📝 Paper Summary
Reinforcement Learning from Human Feedback (RLHF)
Multi-Task Learning (MTL)
Safety and Alignment
CGPO treats multi-task LLM alignment as a constrained optimization problem, using specific judges to detect reward hacking and enforcing constraints per task rather than blending conflicting rewards linearly.
Core Problem
Standard RLHF fails in multi-task settings because linearly combining rewards creates conflicting objectives (e.g., safety vs. helpfulness) and over-optimization leads to reward hacking where models exploit proxy reward flaws.
Why it matters:
- Linear reward combinations force tradeoffs, degrading performance on both tasks (e.g., sacrificing helpfulness for safety)
- Models optimized for a single proxy reward eventually produce high-scoring but gibberish or harmful outputs (reward hacking)
- Uniform RL hyperparameters across diverse tasks (coding vs. creative writing) prevent optimal performance
Concrete Example:
In coding tasks, PPO often exhibits 'severe regression' where the model learns to generate code that tricks the reward model but fails execution tests (0-shot accuracy drops). CGPO uses execution feedback as a hard constraint to prevent this.
Key Novelty
Constrained Generative Policy Optimization (CGPO)
- Treats alignment as a constrained problem: maximize rewards subject to satisfying specific rules (constraints) rather than just maximizing a sum of rewards.
- Uses a 'Mixture of Judges' (rule-based and LLM-based) to continuously monitor outputs during training; if a constraint is violated (e.g., code doesn't compile), the update is penalized.
- Separates tasks completely during optimization, applying distinct reward models and hyperparameters to each instead of a single global mix.
Architecture
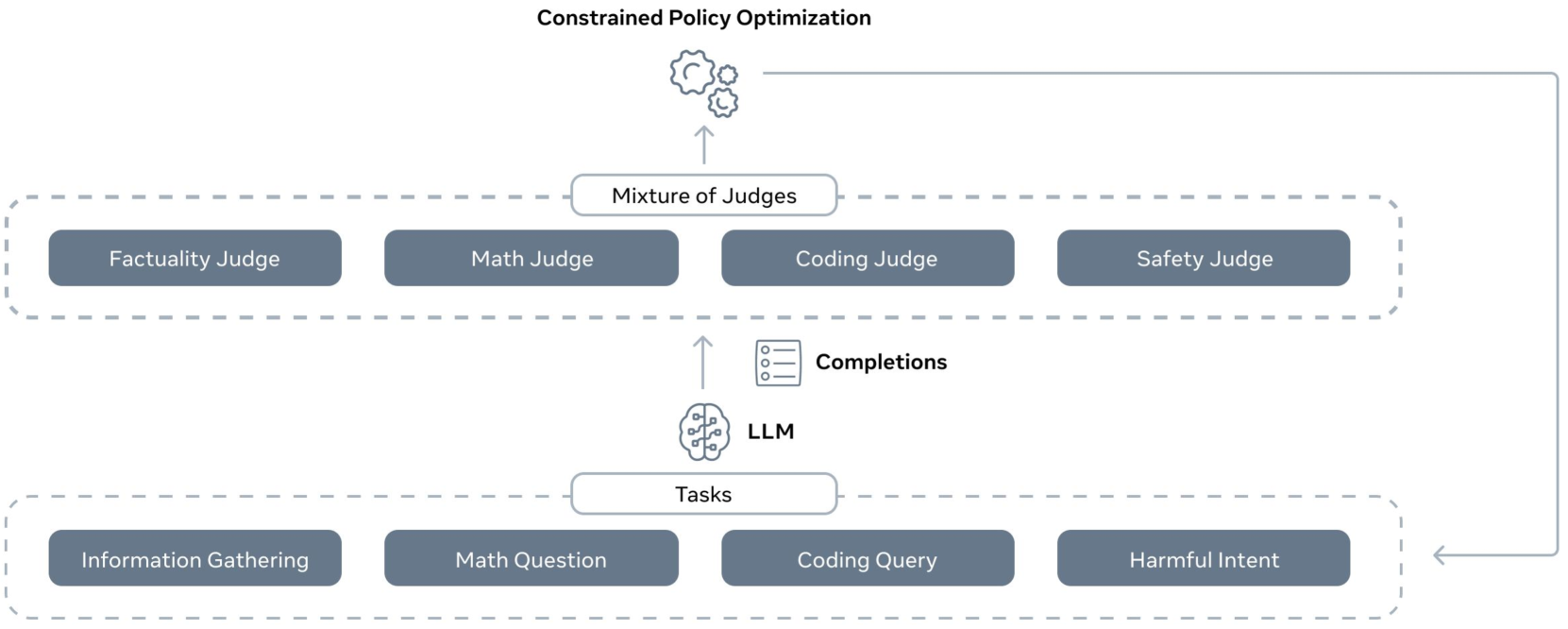
Overview of the CGPO pipeline. It shows the flow from Task-Specific Prompts -> LLM Policy -> Response -> Mixture of Judges (Rule & LLM based) -> Constrained RL Optimizer.
Evaluation Highlights
- +7.4% improvement over PPO on AlpacaEval-2 (General Chat) using the CRRAFT optimizer
- +12.5% improvement over PPO on Arena-Hard (STEM & Reasoning) using the CRRAFT optimizer
- Eliminates reward hacking regression in coding: PPO's HumanEval score drops significantly during training, while CGPO maintains steady improvement (+5% over PPO)
Breakthrough Assessment
8/10
Strong empirical gains across diverse benchmarks and a principled solution to the well-known reward hacking problem. The move from linear reward mixing to constrained optimization is a significant methodological shift.