📝 Paper Summary
Modularized RAG pipeline
Selective Retrieval
SR-RAG treats the LLM as a routable knowledge source, training it to decide between external retrieval and internal knowledge verbalization within a single generation pass.
Core Problem
Existing selective retrieval methods treat skipping retrieval as a binary fallback to direct answering, ignoring the LLM's potential to explicitly verbalize relevant internal knowledge.
Why it matters:
- Binary choices (retrieve vs. answer directly) underestimate model capabilities because direct answering skips the opportunity to surface parametric knowledge
- Training routers against direct-answer baselines leads to miscalibrated decisions about when retrieval is actually necessary
- Standard selective retrieval cannot flexibly route between multiple heterogeneous sources (e.g., internal knowledge vs. Wikipedia vs. PubMed)
Concrete Example:
A pilot study shows that simply asking an LLM to 'verbalize' knowledge before answering changes the preferred source (internal vs. external) for a substantial fraction of questions, compared to just asking it to answer directly. Current routers miss this nuance.
Key Novelty
Self-Routing RAG (SR-RAG)
- Redefines selective retrieval as a multi-source routing problem where the LLM's internal parametric knowledge is treated as a distinct, first-class source alongside external corpora
- Unifies routing, knowledge verbalization, and answering into a single left-to-right generation pass using special tokens (<EOQ>, <Wiki>, <Self>)
- Augments inference with a kNN-based policy datastore that retrieves historical routing decisions based on query similarity to calibrate the model's self-selection confidence
Architecture
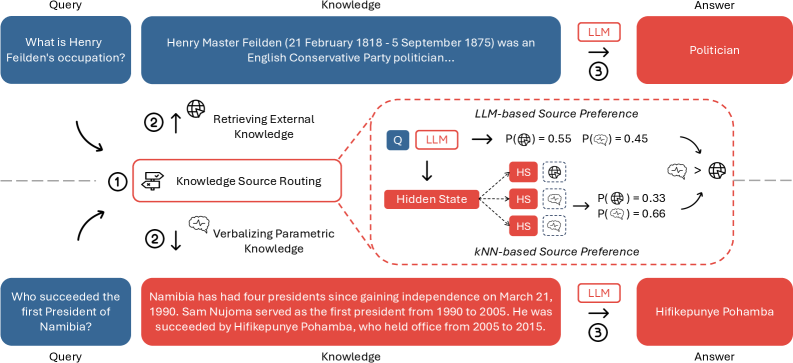
The inference workflow of SR-RAG comparing Internal Source flow vs. External Source flow.
Evaluation Highlights
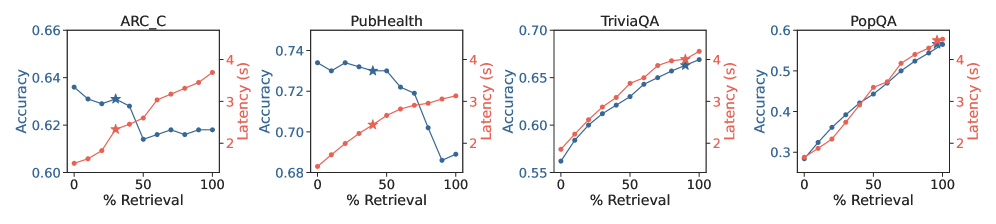
- Outperforms standard selective retrieval baselines by 8.5% on Llama-2-7B-Chat while performing 26% fewer retrievals
- Achieves 4.7% improvement on Qwen2.5-7B-Instruct with 21% fewer retrievals compared to strong baselines
- Maintains favorable accuracy-latency trade-offs across four benchmarks without requiring dataset-specific threshold tuning
Breakthrough Assessment
8/10
Significant conceptual shift from 'retrieval vs. no-retrieval' to 'routing between internal and external sources.' The single-pass integration and kNN-enhanced inference offer practical efficiency and robustness gains.