📝 Paper Summary
Memory recall
Long-context modeling
LongMem augments a frozen LLM with a decoupled residual side-network that retrieves and fuses long-term context from a cached memory bank to solve memory staleness.
Core Problem
Existing methods for extending LLM context length, like Memorizing Transformer, use a coupled memory design where cached representations become stale as the model parameters update during training.
Why it matters:
- Standard LLMs are limited by fixed-size input contexts, preventing the use of rich long-term history or knowledge.
- Scaling input length via dense attention is computationally prohibitive due to quadratic complexity.
- Memory staleness in coupled architectures limits the effectiveness of memory augmentation because old cached keys/values drift distributionally from current model states.
Concrete Example:
In a coupled design like MemTRM, if the model updates its weights, the keys stored in memory from previous steps were generated by an older version of the model. When the current model queries this memory, the distributional shift (staleness) degrades retrieval accuracy and fusion quality.
Key Novelty
Decoupled Side-Network for Memory Retrieval (SideNet)
- Keeps the backbone LLM frozen as a dedicated memory encoder, ensuring cached memory representations (keys/values) remain stable and compatible throughout training.
- Introduces a lightweight, trainable residual SideNet that retrieves relevant past contexts from the memory bank and fuses them with current inputs.
- Uses cross-network residual connections to transfer pretrained knowledge from the frozen backbone to the SideNet, enabling efficient adaptation without catastrophic forgetting.
Architecture
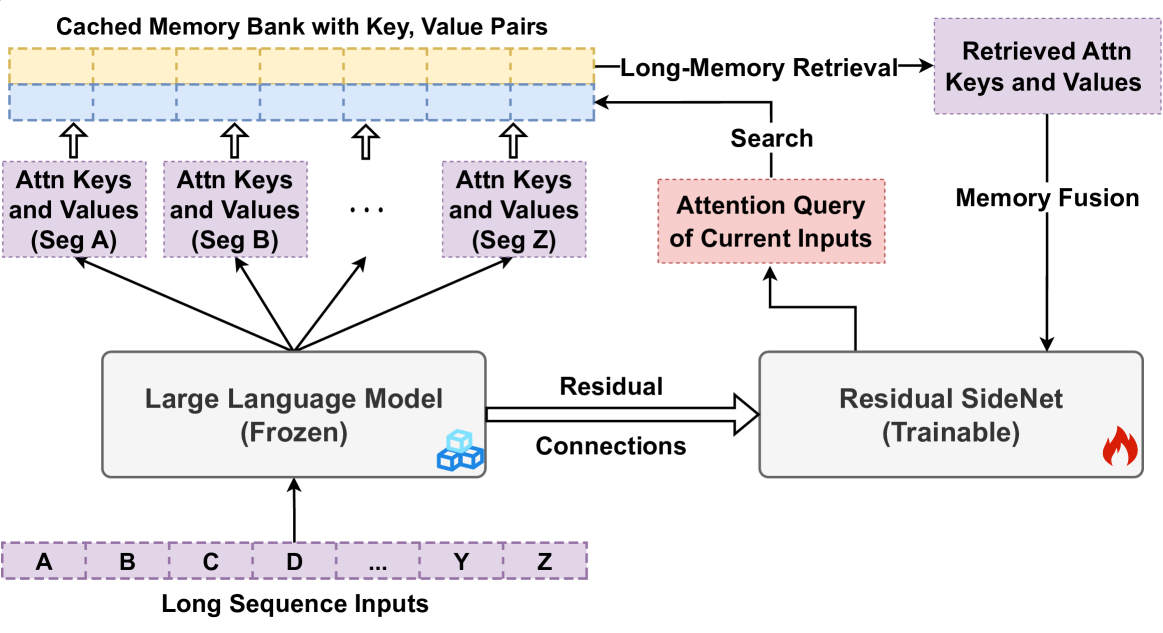
The LongMem architecture consisting of the frozen backbone LLM, the cached memory bank, and the residual SideNet.
Evaluation Highlights
- Achieves state-of-the-art 40.5% identification accuracy on the challenging ChapterBreak benchmark, significantly surpassing existing x-former baselines.
- Improves long-context language modeling perplexity by -1.38 to -1.62 on different length splits of the Gutenberg-2022 corpus compared to baselines.
- Demonstrates strong in-context learning with 2k demonstration examples in memory, outperforming MemTRM and standard LLMs on NLU tasks.
Breakthrough Assessment
8/10
Effective architectural solution to the memory staleness problem. The decoupled design allows efficient adaptation of frozen LLMs to infinite-length contexts, showing strong empirical gains on long-context tasks.