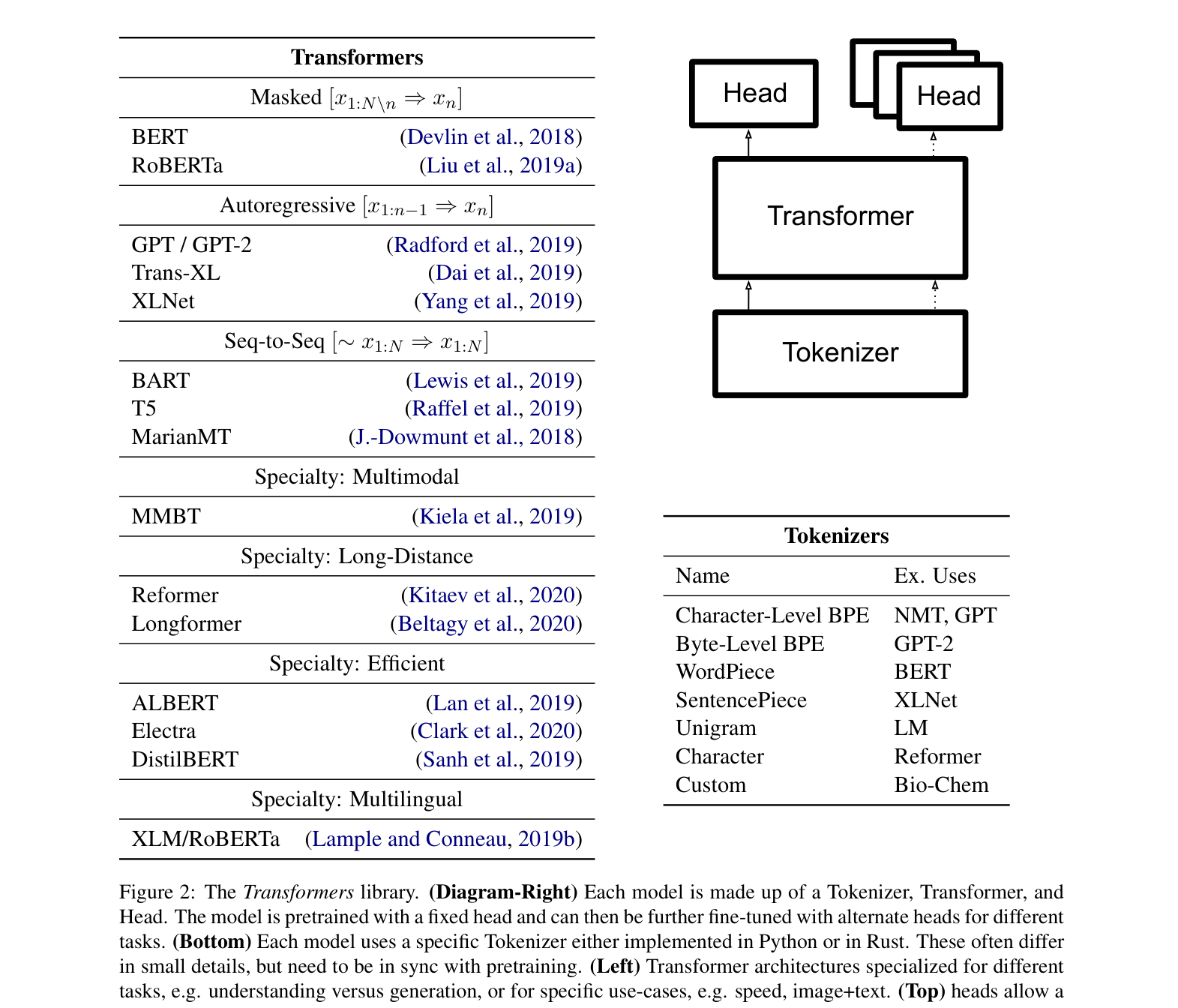
The logical components of a model in the library (Tokenizer, Transformer, Head) and the hierarchy of available architectures and tasks.
Evaluation Highlights
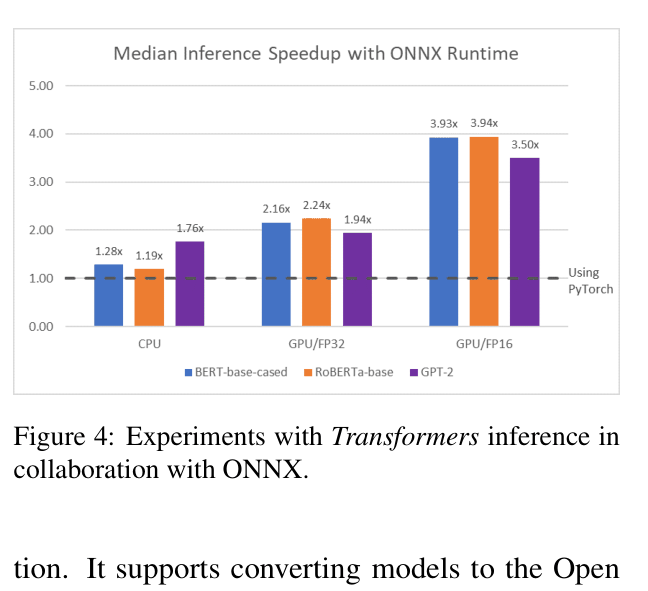
- Achieved ~4x inference speedup for BERT, RoBERTa, and GPT-2 by exporting to ONNX format
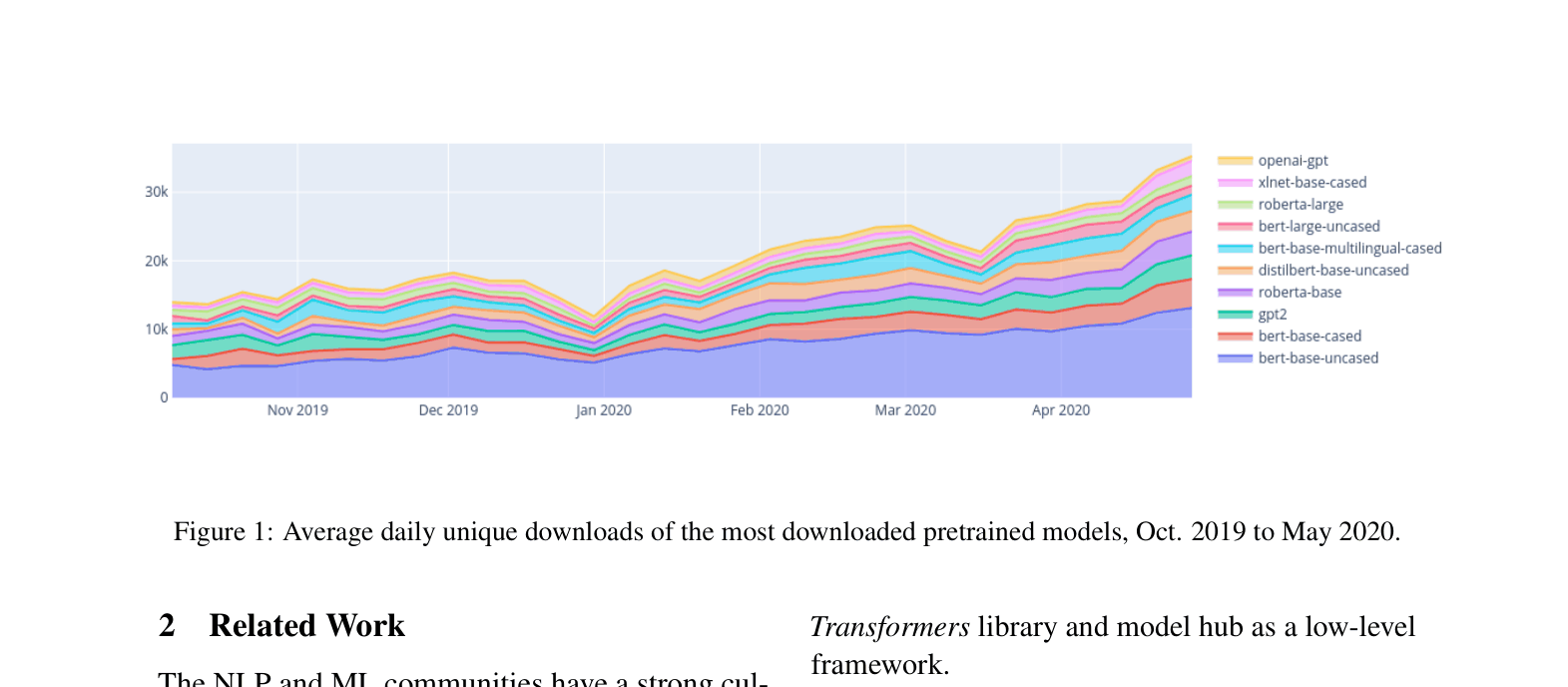
- Hosted 2,097 user models (pretrained and fine-tuned) on the Model Hub as of May 2020
- Integrated 30+ state-of-the-art architectures including BERT, GPT-2, T5, and BART under a single API
Breakthrough Assessment
10/10
The library became the de facto standard for NLP, enabling the entire field's shift to transfer learning. It is arguably the most influential infrastructure software in modern NLP.