📝 Paper Summary
Memory organization
Memory recall
TiM enables LLMs to maintain long-term memory by storing evolved thoughts rather than raw history, utilizing a post-thinking stage to update memory via insert, forget, and merge operations.
Core Problem
Existing memory-augmented LLMs store raw historical text, necessitating repeated reasoning over the same history for new queries, which leads to inconsistent reasoning paths and high retrieval costs.
Why it matters:
- Repeated reasoning over raw history causes LLMs to generate biased or contradictory thoughts for the same context
- Calculating pairwise similarity between queries and extensive raw history is computationally expensive and time-consuming for long-term dialogues
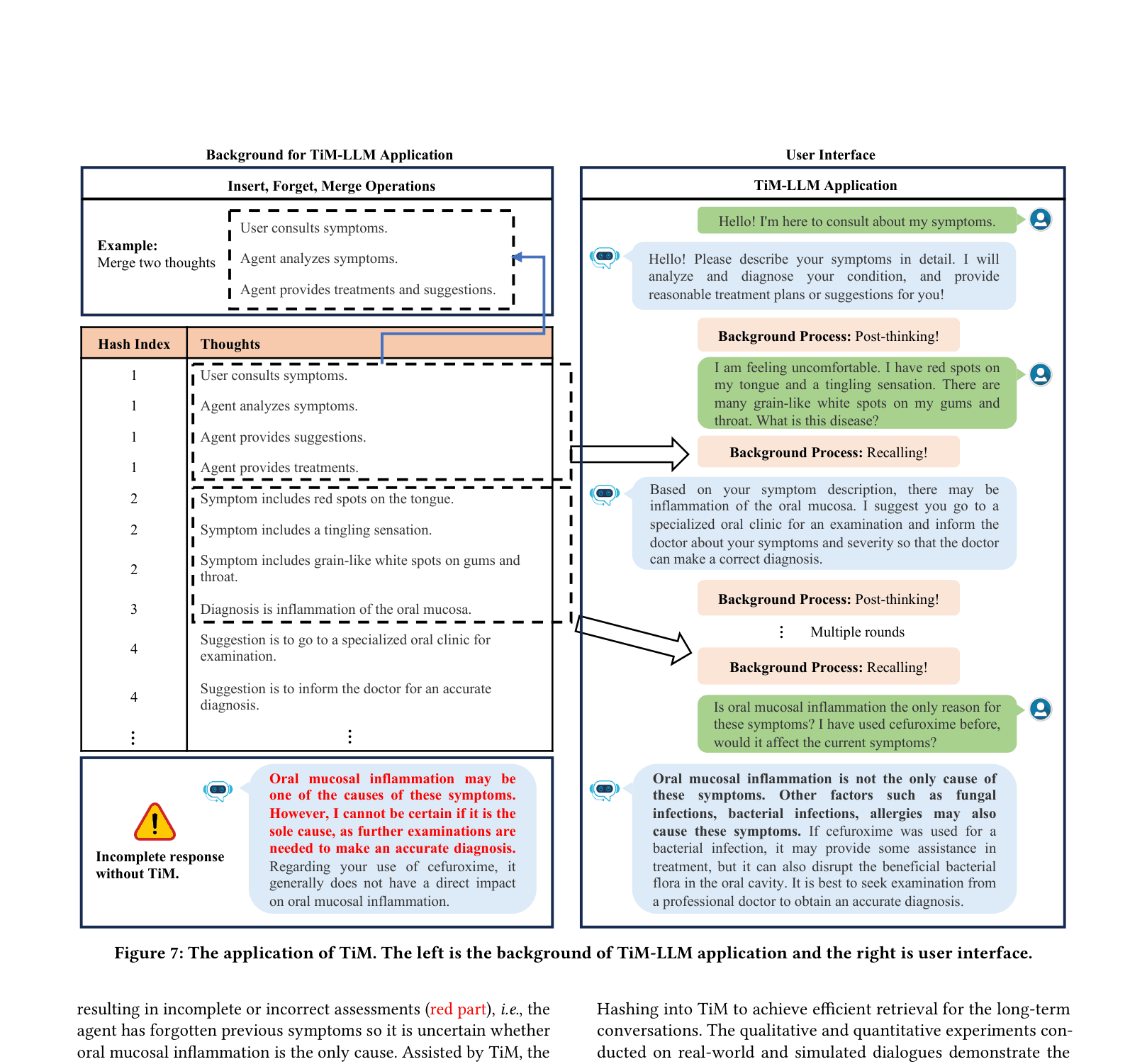
- Without proper memory management, LLMs fail to maintain accurate long-term context, critical for applications like medical diagnosis
Concrete Example:
In a math word problem involving egg sales, an LLM reasoning over raw history calculates profit differently in Turn 2 vs. Turn 3 because it re-processes the original text each time. In Turn 2, it says Janet has $10; in Turn 3, it re-calculates and erroneously concludes she has $20 due to an inconsistent reasoning path.
Key Novelty
Think-in-Memory (TiM) Framework
- Decouples reasoning from recalling by storing 'thoughts' (conclusions) instead of raw text, preventing the need to re-reason over the same history
- Introduces a 'post-thinking' stage where the agent analyzes its own response to update memory using human-like operations: insert, forget, and merge
- Utilizes Locality-Sensitive Hashing (LSH) for efficient storage and retrieval, grouping similar thoughts to speed up access without full pairwise comparisons
Architecture
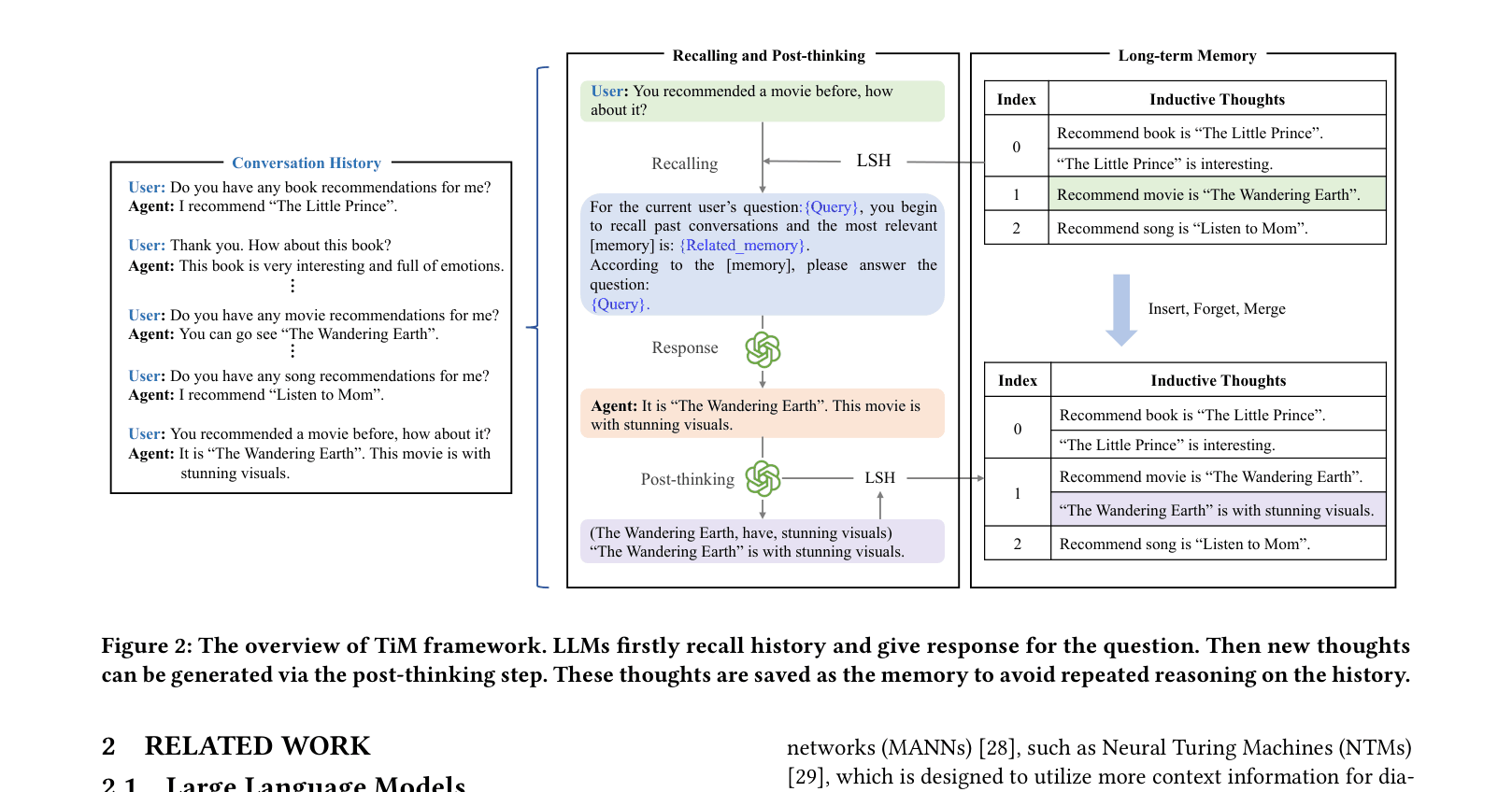
Overview of the TiM framework showing the Recalling and Post-thinking stages.
Evaluation Highlights
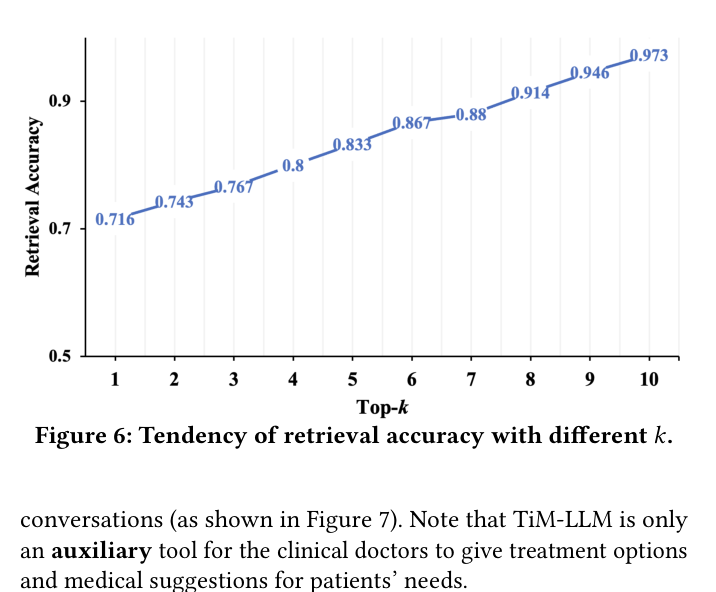
- Achieves 0.970 retrieval accuracy on the KdConv dataset (Music topic) with ChatGLM, significantly outperforming baselines
- Improves response correctness to 0.843 on the Real-world Medical Dataset (RMD) using ChatGLM, compared to 0.806 for the baseline
- Reduces retrieval time to 0.5305 ms per retrieval compared to 0.6287 ms for the baseline pairwise similarity method
Breakthrough Assessment
7/10
TiM offers a logical evolution from raw-text memory to thought-based memory with specific maintenance operations (merge/forget). The reduction in repeated reasoning is a strong conceptual contribution, though tested primarily on smaller/simulated datasets.