📝 Paper Summary
Prompt Engineering
Chain-of-Thought Reasoning
Domain-Specific LLM Adaptation
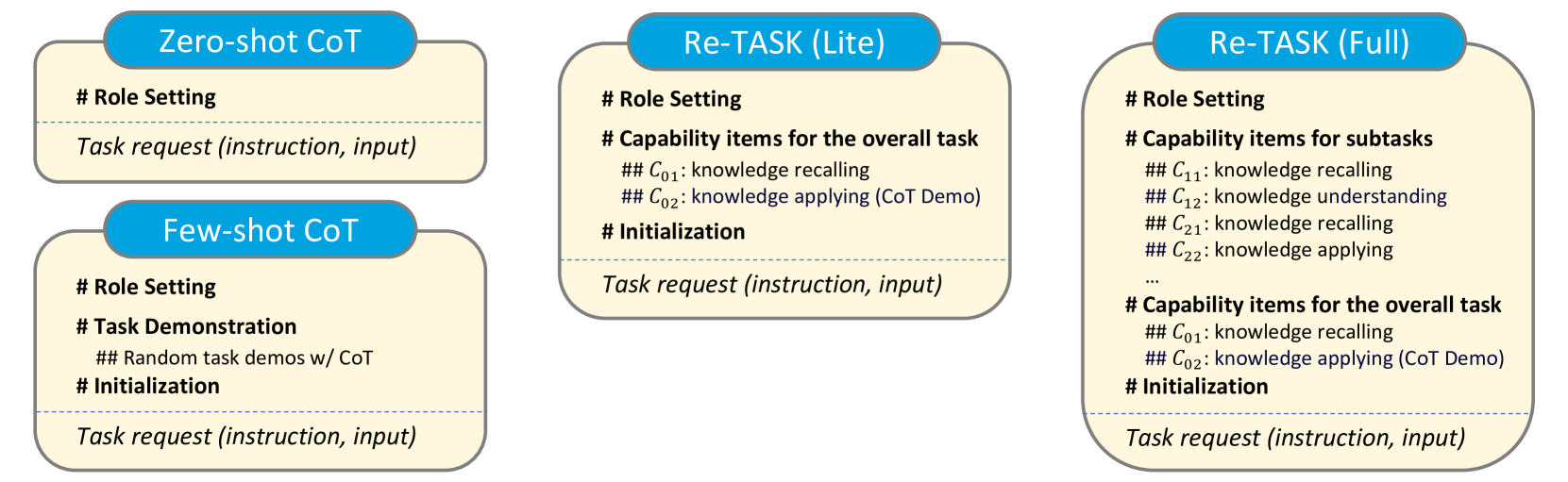
Re-TASK improves LLM reasoning by decomposing tasks into capability items (knowledge and skills) derived from Bloom’s Taxonomy and injecting specific demonstrations for each via in-context learning.
Core Problem
Standard Chain-of-Thought (CoT) fails on domain-specific tasks because LLMs lack necessary domain knowledge or the specific skills to apply that knowledge effectively during subtask decomposition and execution.
Why it matters:
- LLMs struggle with complex reasoning in specialized fields like law and finance despite general capability improvements
- Existing retrieval methods (RAG) inject knowledge but often fail to teach the model *how* to apply that knowledge (skill adaptation)
- Failures in CoT decomposition lead to compounding errors where models cannot execute generated subtasks
Concrete Example:
In a legal sentencing task, a standard CoT model might fail to predict a sentence because it lacks the specific sentencing guidelines (knowledge) or cannot map the victim's injury severity to the guideline criteria (skill). Re-TASK explicitly injects the guideline knowledge and a demonstration of injury assessment before asking for the final sentence.
Key Novelty
Chain-of-Learning (CoL) via Educational Theory Integration
- Re-models LLM tasks using Bloom's Taxonomy and Knowledge Space Theory, viewing tasks as a dependency chain of 'capability items' (specific pairs of knowledge + skills)
- Treats knowledge not just as context but as a 'capability item' (recalling) that must be followed by skill adaptation items (understanding/applying) in the prompt
- Constructs prompts that explicitly sequence these capability demonstrations—retrieving knowledge first, then demonstrating its application—before the model attempts the target task
Architecture
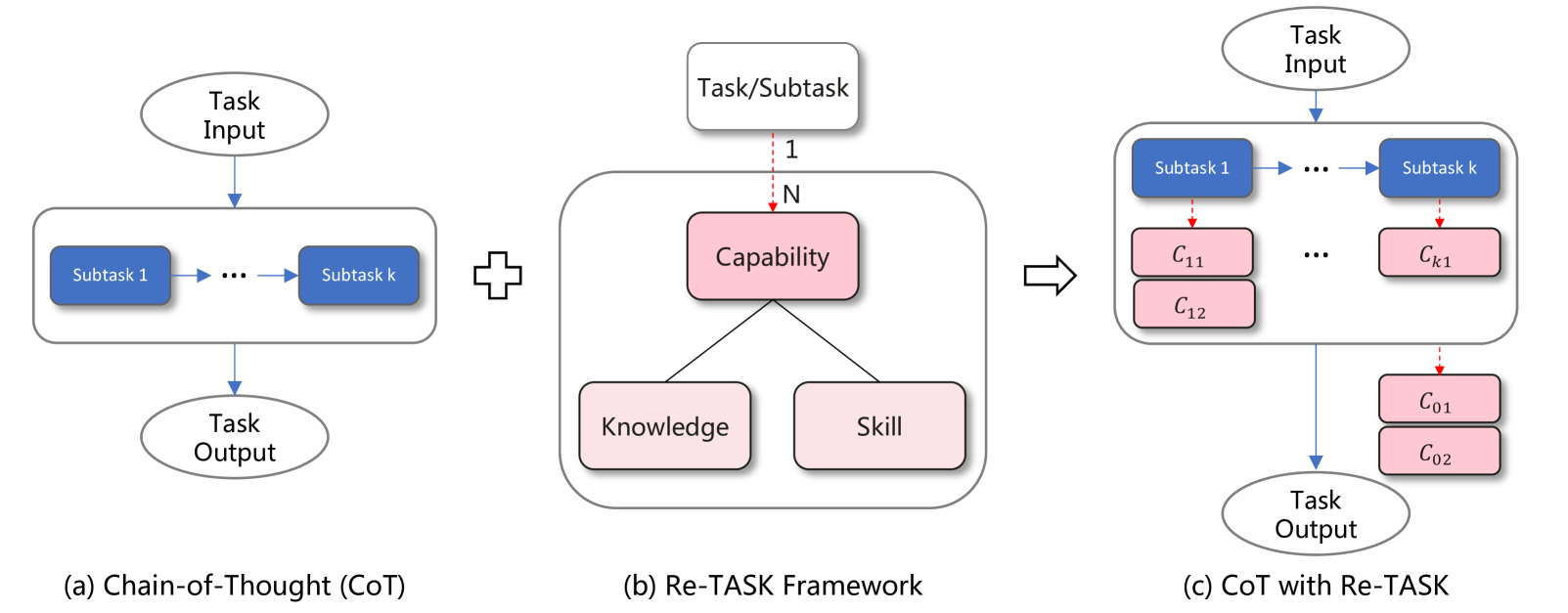
Comparison between Standard CoT and the Re-TASK Framework. Panel (a) shows CoT failing due to lack of capability. Panel (b) shows Re-TASK decomposing the task into Capability Items (Knowledge & Skill). Panel (c) shows the dependency graph of these items.
Evaluation Highlights
- +45.00% improvement on legal tasks using Yi-1.5-9B compared to standard prompting baselines
- +24.50% improvement on legal tasks using Llama3-Chinese-8B
- Significant gains across diverse domains (finance, law, STEM) and multiple languages (Chinese, English), validating the framework's generality
Breakthrough Assessment
7/10
Strong empirical gains in domain-specific tasks by formalizing prompt engineering through educational theory. While primarily a prompting strategy rather than a new architecture, it offers a systematic alternative to standard CoT.