📝 Paper Summary
LLM-based recommendation
Sequential Recommendation
Instruction Tuning
TALLRec aligns Large Language Models with recommendation tasks via a lightweight two-stage instruction tuning framework, enabling effective few-shot learning and cross-domain generalization.
Core Problem
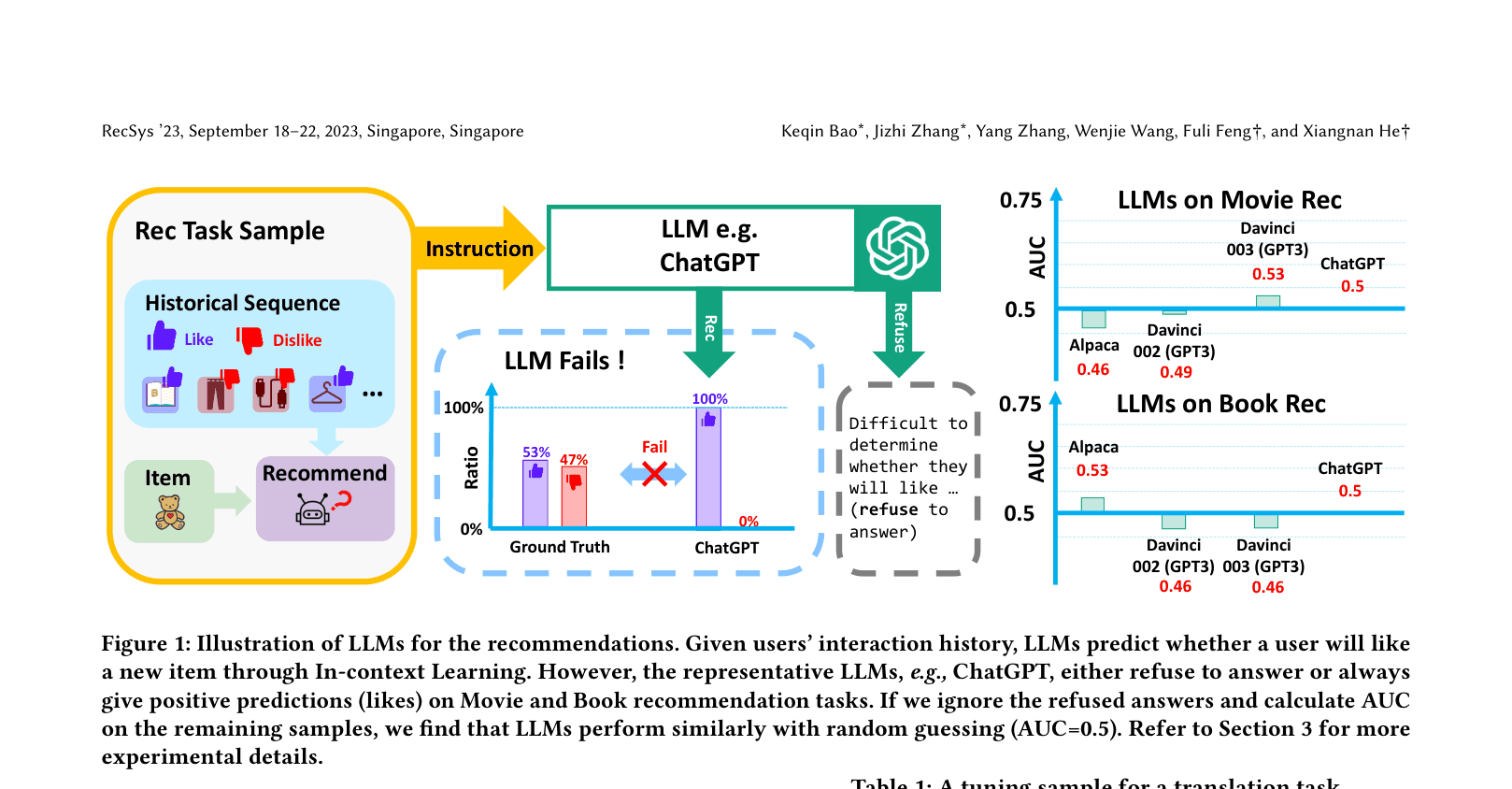
General-purpose LLMs fail to perform well on recommendation tasks using simple in-context learning because their training data lacks recommendation-oriented corpora and alignment.
Why it matters:
- Traditional recommendation models struggle with generalization and require massive data, while LLMs have potential for strong generalization if properly aligned.
- Existing LLM approaches relying solely on In-context Learning (like ChatGPT) often refuse to answer or output trivial 'positive' predictions, performing no better than random guessing.
- Full fine-tuning of LLMs for recommendation is computationally prohibitive for most researchers.
Concrete Example:
When asked to predict if a user will like 'Iron Man' based on their history using In-context Learning, ChatGPT either refuses to answer or always predicts 'Yes' (positive bias), resulting in an AUC of ~0.50 (random guessing) on MovieLens.
Key Novelty
Two-Stage Lightweight Instruction Tuning for Recommendation (TALLRec)
- Constructs a 'Large Recommendation Language Model' by treating recommendation data as instruction tuning samples (User History + Target Item -> Yes/No).
- Utilizes a two-stage tuning process: 'Alpaca tuning' for general instruction following, followed by 'Rec-tuning' for domain alignment.
- Employs LoRA (Low-Rank Adaptation) to enable efficient fine-tuning on consumer-grade hardware (e.g., RTX 3090) with very few samples.
Architecture
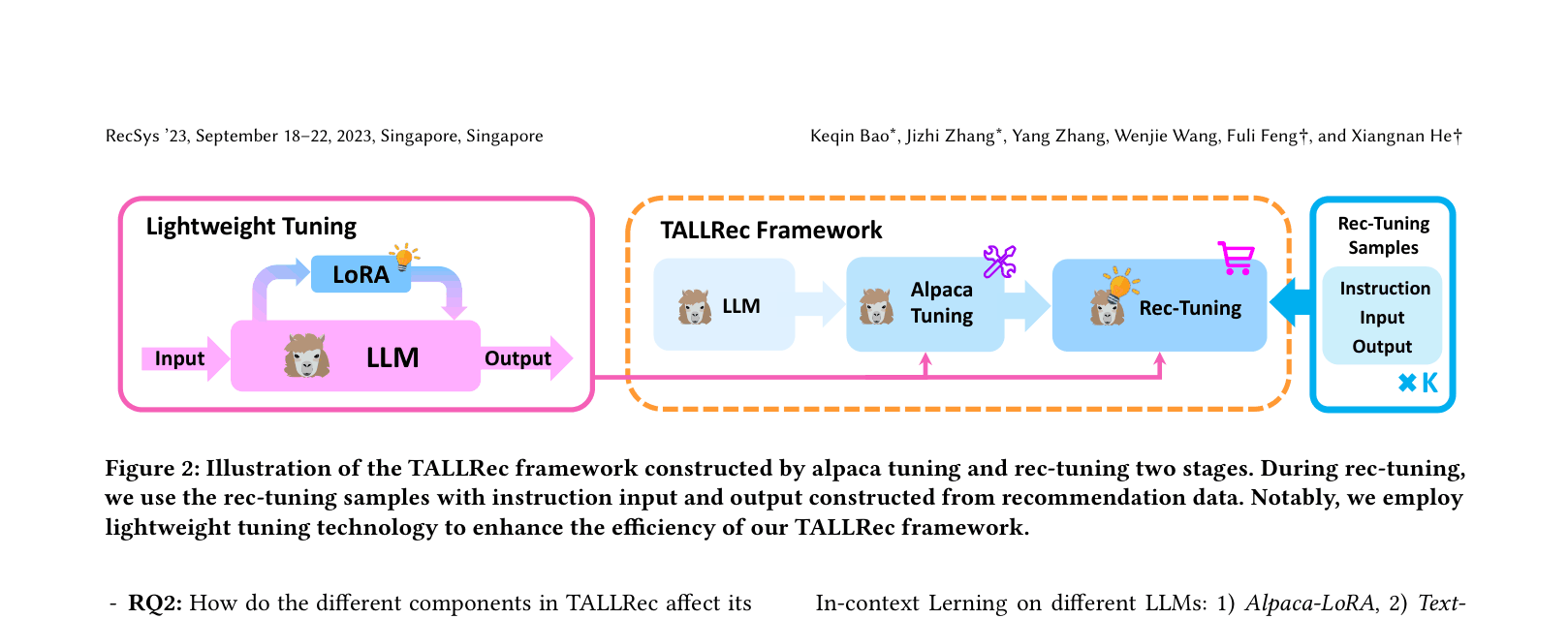
The TALLRec framework pipeline showing the two-stage tuning process.
Evaluation Highlights
- +17.03% AUC improvement on MovieLens (16-shot setting) compared to the best traditional baseline (GRU-BERT).
- Achieves strong performance with only 64 training samples, significantly outperforming In-context Learning methods (ChatGPT, GPT-3) which hover near random guessing.
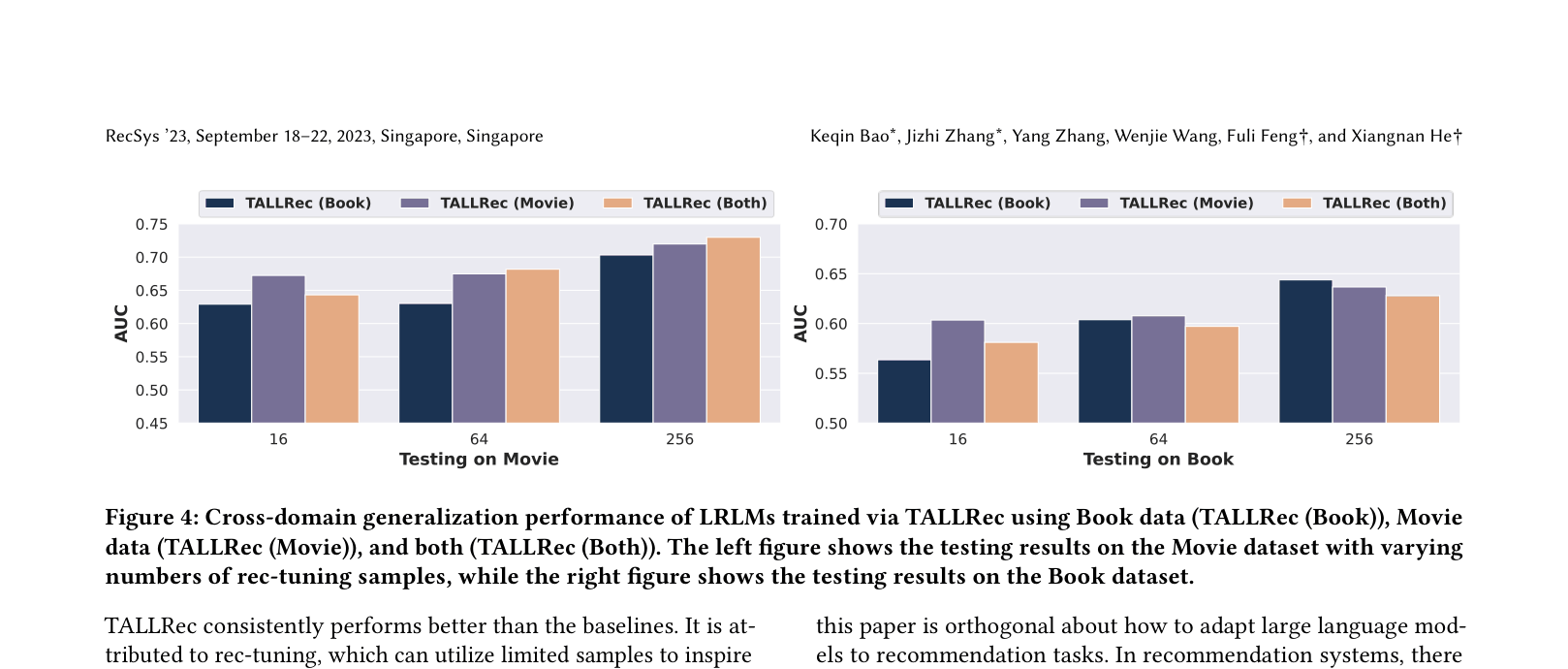
- Demonstrates robust cross-domain generalization: a model tuned on Movie data performs comparably to a model tuned on Book data when tested on the Book domain.
Breakthrough Assessment
8/10
Significant for establishing that lightweight instruction tuning is essential (and sufficient) to unlock LLM potential in recommendation, overcoming the failure modes of pure in-context learning.