📝 Paper Summary
Video Generation
Generative Models
Long Context Tuning adapts pre-trained single-shot video diffusion models to generate coherent multi-shot scenes by expanding the attention mechanism and employing asynchronous noise strategies.
Core Problem
Current state-of-the-art video models excel at generating single shots but fail to produce multi-shot narrative scenes with consistent visual appearance (characters, lighting) and temporal dynamics.
Why it matters:
- Real-world content like movies requires scenes composed of multiple shots, not just isolated clips
- Existing keyframe-based methods struggle with temporal consistency and cannot handle characters entering between frames
- Appearance-conditioned methods often lose abstract elements like lighting or color tone across shots
Concrete Example:
Generating a scene from *Titanic* requires four shots (Jack looking back, Rose speaking, wide shot, embrace). Independent generation fails to keep Jack's appearance consistent, while keyframe methods miss dynamic actions like walking pace.
Key Novelty
Long Context Tuning (LCT)
- Expands the attention mechanism of a single-shot model to process all shots in a scene simultaneously, treating them as a single long sequence
- Uses interleaved 3D positional embeddings to distinguish shots while preserving internal spatial-temporal relationships
- Trains with asynchronous diffusion timesteps (different noise levels per shot), allowing some shots to act as clean conditions for others
Architecture
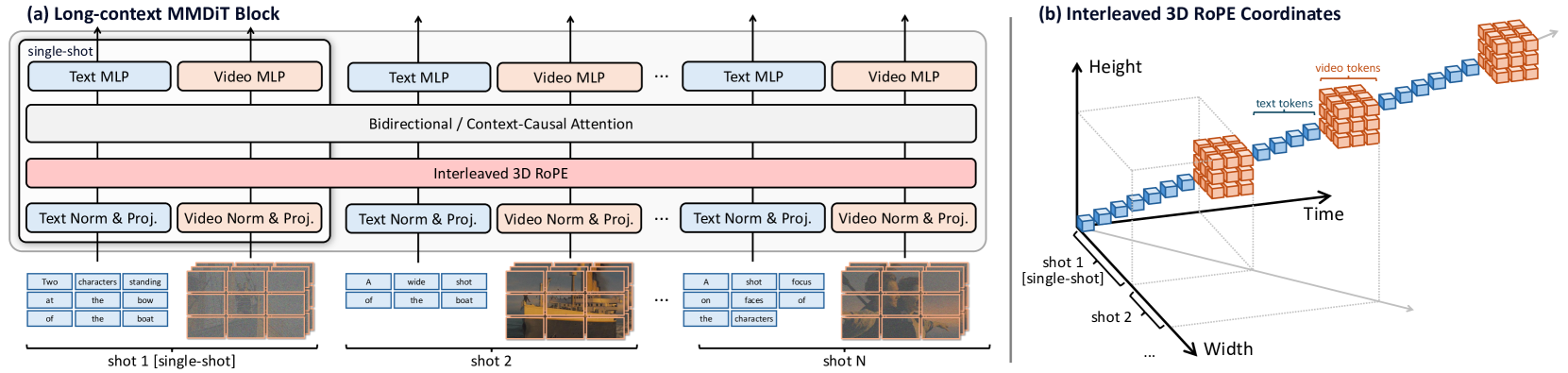
Overview of Long Context Tuning (LCT) framework and Interleaved 3D RoPE
Evaluation Highlights
- Generates coherent videos with approximately 20 shots lasting 3 minutes while maintaining visual and semantic consistency
- Enables emergent compositional generation capabilities, integrating character identity and environment images seamlessly without explicit training for this task
- Facilitates efficient auto-regressive generation using KV-cache by fine-tuning with context-causal attention
Breakthrough Assessment
8/10
Significant advance in bridging single-shot and scene-level generation. The asynchronous timestep strategy and causal fine-tuning offer a practical path for long-form video consistency without massive retraining.