📝 Paper Summary
Code Generation
Reinforcement Learning (RL)
Agentic AI
RLEF trains Large Language Models to iteratively repair code using execution feedback via Reinforcement Learning, significantly improving sample efficiency on competitive programming tasks.
Core Problem
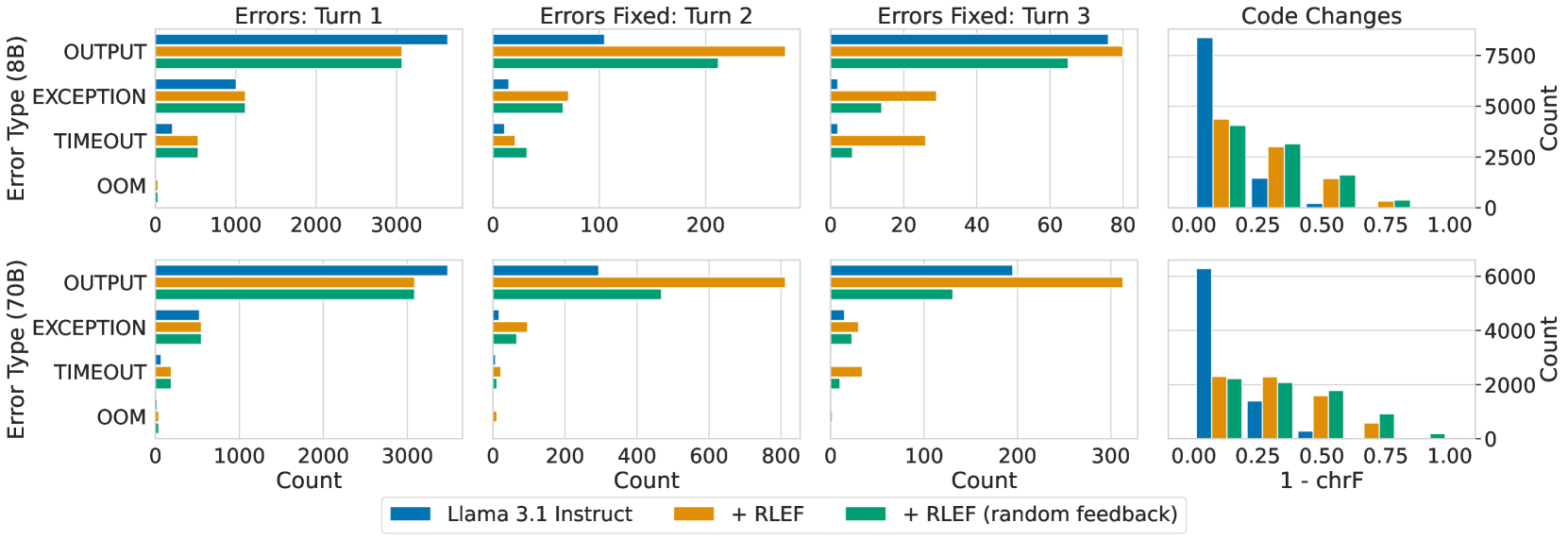
LLMs struggle to effectively use execution feedback (error messages) to iteratively improve code; independent sampling often outperforms self-correction for a fixed compute budget.
Why it matters:
- Current LLMs often fail to ground generations in concrete inference-time situations, necessitating repeated manual prompting or expensive scaffolding
- Utilizing feedback (like compiler errors) is crucial for autonomous agents but has historically failed to yield improvements over simple re-sampling
- Existing solutions rely on complex manual scaffolding (e.g., AlphaCodium) or massive sampling budgets rather than inherent model capability
Concrete Example:
When an LLM generates code that fails a public test case, a standard model might output the exact same wrong code again or hallucinate a fix that ignores the error message. With RLEF, the model learns to read the specific error (e.g., 'IndexError') and generate a corrected solution in the next turn.
Key Novelty
Reinforcement Learning with Execution Feedback (RLEF)
- Treats iterative code generation as a multi-turn Markov Decision Process where the state includes previous code attempts and their execution output (errors/test results)
- Optimizes the model end-to-end using PPO with a binary reward signal based on passing held-out tests, rather than just supervised fine-tuning on correct code
- Uses a hybrid token-level policy and turn-level value function to efficiently learn from sparse rewards in multi-turn dialogues
Architecture
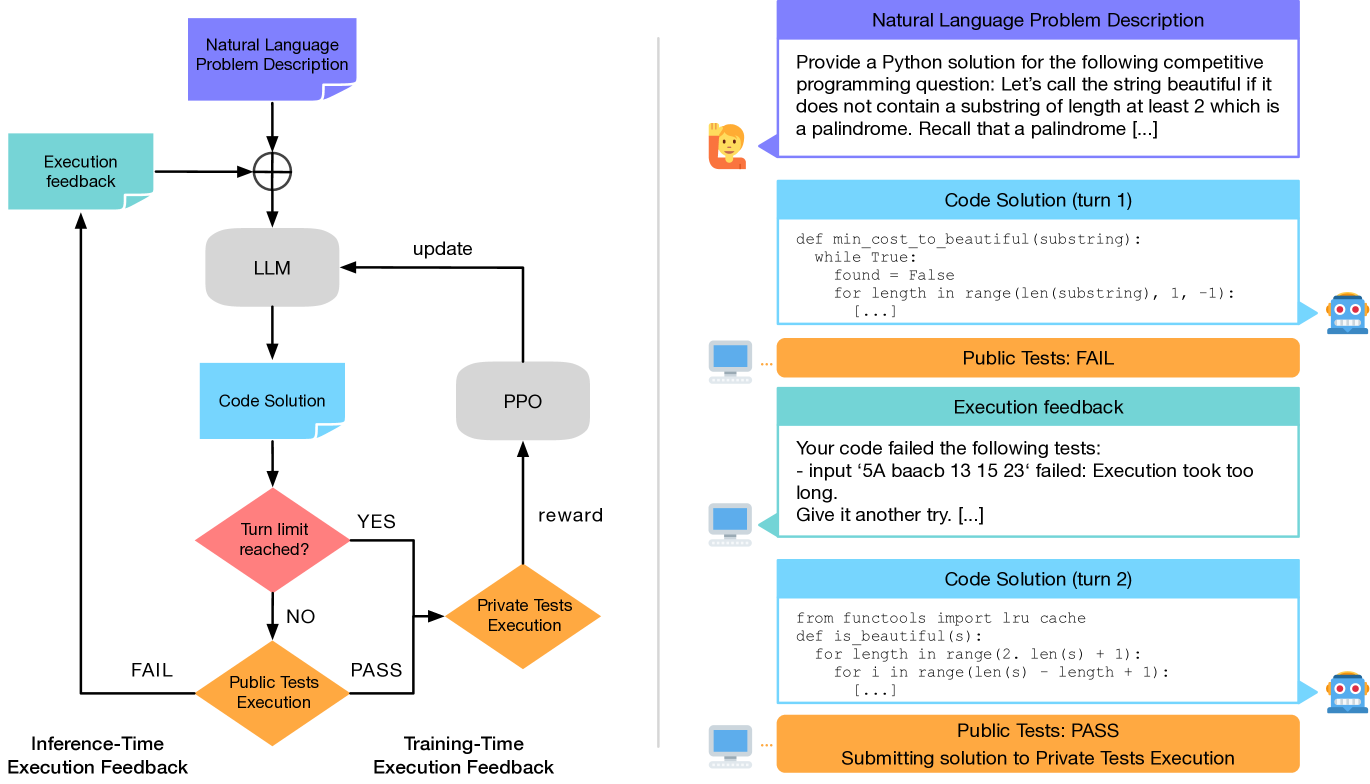
The iterative code synthesis conversation flow which serves as the environment for the RL agent.
Evaluation Highlights
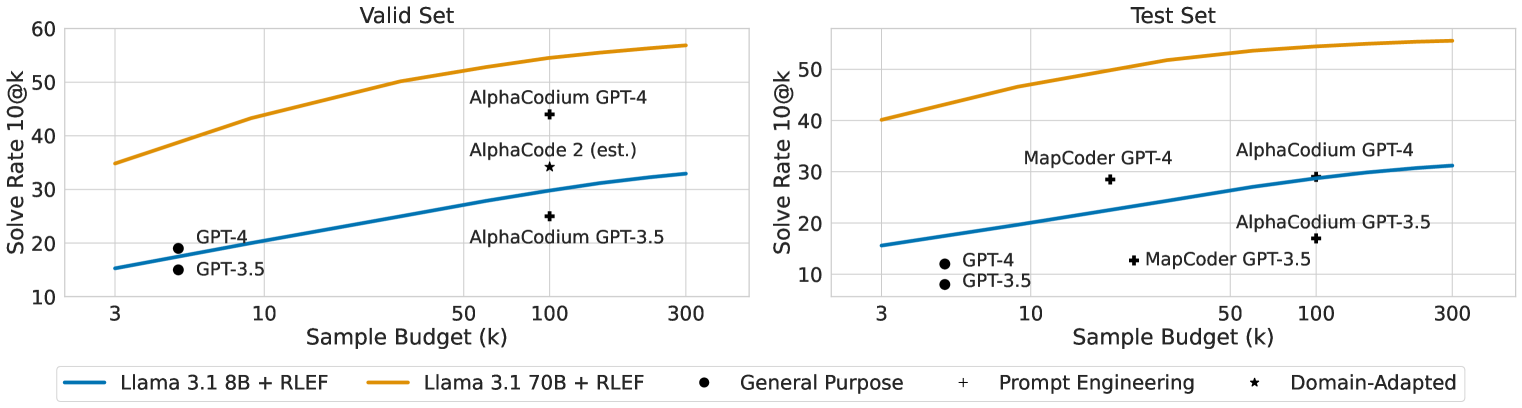
- Llama 3.1 70B with RLEF achieves 54.5% pass@1 on CodeContests (test set), surpassing GPT-4 based AlphaCodium (29%) and prior SFT baselines
- Reduces sample requirements by an order of magnitude: 70B model beats AlphaCodium (100 samples) with just a single rollout (3 turns)
- Generalizes to HumanEval+ (+12.7% for 8B) and MBPP+ (+5.2% for 70B) despite training only on CodeContests
Breakthrough Assessment
9/10
Significantly advances the state-of-the-art in code generation by making self-repair effective and sample-efficient, surpassing much larger proprietary models and complex scaffolding systems.