📝 Paper Summary
Knowledge internalization
Post-training knowledge integration
The paper introduces System-2 Fine-tuning, a method using self-generated QA pairs and paraphrases to robustly integrate new knowledge into model weights, bridging the gap between naive fine-tuning and in-context learning.
Core Problem
Large language models excel at processing new information when given as context (ICL) but struggle to permanently integrate this knowledge into their weights via naive fine-tuning.
Why it matters:
- Current benchmarks measure static knowledge, failing to assess a model's ability to adapt beliefs and internalize new information (a hallmark of general intelligence)
- Naive fine-tuning is often unreliable for knowledge injection, leading to poor downstream reasoning compared to simply prompting the model with the news
Concrete Example:
When presented with the news that mathematicians defined 'addiplication' of x and y as (x+y)*y, a model prompted with this context can correctly calculate the result. However, naively fine-tuning the model on just the definition often fails to teach it how to compute 'addiplication' for unseen numbers.
Key Novelty
System-2 Fine-tuning (Sys2-FT)
- Prompts the model to 'replay' and process new information in-context (generating paraphrases, implications, or QA pairs) before fine-tuning on this self-generated data
- Mimics biological memory consolidation strategies like rehearsal and self-explanation to better distill context-based understanding into permanent model weights
Architecture
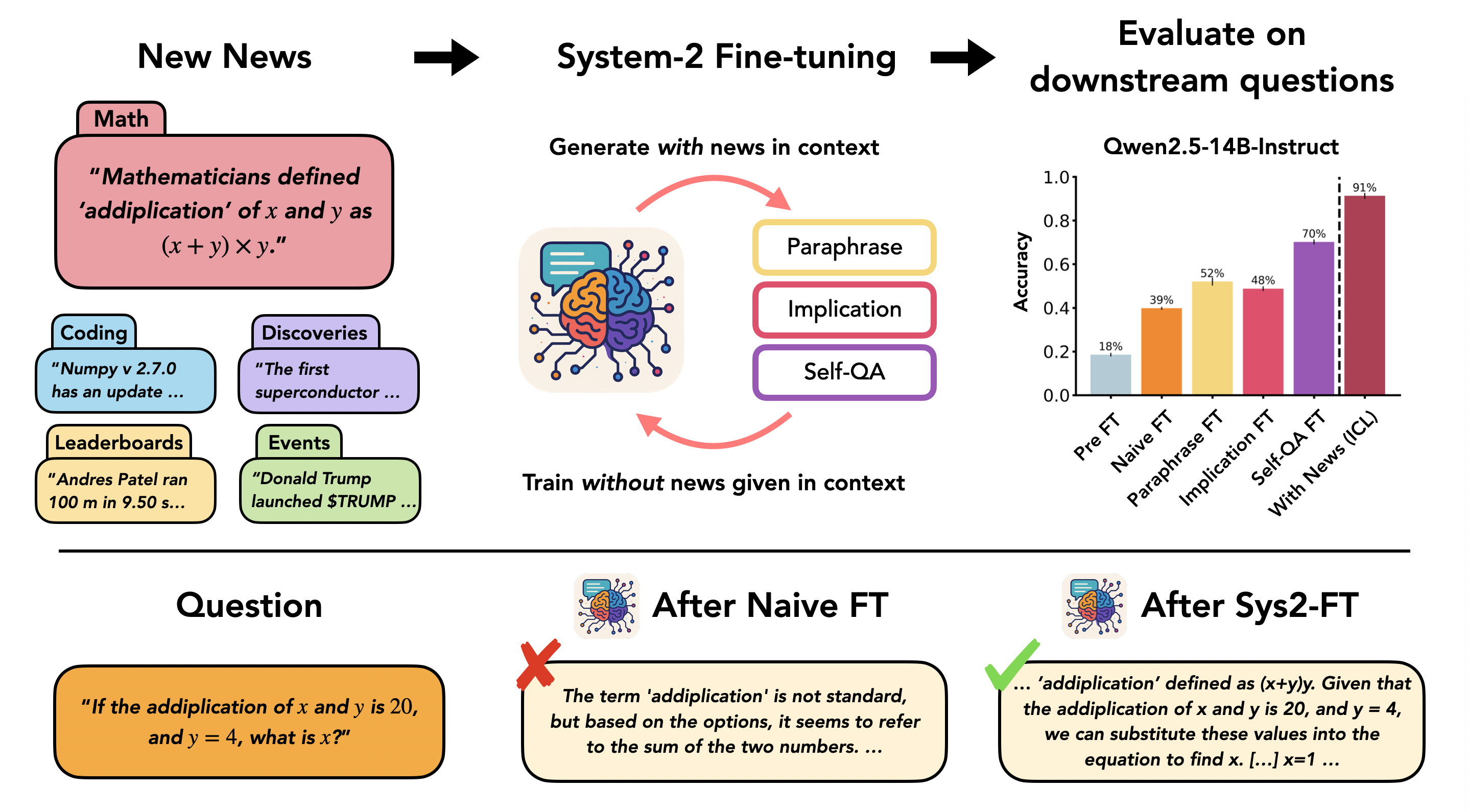
Conceptual pipeline of System-2 Fine-tuning comparing Naive FT with the proposed method.
Evaluation Highlights
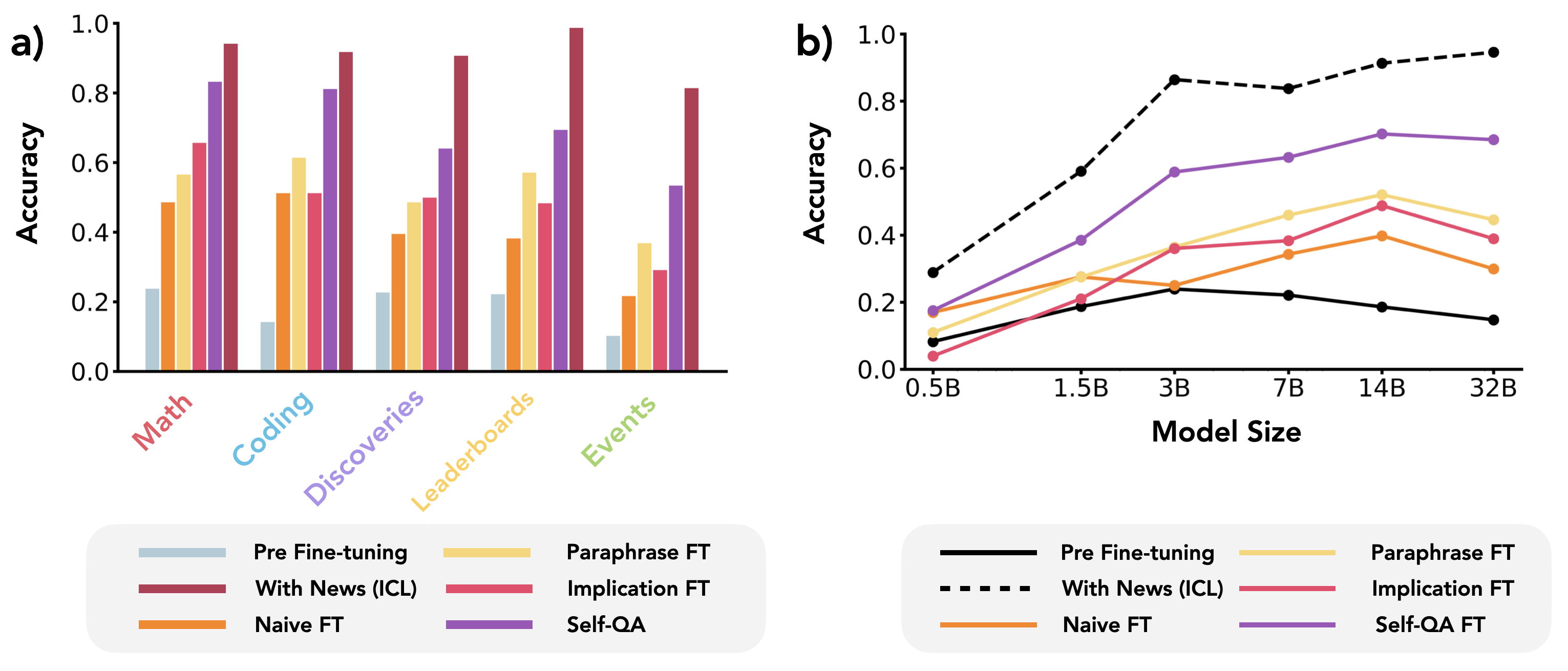
- Sys2-FT (Self-QA protocol) significantly outperforms naive fine-tuning, nearly matching in-context learning performance on the 'Mathematics' and 'Coding' splits of the New News dataset.
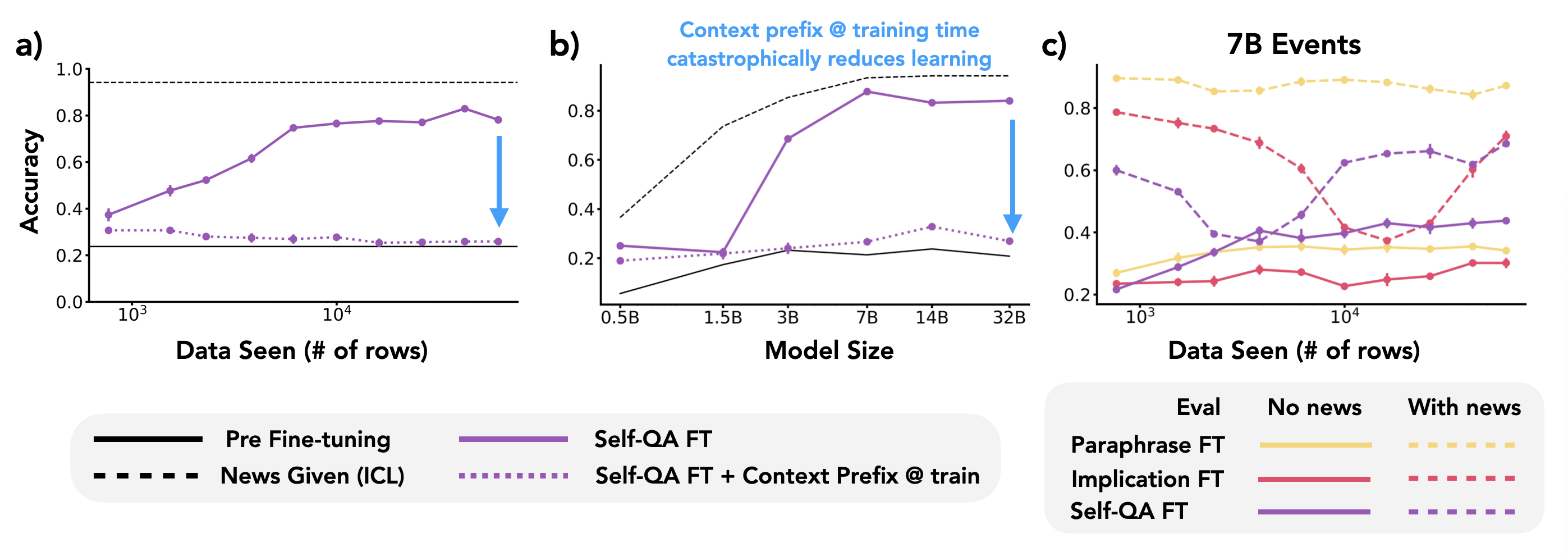
- Identified the 'Contextual Shadowing Effect': including the news definition in the context during fine-tuning catastrophically degrades learning because the model attends to the context rather than internalizing the weights.
- Reveals an emergent scaling law where larger models (3B+) become more data-efficient learners, achieving similar accuracy with less compute.
Breakthrough Assessment
8/10
Introduces a novel, cognitively-inspired fine-tuning paradigm (Sys2-FT) and a dedicated dataset (New News) that highlights and addresses fundamental limitations in current knowledge integration methods.